Translaatorite tegemise süsteem (TTS) on mõeldud eeskätt loengukursuse
"Automaadid, keeled ja translaatorid" (MTAT.05.085) omandamise hõlbustamiseks.
Süsteem võimaldab töötada kontekstivabade grammatikatega (KVG): teha
Konstruktori tabeleid ja analüüsida antud grammatikale vastava keele
sõnu. Näideteks on hulk õppegrammatikaid, primitiivse programmeerimis-
keele Trigol grammatika tri.grm ning loogikavalemite keele Form8 gram-
matika (autorid Ahti Peder ja Mati Tombak). Trigol-keelele lisas mõned
uued võimalused Gunnar Kudrjavets. (Vt. trinew.grm.)
Analüsaator on süntaksorienteeritud ning töötab kõigi KV-keelte jaoks
automaatselt. Tri-keele jaoks on süsteemis nii Tri-programmide interp-
retaator kui ka kompilaator; viimasel on kaks varianti: "jõumeetodil"
töötav ja optimeeriv. Tri-programmid transleeritakse assemblerkeelde ja
.exe-faili teevad juba assembler ja linker (TASM ja TLINK).
Süntaksorienteeritud translaatorite teooria on muutunud klassikaks;
möödunud sajandi 70.-80.-ndatel aastatel töötati välja väga palju
erinevaid lahendusi, ja üks neist on meie süsteemi aluseks. Eelnevus-
grammatikate teoreetilise baasi on läbi töötanud ning lisanud sõltuva
konteksti kasutamise analüüsil Mati Tombak.
Käesoleva süsteemi tehniline lahendus, sh. programmid pärinevad
Ain Isotammelt.
TTS on realiseeritud Windows95/NT/2000 keskkonnas, programmeerimiskeeled on C
ja C++.
TTSi ÜLDINE SKEEM
| | Konstruktor |
| |
| Sisend | |
Väljund | |
| xxx.grm, [xxx.sem] | |
xxx.prm, xxx.v, xxx.ht, xxx.pm, xxx.t, xxx.tt, xxx.sm, [xxx.lc], [xxx.rc], [xxx.dc]
|
| | Analüsaator |
| |
| Sisend | |
Väljund |
| yyy.xxx, Konstruktori väljund | |
yyy.prm, yyy.pt, yyy.t, [yyy.it], [yyy.kt] |
| Interpretaator | |
Kompilaator | |
| Sisend |
Väljund |
Sisend |
Väljund |
| Analüsaatori väljund | Lahendamistulemused |
Analüsaatori väljund | yyy.asm, yyy.exe |
TEOORIA
Kontekstivaba grammatika
Kontekstivaba grammatika on järjestatud nelik
KVG=(VN,VT,P,S), kus
VN on mitteterminaalne (mõistete) tähestik,
VT on terminaalne tähestik,
P on produktsioonide hulk kujul A®x (AÎVN, xÎV*) ning
S on fikseeritud täht tähestikust VN — aksioom, mida
ei saa kasutada teiste mõistete defineerimiseks.
V=VNÈVT
V* on tähestiku V baasil moodustatavate sõnade hulk.
VT* on tähestiku VT baasil moodustatavate sõnade hulk.
Vt. näiteks g1.grm. Seal
xÎV*=`B'a
xÎVT*=aab
Terminaalse tähestiku elemente nim. lekseemideks. Need on kõik need kompo-
nendid, millest saab (võib) koosneda süntaktiliselt õige programm:
- reserveeritud sõnad — näiteks IF, THEN, GOTO jne;
- eraldajad — näiteks ; + ( :=
- neli lekseemiklassi, mis kirjeldatakse verbaalselt:
- identifikaatorid (meie süsteemis tähistatakse neid #i#);
- konstandid (#c#);
- stringid (meie süsteemis realiseerimata);
- kommentaarid (meie süsteemis realiseerimata).
Grammatikast antakse Konstruktorile ette ainult produktsioonide hulk P, ta-
valise ASCII-failina (kirjutatud nt. NortonEditor'i või Wordpad'iga). Õppe-
grammatika nimi peab algama 'g'-tähega. Kõikide grammatikate nime laiend on
".grm".Produktsioonide esitamise metakeel on järgmine:
- Mõisted (mitteterminalid) on markerite ` ja ' vahel;
- Lekseemid kirjutatakse ilma markeriteta. Kahe järjestikuse lekseemi vahe-
le tuleb panna tühik;
- Produktsiooni vasema ja parema poole vahel on miinusest ja paremast nurk-
sulust moodustatud "nool": ->;
- Kui ühe mõistet defineeritakse järjestikustel ridadel korduvalt, siis po-
le vasemat poolt vaja kirjutada. Soovitav on kasutada tabulatsiooni.
Näiteid vt. tri.grm või form8.grm. Produktsioonide hulga baasil teeb Konstruktor
hulgad VN ja VT.
Derivatsioon, keel
Olgu x,yÎV*. Ütleme, et x-st on vahetult tuletatav y (xÞy), kui
x=uAv, y=uzv ja A®zÎP; u,z,vÎV*.
Sõnast x on tuletatav sõna y (x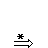 y), kui leidub sõnade jada
z0,z1,¼zk (ziÎV*), selline, et
x=z0,
zi-1,Þzi ja
zk=y (1 £ i £ k).
Naturaalarvu k nimetame derivatsiooni pikkuseks ja jada z0,z1,¼zk
derivatsiooniks.
Olgu antud KVG=(VN,VT,P,S). Tema poolt defineeritud keeleks on hulk
L(G)={x:xG=(VN,VT,P,S) teisendatakse G'=(VN',VT,P',S), kus
L(G)=L(G').
Situatsiooni, kus X ja Y (X,Y ÎV) vahel kehtib üle ühe
eelnevusrelatsiooni, nimetatakse eelnevuskonfliktiks.
Konflikte on kaht tüüpi: P1 ja P2.
P1-konfliktiks nimetatakse situatsiooni, kus
X
y), kui leidub sõnade jada
z0,z1,¼zk (ziÎV*), selline, et
x=z0,
zi-1,Þzi ja
zk=y (1 £ i £ k).
Naturaalarvu k nimetame derivatsiooni pikkuseks ja jada z0,z1,¼zk
derivatsiooniks.
Olgu antud KVG=(VN,VT,P,S). Tema poolt defineeritud keeleks on hulk
L(G)={x:xG=(VN,VT,P,S) teisendatakse G'=(VN',VT,P',S), kus
L(G)=L(G').
Situatsiooni, kus X ja Y (X,Y ÎV) vahel kehtib üle ühe
eelnevusrelatsiooni, nimetatakse eelnevuskonfliktiks.
Konflikte on kaht tüüpi: P1 ja P2.
P1-konfliktiks nimetatakse situatsiooni, kus
X 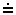
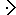 Y, X
Y, X 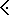 Y või X Y
P2-konfliktiks nimetatakse situatsiooni, kus
X Y
Eelnevusteisendused
Konfliktide likvideerimiseks on iteratiivne algotitm:
Y või X Y
P2-konfliktiks nimetatakse situatsiooni, kus
X Y
Eelnevusteisendused
Konfliktide likvideerimiseks on iteratiivne algotitm:
- S1: Kui P2-konflikte pole, mine S4;
- S2: Iga P2-konflikti jaoks (X,Y):
- Leia A®xXYy
- Produktsioon asendatakse produktsiooniga A®xXDi
- Lisatakse uus produktsioon Di®Yy
- S3: Tee uus eelnevusmaatriks ja mine S1;
- S4: Kui P1-konflikte pole, STOPP;
- S5: Iga P1-konflikti jaoks (X,Z):
- Leia A®xXZy või A®xXYy, et ZÎL(Y).
- Produktsioon asendatakse produktsiooniga A®DiZy või A®DiYy
- Lisatakse uus produktsioon Di®xX
S6: Tee uus eelnevusmaatriks ja konfliktide korral mine S1, muidu STOPP;
(Vt. näiteks g9.htm
Füüsilisel tasemel kodeeritakse eelnevusrelatsioone järgmiselt (bin):
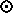 000
001
010
100
011
101
110
111 )
000
001
010
100
011
101
110
111 )
Pööratavate EG analüsaator
Lausevormi baas.
Kui G on eelnevusgrammatika G=(VN,VT,P,S) ja
S 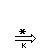 X1,X2,...,XkAY1,...,Yl
X1,X2,...,XkAY1,...,Yl X1,X2,...,XkZ1,...,ZmY1,...,Yl,
kus Xi,ZjÎV, YhÎVT
(i=1..k, j=1..m ja h=1..l), siis jada Z1,...,Zm on lausevormi baas
(viimasena toimis produktsioon A®Z1,...,Zm), ja kehtivad relatsioonid
XiXi+1ÚXiXi+1 (i=1..k-1);
XkZ1;
ZjZj+1 (j=1..m-1);
ZmY1.
Kui kontekstivaba grammatika G produktsioonide hulgas ei leidu ühesuguse parema
poolega produktsioone, siis nimetatakse grammatikat G pööratavaks grammatikaks.
Pööratavate eelnevusgrammatikate analüsaator.
Pööratavate eelnevusgrammatikate analüsaatori algoritm on järgmine:
Analüüsitav sõna on lekseemide massiiv T[0..n] (T0=Tn='#');
M on kolmetraktiline magasin (LIFO-tüüpi):
esimene trakt on sümbolite, teine relatsioonide ja kolmas analüüsipuu
viitade jaoks.
X1,X2,...,XkZ1,...,ZmY1,...,Yl,
kus Xi,ZjÎV, YhÎVT
(i=1..k, j=1..m ja h=1..l), siis jada Z1,...,Zm on lausevormi baas
(viimasena toimis produktsioon A®Z1,...,Zm), ja kehtivad relatsioonid
XiXi+1ÚXiXi+1 (i=1..k-1);
XkZ1;
ZjZj+1 (j=1..m-1);
ZmY1.
Kui kontekstivaba grammatika G produktsioonide hulgas ei leidu ühesuguse parema
poolega produktsioone, siis nimetatakse grammatikat G pööratavaks grammatikaks.
Pööratavate eelnevusgrammatikate analüsaator.
Pööratavate eelnevusgrammatikate analüsaatori algoritm on järgmine:
Analüüsitav sõna on lekseemide massiiv T[0..n] (T0=Tn='#');
M on kolmetraktiline magasin (LIFO-tüüpi):
esimene trakt on sümbolite, teine relatsioonide ja kolmas analüüsipuu
viitade jaoks.
- S1: M:='#'; i:=1
- S2: Kui relatsioon  M ja Ti vahel
- MTi on viga: STOPP
- MTi:
- S3: P:=uus analüüsipuu tipp; M:=Ti,Â,P; i:=i+1; mine S2
- MTi:
- Kui Ti='#', siis STOPP; muidu mine S3
- MTi:
- Detekteerimine: x=lausevormi baas (M sisu tipust kuni
relatsioonini )
- Redutseerimine: kui $ produktsioon A®x, jatka;
muidu viga: STOPP
- Tee analüüsipuu uus tipp P, ühenda x-i kuuluvate tippude
viidad ahelasse ja ahela 1. lüli tee P alluvaks;
eemalda x magasinist (M tipus on x-le eelnev sümbol),x asemel A
(ja relatsioon M ja A vahel ning P) magasini M, mine S2
(Näiteks vt. keele L(g1) sõna a1.g1 analüüsi)
Konteksti kasutamine redutseerimiseks ja vastav analüsaator
Söltumatu kontekst.
Kui produktsioonide hulgas on kaks produktsiooni kujul A®x ja B®x,
siis tekkib redutseerimisprobleem: kas analüüsil tuleb asendada
lausevormi baas x mitteterminali A või B-ga. Sel juhul tuleb
kasutada mitteterminali piiratud kanoonilist konteksti BRC(1,1):
analüüsisammu määravad üheselt lausevormi baas x, 1 sümbol
vasakult ja üks sümbol paremalt (BRC on akronüüm i.k. terminist
Bounded Right Context).
Kui S X1,X2,...,XkAY1,...,YlX1,X2,...,XkZ1,...,ZmY1,...,Yl (YiÎVT), siis:
XkAÚXkA ja
AY1ÚAY1ÚAY1
Moodustatakse mitteterminali A vasaku ja parema konteksti hulgad LC(A) ja RC(A):
LC(A)={X:[XAÚXA]&XÎV}
RC(A)={X:[AXÚAXÚAX]&XÎVT}
C1|1=LC(A)´ RC(A).
Hulk C1|1(A) on mitteterminali A (1,1)-sõltumatu kanooniline kontekst
Kui A®x ja B®x ning kehtib C1|1(A)ÇC1|1(B)=Æ,
siis ütleme, et G on 1|1-redutseeritav eelnevusgrammatika.
BRC(1,1) analüsaator.
Analüüsitav sõna on lekseemide massiiv T[0..n];
M on kolmetraktiline magasin (LIFO-tüüpi):
esimene trakt on sümbolite, teine relatsioonide ja kolmas analüüsipuu
viitade jaoks.
- S1: M:='#'; i:=1
- S2: Kui relatsioon  M ja Ti vahel
- puudub, on viga: STOPP
- MTi:
- P:=uus analüüsipuu tipp; M:=Ti,Â,P; i:=i+1; mine S2
- MTi:
- Kui Ti='#', STOPP; muidu mine S3
- MTi:
- S3: Detekteerimine: x=lausevormi baas (M sisu tipust kuni
relatsioonini )
- Redutseerimine: kui $ produktsioon A®x, jatka; muidu viga: STOPP
- Kui on ainult 1 selline produktsioon, mine S4
- L:=M-1; kas on mitu produktsiooni, kus LC(A)=L? Ei: mine S4
R:=Ti; A:=see Ai®x, mille RC(Ai=R);
- S4: Tee analüüsipuu uus tipp P, ühenda x-i kuuluvate tippude
viidad ahelasse ja ahela 1. lüli tee P alluvaks;
eemalda x magasinist (M tipus on x-le eelnev sümbol),x asemel A
(ja relatsioon M ja A vahel ning P) magasini M, mine S2
Derivatsioonist sõltuv kontekst
Kui A®x ja B®x ning kehtib C1|1(A)ÇC1|1(B)¹Æ,
siis G pole 1|1-redutseeritav eelnevusgrammatika ning paljudel juhtudel aitab
derivatsioonist sõltuv kontekst (BRC(1|1) nim. ka sõltumatuks kontekstiks,
kuivõrd kontekst leitakse eelnevusmaatriksist sõltumatult derivatsioonist.)
Näiteks vt.g8.grm, kus A ja B sõltumatu kontekst kattub
täielikult: C1|1(A)=C1|1(B)={(a,a),(a,b),(b,a),(b,b)}.
Ent keeles L(g8) on ainult 4 sõna:
S Þ a A a Þ a 1 a
S Þ b A b Þ b 1 b
S Þ a B b Þ a 1 b
S Þ b A a Þ b 1 a
ja näeme, et A kontekst on {(a,a),(b,b)} ning
B kontekst on {(a,b),(b,a)}
Derivatsioonist sõltuv kontekst on defineeritud järgmiselt:
LC(A)={X:SuXAv}
RC(A)={T:SuATv & TvÎVT*}
C1,1(A)={(X,T):SuXATv & TvÎVT*}
C1,1(A) arvutuseeskiri on järgmine:
C1,1(A)=g1(A)Èg2(A)Èg3(A)Èg4(A);
g1(A)={(X,T):B®uXADvÎP&[T=DÚTÎL(D)]}
g2(A)={(X,T):B®uXAÎP&TÎRC(B)}
g3(A)={(X,T):B®ADvÎP&XÎLC(B)&[T=DÚTÎL(D)]}
g4(A)={(X,T):B®AÎP&(X,T)ÎC1,1(B)}
Kui A®x ja B®x ning kehtib C1,1(A)ÇC1,1(B)=Æ,
siis ütleme, et G on 1,1-redutseeritav eelnevusgrammatika.
Analüüsi põhimõtteline algoritm on sama, mis 1|1-redutseeritava
grammatika jaoks.
Näiteks vt. keele L(g8) sõna y.g8 analüüsi.
Grammatika g4.grm pole redutseeritav (vt. g4.htm).
Konteksti juurdetoomine
Kui sõltuv kontekst ei eristu, siis on paratamatu inimese sekkumine: pole teada
algoritmi, millega saaks garanteeritult grammatikat nii teisendada, et ta oleks
redutseeritav. Translaatori tegijale soovitatakse võimaluse korral juurde tuua
vasakut konteksti ja kui see pole võimalik, siis tuleb muuta keelt.
Vaatame, millest on tingitud grammatika g4.grm konteksti eristamatus.
Teeme kaks derivatsiooni:
T Þ # S # Þ # a A # Þ # a 0 A 1 #
T Þ # S # Þ # b B # Þ # b 0 B 1 1 #
Püüame juurde tuua erineva vasaku konteksti, asendades kaks produktsiooni:
produktsioon `A'®0 `A' 1 produktsiooniga `A'®`C'`A'1 ja
produktsioon `B'®0 `B' 1 1 produktsiooniga `B'®`D'`B'1 1
ja lisades kaks uut produktsiooni:
`C'®0
`D'®0
Selliselt parandatud grammatika on g41.grm ja et asi õnnestus,
demonstreerib g41.htm.
Analüüsi puu moodustamise juhtimine. Analüsaatori lõplik algoritm.
Analüüsi puu liiasus.
Vajadus analüüsi puu moodustamise juhtimiseks tuleneb sellest, et
analüsaator teeb liiase puu. Näiteks Tri teeb
derivatsiooni sõnani
y:=a+1
järgmiselt (loobume mitteterminalide apostroofidest ja sõna
ümbritsevatest markeritest):
programm Þ programm12 Þ operaatorid Þ operaator Þ omistamine Þ
Þ muutuja:=omistamine1 Þ muutuja:=aritmav Þ
Þ muutuja:=aritmav+aritmav2 Þ muutuja:=aritmav+yksliige Þ
Þ muutuja:=aritmav+tegur Þ muutuja:=aritmav+1 Þ
Þ muutuja:=yksliige+1 Þ muutuja:=tegur+1 Þ muutuja:=a+1 Þ y:=a+1
Analüüsi puu (esitame keskjärjekorras läbituna) on järgmine:
programm(programm12)
programm12(operaatorid)
operaatorid(operaator)
operaator(omistamine)
omistamine(muutuja := omistamine1)
muutuja(y)
y(Æ)
omistamine1(aritmav)
aritmav(yksliige)
aritmav(aritmav + aritmav2)
yksliige(tegur)
tegur(a)
a(Æ)
aritmav2(yksliige)
yksliige(tegur)
tegur(1)
1(Æ)
Vaja on aga sellist puud:
programm(omistamine)
omistamine(y aritmav)
y(Æ)
aritmav(a 1)
a(Æ)
1(Æ)
Semantilised muutujad.
Puu moodustamist juhitakse semantiliste muutujate abil ¾ need
on naturaalarvud s (s>0), mis seotakse lihtsa keele abil kas
produktsioonide või terminaalse tähestiku sümbolitega. Semantika
esitatakse lihtsa ASCII-failina, mille nimeks on xxx.sem (grammatikale
xxx.grm). Näidet vt.Tri.sem. Vaatame sealt nt. kaht rida:
4=1 $ #i#
p13=10 $ omistamine->muutuja:=omistamine1
#i# järjekorranumber tähestikus V on 4 (seda on hõlpus leida
Konstruktori protokolli Tri.htm osast "Terminal alphabet") ning
identifikaatorite semantika s#i#:=1. Märgiga "$" algav
reaosa on fakultatiivne; see on mõeldud semantikafaili lugemise
hõlbustamiseks.
Produktsiooni "omistamine->muutuja:=omistamine1" järjekorranumber
produktsioonide hulgas P on 13 (vt. Konstruktori protokolli Tri.htm
osa "Productions") ja tema semantika sP13:=10.
Semantikafaili töötleb Konstruktor. Kui xxx.sem pole ette antud,
siis Konstruktor genereerib selle ise, omistades semantika kõigile
terminalidele ja kõigile produktsioonidele (soovitada võibki uue
grammatika puhul nii teha ¾ Konstruktor teeb veatu ja kommenteeritud
tekstifaili ja sellega on lihtne manipuleerida, elimineerides mittevajaliku
semantika vastava rea kommentaariks muutmisega, lisades rea algusse '$').
Analüsaatori lõplik algoritm.
Analüüsitav sõna on lekseemide massiiv T[0..n] ("TiÎVT, 1£i£n);
M on kolmetraktiline magasin (LIFO-tüüpi):
MS on sümbolite,
MR relatsioonide ja
MV analüüsipuu viitade jaoks.
- S1: MS:=T0; i:=1
- S2: Kui relatsioon  MS ja Ti vahel
- puudub, on viga: STOPP
- MS Ti:
- kui sTi>0: MV:=uus analüüsi puu tipp, muidu MV:=Æ;
MS:=Ti; MR:=Â; i:=i+1; mine S2
- MS Ti:
- Kui Ti='#', STOPP; muidu mine S3
- MS Ti:
- Detekteerimine: x=lausevormi baas (MS sisu tipust kuni
relatsioonini )
- Redutseerimine: kui $ produktsioon A®x, jatka; muidu viga: STOPP
- Kui on ainult 1 selline produktsioon, mine S4
- L:=MS-1; kas on mitu mitteterminali Ai, kus LC(Ai)=L? Ei: mine S4
A:=see Ai®x, mille RC(Ai=Ti);
- S4: Läbi lausevormi baasile vastav osa MV-st vasakult paremale
ja ühenda viidatud tipud omavahel ahelasse (kui tipul on naabrid,
siis ühenda ka need), P:=viit ahela esimesele lülile. Võib juhtuda,
et P=Æ.Eemalda x magasinist; MS:=A. MR:=MS-1 Â Ti.
- Kui sA®x>0, siis
N:=uus analüüsi puu tipp; MV:=N; N-i alluv:=P.
- Kui sA®x=0, siis MV:=P;
- S3:: i:=i+1; kui i≤n, siis mine S2.
Konstruktori üldine skeem
Konstruktori lähteandmeteks on keele xxx produktsioonide hulk xxx.grm ja
fakultatiivselt xxx semantikafail xxx.sem. Käsurealt käivitatuna:
wcr32 xxx
- S1: Moodusta KVG xxx.grm baasil terminaalne ja mitteterminaalne tähestik
VT ja VN;
- S2: Moodusta "AÎVN jaoks hulgad L(A) ja R(A);
- Koosta (n´n)-maatriks PM (n=tähestiku V pikkus + 1) ja
kanna sinna kõik V sümbolite vahelised eelnevusrelatsioonid.
PM on eelnevusmaatriks;
- Kas xxx on eelnevusgrammatika?
- Kas xxx on pööratav eelnevusgrammatika?
- Moodusta sõltumatu konteksti hulgad maatriksitena LC ja RC;
LC mõõtmed on l´n ja RC-l l´m (l on tähestiku VN pikkus ja m tähestiku VT
pikkus);
- Kas sõltumatu kontekst eristub?
- Kui jah, siis kirjuta kettale xxx.lc ja xxx.rc; mine S3 ;
- Moodusta sõltuva konteksti hulgad nende mitteterminalide jaoks, mille
sõltumatu kontekst ei eristu;
- Kas sõltuv kontekst eristub?
- Kui jah, siis siis kirjuta kettale xxx.lc, xxx.rc ja xxx.dc; mine S3 ;
- Kirjuta kettale xxx.htm (Konstruktori logi) ja
välju Konstruktorist. Püüa käsitsi juurde tuua vasakut konteksti
(so., paranda grammatikat) ja alusta S1-st;
- S3: Kas kettal on semantikafail xxx.sem?
- Kui ei, siis genereeri tekstifail xxx.sem;
- Tee parameetrite tabel xxx.prm ja semantikatabel xxx.sm; kirjuta kettale
xxx.prm, xxx.sm, xxx.v (tähestiku V puu), xxx.ht (redutseerimistabel),
xxx.t (tähestik V), xxx.tt (skanneri tabel), xxx.htm (Konstruktori logi)
ja xxxrd.htm (Konstruktori tabelid ¾ vt. nt. g8rd.htm). Välju
Konstruktorist.
REALISATSIOON
Allpool esitame algoritme loodetavasti üldarusaadavas metakeeles;
märgendid on punased:, viidad on sinised ja C-keelsed moodulid (või
operaatorid) rohelised.
Konstruktor (Constructor)
Konstruktor käivitatakse käsurealt
wcr32 <grammatika> ¾ nt. wcr32 tri
- muutujad:
- int pre,i; char *Ti
- int ret:=1; olek:=0; Pnr:=1; Index:=1
- DT=(struct D *)NULL; // first
- DC=(struct D *)NULL; // current
- DL=(struct D *)NULL; // last
- DN=(struct D *)NULL; // new
- context:=0; // independent context
- dc:=0; // dependent context
- tnr:=0; // current length of the terminal alphabet
- nr:=0; // current length of the alphabet V
- NR:=0; // current nr in time of precedence varies
- BRC:=0; // the number of the Productions with the same right-sides
- Konstruktor sisestab faili xxx.grm (xxx on grammatika nimi)
- // terminaalse tähestiku moodustamine
- kui Terms()=1, siis ret:=0 ja mine bye
- nr:=tnr
- // mitteterminaalse tähestiku ja produktsioonide hulga moodustamine
- kui Rules()=1, siis ret:=0 ja mine bye
- // left- ja rightmost-hulkade moodustamine, eelnevusmaatriksi koostamine
- new:
- memset(Pm,'\0',HTL*HTL); //HTL on konstant "Hash Table Length"
- memset(Lm,'\0',HTL*HTL);
- memset(Rm,'\0',HTL*HTL);
- make_LRB()
- pre:=make_PM()
- kui pre=1, siis mine on
- // eelnevustest ja eelnevusteisendused
- kui conflicts()>0, siis mine new
- on:
- logisse teade Grammar is a precedence grammar
- // produktsioonide paisktabeli moodustamine
- HashRules(DT)
- // produktsioonide vektori mälueraldus
- DepV:=DefVect(Pnr)
- kui BRC=0, siis
- logisse teade Grammar is invertible
- context:=0; mine semm
- logisse teade Grammar is not invertible
- context:=1
- // sõltumatu konteksti hulkade moodustamine, BRC(1|1)-test
- kui LC≠Æ free(LC); LC:=DefArray(nr+1)
- kui RC≠Æ free(RC); RC:=DefArray(nr+1)
- // sõltumatu konteksti maatriksite täitmine
- make_all_indep()
- // produktsioonide vektori moodustamine
- make_prod();
- dc:=0
- // sõltumatu konteksti eristuvuse test ja (vajadusel) sõltuva konteksti
arvutamine
- kui make_BRC()=0, siis mine sos
- kui BRC=0 & dep=0, siis
- logisse teade Grammar is BRC(1|1)-reducible
- mine semm
- kui dc=1, siis
- logisse teade Grammar is BRC(1,1)-reducible
- // mittevajalike sõltuva konteksti vektorite kustutamine
- del_dep(); mine semm
- sos:
- logisse teade Grammar is not BRC-reducible
- STOPP
- // semantika omistamine
- semm:
- put_semant(); Sn=nr
- // konstruktori tabelite kirjutamine kettale
- w_tabs();
- // .htm-faili "real data structures" moodustamine
- make_rtf(); -- moodul kirjutab kettale faili xxxrd.htm (vt. nt. trird.htm)
- STOPP
Grammatika salvestamine
Konstruktorile antakse ette KV grammatika (KVG=(VN,VT,P,S)) produktsioonide
hulk P ja sellest tehakse kaks andmestruktuuri: tähestiku V vektor T ja
grammatika otsimis-kahendpuu, kus võtmeteks on T elemendid.
T on defineeritud järgmiselt:
char T[2*HTL][20]; // tähestiku V sümbolid
#define HTL 256 // Hash Table Length
Iga sümboli x (xÎV) jaoks tehakse järgmise kirjeldusega grammatika
otsimis-kahendpuu tipp (võti on Tcode):
struct D{
int tunnus; // 0: xÎVN, 1: xÎVT
int code; // vahekeelne kood
int L; // x pikkus
int loc; // reservis
int icx; // reservis
struct D *left; // kahendpuu viidad: vasakule alluvale
struct D *right; // paremale alluvale
struct R *def; // mitteterminal (NT xÎVN): vahekeelne definitsioon
};
// Produktsiooni parem pool (Pp: A®X1...Xn)
struct R{
int P; // produktsiooni jrk-nr p
int sem; // semantikakood
int n; // NT definitsiooni pikkus n
int *d; // NT definitsioon: X1...Xn koodid (n≥1)
struct R *alt; // NT alternatiivne definitsioon (ahel)
};
Puu juur on defineeritud nii:
struct D *DT; // root
Grammatika puu moodustatakse järgmise põhimõttelise algoritmi järgi:
- Produktsioonid P1...PmÎP
- terminaalse tähestiku pikkus tnr:=0; p:=1 (1≤p≤m)
- Grammatika G puu tippudega Ds:=Æ (1≤s≤L; L=V pikkus; V=VNÈVT)
- Terms() //täpset algoritmi vaata siit
- S1: Pp=A®X1...Xn; i:=1
- S1.1: Kui XiÎVT
- Kui $ tipp DXi, mine S1.2
- lisa puusse tipp DXi; tnr:=tnr+1; DXi->code:=tnr; Ttnr:=Xi
- S1.2: i:=i+1; kui i≤n, mine S1.1
- S1.3: p:=p+1; kui p≤m, mine S1
- Rules() //täpset algoritmi vaata siit
- S2: p:=1; nr:=tnr;
- S3: Pp=A®X1...Xn; i:=1
- S3.1:
R:= uus definitsioonikirje (kirjeldus struct R)
- Kui $ tipp DA, mine S3.2
- lisa puusse tipp DA; nr:=nr+1; DA->code:=nr; Tnr:=A
- S3.2: i:=1; deklareeri vektor d[1..n]
- S3.2.1: Kui XiÎVT, siis
- S3.2.1.1: di:=DXi->code; mine S3.3
- S3.2.2:
- XiÎVN. Kui $ tipp DXi, mine S3.2.1.1
- lisa puusse tipp DXi; nr:=nr+1; DXi->code:=nr; Tnr:=Xi
- di:=nr
- S3.2.3: i:=i+1; kui i≤n mine S3.2.1
-
- S3.3: Kui DA->def≠Æ, siis R->alt:=DA->def;
R->P:=p; R->d:=d; R->n:=n; DA->def:=R
- S3.4: p:=p+1; kui p≤m. mine S3;
- S4: Pnr:=p-1; STOPP; (Pnr=produktsioonide arv)
Kommentaar: Alustame puusse paigutamist tähestiku VT elementidest, kuivõrd nende
arv on konstantne. Mitteterminaalse tähestiku elemente lisandub eelnevus-
teisenduste käigus. Realisatsiooni huvides on oluline teada, kas V sümbol on
terminaalse või mitteterminaalse tähestiku sümbol
(nüüd " xÎVT kood < xÎVN kood).
Eelnevusmaatriksi moodustamine
Andmestruktuurid on järgmised:
char Pm[HTL][HTL]; // Konstruktori eelnevusmaatriks
//(välja kirjutatakse n´n-maatriks; n=nr+1)
char Lm[HTL][HTL]; // leftmost-maatriks
char Rm[HTL][HTL]; // rightmost-maatriks
L(A)- ja R(A)-maatriksid (Lm ja Rm) on liiased: esimese vajalik suurus oleks
((nr+1)-tnr)´(nr+1) ja teisel ((nr+1)-tnr)´(tnr+1).
Liiasus on tingitud adresseerimise lihtsustamisest; rea- ja veeruindeksid on
tähestiku V sümbolite vahekeelsed koodid. Konstruktori logifailis xxx.htm
näidatakse mitteliiaseid maatrikseid.
Mõlemad maatriksid moodustatakse kahe läbivaatusega: esimese käigus
paigutatakse vastavatesse maatriksitesse AiÎVN definitsioonide
algus- ja lõpusümbolid (Nt. kui Ai kood on 44 ja tema L(Ai)-hulka
kuulub sümbol koodiga 17, siis Lm44,17:=1.
Teise läbivaatuse käigus lisatakse maatriksitesse L(A) ja R(A) kuuluvate
mitteterminalide L- ja R-hulgad. Näiteks kui Lm44,51=1, siis
Lm 44. ritta kantakse kõik 51. rea nullist erinevad elemendid.
Eelnevusmaatriks täidetakse vastavalt eelnevusrelatsioonide definitsioonidele.
Kood kirjutatakse maatriksisse, kasutades loogilise liitmise tehet:
PMi,j:=PMi,jÚÂ
Kui pärast relatsiooni maatriksissekandmist PMi,j≠{000, 001, 002,004},
siis lipp dep:=dep+1: G≠eelnevusgrammatika (dep algväärtus on 0).
Eelnevusteisendused
Eelnevusteisenduste põhimõtteline algoritm on järgmine:
- NR:=nr; Index:=0; res:=0;
- S1: i:=1;
- S1.1: j:=1;
- S1.1.1: kui PMi,j=3, siis res:=1; P2(i,j);
- j:=j+1; kui j≤nr, mine S1.1.1;
- i:=i+1; kui i≤nr, mine S1.1;
- kui res=0, mine S2;
- nr:=NR; nulli Lm- ja Rm-maatriksid, täida nad uuesti,
- trüki uus hulk L(A) logisse
- S2: i:=1;
- S2.1: j:=1;
- S2.1.1: kui PMi,j>4, siis res:=1; P1(i,j);
- j:=j+1; kui j≤nr, mine S1.1.1;
- i:=i+1; kui i≤nr, mine S1.1;
- nr:=NR;
Alamprogrammi P2(x,y) algoritm:
- muutujad: struct D *t ja struct R *d;
- S1: i:=tnr+1;
- S1.1: t:=grammatika puu tipp võtmega Ti; d:=t->def
- S1.1.1: kui d=Æ, siis mine S1.2
- j:=0
- S1.1.1.1: kui d->dj=x ja d->dj+1=y, siis s_to_right(j+1,t,d);
- j:=j+1; kui j<d->n-1, mine S1.1.1.1
- d:=d->alt; mine S1.1.1
- S1.2: i:=i+1; kui i≤nr, mine S1.1;
Alamprogrammi P1(x,y) algoritm:
- muutujad: struct D *t ja struct R *d;
- S1: i:=tnr+1;
- S1.1: t:=grammatika puu tipp võtmega Ti; d:=t->def
- S1.1.1: kui d=Æ, siis mine S1.2
- j:=0
- S1.1.1.1: kui d->dj=x ja d->dj+1=y või
- d->dj+1>tnr ja Lmd->dj+1,y=1, siis
- s_to_left(j+1,t,d);
- j:=j+1; kui j<d->n-1, mine S1.1.1.1
- d:=d->alt; mine S1.1.1
- S1.2: i:=i+1; kui i≤nr, mine S1.1;
Alamprogrammi s_to_right(int lim, struct D *t, struct R *d) algoritm:
- muutujad: struct D *DC ja struct R *b;
- eralda mälu DC-le ja b-le
- NR:=NR+1; Index:=Index+1; TNR:=Tt->code suffiksiga Index
- r:=d->n - lim; tee vektor Z r arvu jaoks
- b->d:=Z; kanna vektori d->d elemendid indeksitega lim...d->n-1
- vektorisse Z indeksitega 0...r-1
- b->n:=r; DC->def:=b; DC->code:=NR; DC->tunnus:=0; DC->L:=t->L+1;
- b->P:=Pnr; Pnr:=Pnr+1; lisa tipp DC grammatika puusse
- r:=lim+1; tee vektor Z r arvu jaoks; kanna sinna lim arvu
- vektorist d->d ning viimaseks elemendiks lisa NR
- d->n:=lim+1; d->d:=Z
Alamprogrammi s_to_left(int lim, struct D *t, struct R *d) algoritm:
- muutujad: struct D *DC ja struct R *b;
- eralda mälu DC-le ja b-le
- NR:=NR+1; Index:=Index+1; TNR:=Tt->code suffiksiga Index
- tee vektor Z lim+1 arvu jaoks
- b->d:=Z; kanna vektori d->d lim esimest elementi vektorisse Z
- b->n:=lim; DC->def:=b; DC->code:=NR; DC->tunnus:=0; DC->L:=t->L+1;
- b->P:=Pnr; Pnr:=Pnr+1; lisa tipp DC grammatika puusse
- r:=d->n - lim; tee vektor Z r arvu jaoks; kanna sinna esimeseks elemendiks
- NR ja järgmisteks vektori d->d elemendid indeksitega lim kuni lõpuni
- d->n:=lim+1; d->d:=Z
Sõltumatu konteksti hulkade moodustamine
make_all_indep(void)
- i:=1
- S1: brc(i);
- i:=i+1; kui i≤nr, siis mine S1
mitteterminali sõltumatu konteksti hulga moodustamine
brc(int A)
- i:=1
- S1: kui Pmi,A=1ÚPmi,A=2, siis LCA,i:=1
- i:=i+1; kui i≤nr, siis mine S1
- i:=1
- S2: kui PmA,i>0, siis RCA,i:=1
- i:=i+1; kui i≤tnr, siis mine S2
- STOPP
Redutseerimistabel
Redutseerimistabel (kettal xxx.ht) on paisktabel kirjeldusega
struct h *HT[HTL]; // hashtabel, kus struktuur h on kirjeldatud järgmiselt:
// Produktsioonide paremate poolte järgi paisatud tabeli kirje
struct h{
int P; // produktsiooni jrk-nr
int n; // definitsiooni pikkus
int NT; // defineeritav mitteterminal
int *d; // definitsioon ¾ kirje vahekeelne võti
int nc; // 1 - sõltuv kontekst
char *c; // reservis
struct h *same; // sama parem pool
struct h *col; // põrkeviit
};
Algoritmid:
1) Kõikide mitteterminalide definitsioonide salvestamine.
Ette antakse grammatika puu juur. Globaalne muutuja BRC:=0
(kui BRC>0, siis pole grammatika pööratav).
2) Mitteterminali definitsioonide salvestamine.
3) Produktsiooni paiskamine
- HashRule(struct D *t,struct R *r)
- muutujad struct h *L,*TP,*S
- eralda L-le mälu; L->col:=Æ; L->same:=Æ
- eralda mälu r->n arvule, aadress kirjuta L->d-sse
- kopeeri vektor r->d L->s-sse; L->n:=r->n; L->NT:=t->code;
L->P:=r->P
- a:=hfunc(L->n, L->d); kui a≠Æ, mine Y
- HTa:=L; STOPP
- Y: TP:=HTa;
- Viit: kui TP=Æ, siis mine E
- Kui L->n=TP->n ja vektor L->d ≠ vektor TP->d, mine col
- Kui L->n=TP->n ja vektor L->d = vektor TP->d, siis
- S:=TP->same; TP->same:=L; L->same:=S; BRC:=BRC+1; STOPP;
- col: TP:=TP->col; mine Viit
- E: TP:=HTa; HTa:=L; L->col:=TP; STOPP
4) Paiskfunktsioon (võti on produktsiooni vahekeelne parem pool)
- int hfunc(int keylen,int *key)
- muutuja int h=0
- i:=0
- Ring: h:=hÅkeyi (tehe Å on loogiline mittesamaväärtsustamine)
- i:=i+1; kui i≤keylen, mine Ring
- g:=h; h:=h/HTL; h:=g-(h*HTL);
- return(h);
Sõltumatu konteksti hulkade moodustamine
- i:=tnr+1;
- S1: j:=1;
- S2: kui Pmj,i=1ÚPmj,i=2, siis LCi,j:=1
- j:=j+1; kui j≤nr, mine S2
- j:=1
- S3: kui Pmi,j≠0, siis RCi,j:=1
- j:=j+1; kui j≤tnr, mine S3
- i:=i+1; kui i≤nr, mine S1;
Sõltuva konteksti hulkade moodustamine
Sõltuva konteksti talletamiseks kasutatakse järgmist andmestruktuuri:
(mälu eraldab moodul defDEP) Ülemise taseme moodustab vektor DEP[0...nr]; DEPi=Æ,
kui mitteterminali Vi (tnr>i≤nr) sõltumatu kontekst eristub, ja viit
vektorile Li indeksitega 0...nr vastupidisel juhul. Li,j=Æ, kui
sümbol Vj ei kuulu mitteterminali Vi vasaku konteksti hulka, vastasel korral
Li,j on viit vektorile rc indeksitega 0...tnr; rck=1, kui terminal Vk kuulub
mitteterminali Vi parema konteksti hulka; kui ei kuulu, siis rck=0.
Vektorile L eraldab mälu moodul defL() ning vektorile rc moodul DefVect(tnr+1).
(n´n-maatriksile eraldab mälu moodul DefArray(n).)
(Sõltuva konteksti andmestruktuuri vt. näiteks form8rd.htm-ist.)
Moodul search_sources otsib mitteterminali A sõltuva konteksti allikaid,
moodustab C1,1(A). Globaalne muutuja on si algväärtusega 0: globaalse
vektori Word indeks
search_sources(struct h *t,int A)
parameetrid:
- A=mitteterminal, mille hulka g(A) hakatakse leidma
- t=mitteterminali A redutseerimistabeli kirje
muutujad:
- char **L
- struct h *C
- int Word[40] ¾ "surmahaarde" (deadlock) avastamiseks ja liigsete
sõltuva konteksti hulkade kõrvaldamiseks (seotud hulga g4 moodustamisega)
Algoritm:
- L:=DEPA; kui L=Æ, siis L:=defL(); DEPA:=L
- i:=0;
- S1: kui Wordi=A, siis teata "surmahaardest", STOPP
- i:=i+1; kui i ≤si mine S1
- Wordsi:=A; si:=si+1; i:=0
- S2: C:=prodi; kui C=Æ, siis mine S4; j:=0
- S3: kui C->dj=A, siis
- kui j=0 ja C->n=1, siis g4(L,C)
- kui j=0 ja C->n>1, siis g3(L,C,C->d1)
- kui j>0 ja j≠C->n-1, siis g1(L,C,C->dj-1,C->dj+1)
- kui j=C->n-1, siis g2(L,C,C->dC->n-2)
- j:=j+1; kui j<C->n, siis mine S3
- S4: i:=i+1; kui i<Pnr, siis mine S2
Wordsi:=0; si:=si-1; t->nc:=1
sõltuv kontekst. Hulk g1(A)={(X,T): B®uXADv & [T=DÚTÎL(D)]}
g1(char **L,int X,int D)
- muutuja char *rc
- rc:=LX; kui rc=Æ,siis rc:=DefVect(tnr+1) ja LX:=rc
- kui D>tnr, siis i:=1; mine S1, muidu mine S2
- S1: kui LmD,i=1, siis rci:=1
- i:=i+1; kui i<tnr+1, siis mine S1, muidu STOPP
- S2: rcD:=1, STOPP
sõltuv kontekst. Hulk g2(A)={(X,T):B®uXAÎP&TÎRC(B)}
g2(char **L,struct h *t,int X)
- muutuja char *rc
- rc:=LX; kui rc=Æ,siis rc:=DefVect(tnr+1) ja LX:=rc
- i:=1
- S1: kui RCt->NT,i=1, siis rci:=1
- i:=i+1; kui i<tnr+1, siis mine S1
sõltuv kontekst. Hulk g3(A)={(X,T):B®ADvÎP&XÎLC(B)&[T=DÚTÎL(D)]}
g3(char **L,struct h *t,int D)
- muutuja char *rc
- i:=1
- S0: kui LCt->NT,i=0, siis mine S3
- S1: kui D>tnr, siis mine S2
- rc:=Li; kui rc=Æ,siis rc:=DefVect(tnr+1) ja LX:=rc
- rcD:=1; mine S3
- S2: j:=1
- S2.1: Kui LmD,j=1, siis
- rc:=Li; kui rc=Æ,siis rc:=DefVect(tnr+1) ja LX:=rc
- rcj:=1;
- j:=j+1; kui j<tnr+1, siis mine S2.1
- S3: i:=i+1; kui i≤nr, siis mine S0
sõltuv kontekst. Hulk g4(A)={(X,T):B®AÎP&(X,T)ÎC1,1(B)}
g4(char **L,struct h *t)
Moodul join_cxt lisab sõltuva konteksti hulgale D hulga S.
join_cxt(char **D,char **S)
S0: i:=1
S1: kui Si≠Æ, siis
- src:=Si; rc:=Di; kui rc=Æ, siis
- rc:=DefVect(tnr+1); Di:=rc; j:=1
- S2: kui srcj=1, siis rcj:=srcj
- j:=j+1; kui j≤tnr, siis mine S2
- i:=i+1; kui i≤nr, siis mine S1
S3: STOPP
make_prod(void)
- muutujad: int i,j; struct h *C,*D
- j:=0; i:=0
- loop:
- kui HTi≠Æ,siis
- C:=HT[i]
- coll:
- D:=C; prodj:=C; j:=j+1
- same:
- kui D->same≠Æ,siis
- D:=D->same; prodj:=D; j:=j+1; mine same
- kui C->col≠Æ,siis C:=C->col; mine coll
- i:=i+1; kui i<HTL, siis mine loop
STOPP
Moodul make_BRC() otsib ühesuguse parema poolega produktsioone, teeb C1|1-hulgad
int make_BRC(void)
- muutujad: struct h *CP,*S; int i,j,k; char *r
- BRC:=0; i:=0
- S1: CP:=HTi
- S2: kuni CP≠Æ
- kui CP->same≠Æ
- CP:=CP->col; mine S2
- i:=i+1; kui i<HTL, siis mine S1
- return(1);
Moodul brctest(struct h *t)
- int brctest(struct h *t)
- muutujad: struct h *x,*y; struct h *SAM[40]; int ns,j,k,A,B
- x:=t; ns:=0
- fill: SAMns:=x; ns:=ns+1; x:=x->same
- kui x≠Æ, siis mine fill
- j:=0; x:=SAMj; A:=x->NT
- S1: k:=j+1
- S2: y:=SAMk; B:=y->NT; kui testpaar(A,B)≠0, siis deptest(x,y);
- k:=k+1; kui k<ns, siis mine S2
- j:=j+1; kui j<(ns-1), siis mine S1
- return(1);
int testpaar(int A,int B)
- muutujad int i,s; s:=0; i:=1
- S1: kui LCA,i=1 ja LCB,i=1, siis mine rc
- i:=i+1; kui i≤nr, mine S1
- // A ja B vasak sõltumatu kontekst eristub
- return(0);
- rc: i:=1
- S2: kui RCA,i=1 ja RCB,i=1, siis return(1);
- i:=i+1; kui i≤tnr, siis mine S2
- return(0);
int deptest(struct h *x,struct h *y)
- BRC:=BRC+1; logisse teade
- independent context didn't help us. I'll try to use the dependent one.
- kui DEP=Æ, siis DEP=defDEP()
- dc:=1; si:=0; DepV[x->P]:=1; DepV[y->P]:=1
- dc:=search_sources(x,x->NT); kui dc=0, siis return(0);
- kui dc=1, siis dc=test_dep_con(x,y); kui dc=1, siis dep:=dep+1
- return(dc);
C1,1(A) ja C1,1(B) eristumise test
int test_dep_con(struct h *x,struct h *y)
- muutujad int flag; char **A,**B
- A:=DEP[x->NT]; B:=DEP[y->NT]
- flag:=test_cxt(A,B)
- kui flag=0, siis
- logisse teade
- A and B: dependent context is not different
- add_not(x->NT,y->NT); return(0);
- BRC:=BRC-1; return(1);
int test_cxt(char **D,char **S){
- muutujad int i,j,x; int flag=1; char *rc,*src
- i:=1
- S1: src:=Si
- kui src≠Æ, siis rc:=Di
- kui rc≠Æ, siis j:=1
- S2: x:=rcj; kui x=1, siis
- kui srcj=1, siis flag:=0; logisse teade
common: pset(i,j);
- j:=j+1; kui j≤tnr, siis mine S2
- i:=i+1; kui i≤nr, siis mine S1
- return(flag);
Moodul pset(x,y) kirjutab logisse paari (x,y)ÎV
void pset(int x,int y){
fprintf(Logi," {");
if(x<=tnr) fprintf(Logi,"%s ",T[x]);
else fprintf(Logi,"`%s' ",T[x]);
if(y<=tnr) fprintf(Logi,"%s",T[y]);
else fprintf(Logi,"`%s'",T[y]);
fprintf(Logi,"} ");
}
void add_not(int x,int y){
struct U *u;
u=(struct U *)malloc(sizeof(struct U));
u->x=x;
u->y=y;
u->next=UP;
UP=u;
}
struct U{
int x;
int y;
struct U *next;
};
struct U *UP=NULL;
moodul del_dep() eemaldab pseudo-sõltuvad kontekstid
del_dep()
- muutujad: struct h *CP,*S; int i,k; i:=0
- S1: CP:=HTi
- S2: kui CP=Æ, siis mine S5
- kui CP->same≠Æ, siis
- k:=CP->P
- kui DepVk=0,siis CP->nc:=0
- S:=CP->same
- S3: kui S=Æ, siis mine S4
- k:=S->P; kui DepVk=0, siis
- S->nc=0; S:=S->same; mine S3
- S4: CP:=CP->col; mine S2
- S5: i:=i+1; kui i<HTL, siis mine S1, muidu STOPP
Maatriksi mälueraldus
char *DefArray(int d){
int n,i;
char *M;
n=(d*d);
M=(char *)malloc(n);
if(M==(char *)NULL){
sprintf(rida,"DefArray: I don't have memory enough..");
ExiT(rida);
}
for(i=0;i<n;i++) M[i]='\0';
return(M);
}
Vektori mälueraldus
char *DefVect(int n){
int i;
char *M;
M=(char *)malloc(n);
if(M==(char *)NULL){
sprintf(rida,"DefVect: I don't have memory enough..");
ExiT(rida);
}
for(i=0;i<n;i++) M[i]='\0';
return(M);
}
Sõltuva konteksti puu ülemise (mõistete) taseme mälueraldus
char ***defDEP(void){
int i,n;
n=(nr+1)*sizeof(char ***);
DEP=(char ***)malloc(n);
if(DEP==(char ***)NULL){
sprintf(rida,"defDEP: I don't have memory enough..");
ExiT(rida);
}
for(i=0;i<nr+1;i++) DEP[i]=(char **)NULL;
return(DEP);
}
Sõltuva konteksti puu vahetaseme (vasakud kontekstid) mälueraldus
char **defL(void){
int i,n;
char **L;
n=(nr+1)*sizeof(char **);
L=(char **)malloc(n);
if(L==(char **)NULL){
sprintf(rida,"defL: I don't have memory enough..");
ExiT(rida);
}
for(i=0;i<nr+1;i++) L[i]=(char *)NULL;
return(L);
}
Semantika
moodul put_semant() moodustab semantikavektori
put_semant(void)
- muutujad: char *B; int i,piir; char finame[256]
- piir:=tnr+Pnr+1; semantika=(int *)malloc((piir)*sizeof(int)); i:=0
- S1: semantikai:=0
- i:=i+1; kui i<piir, siis mine S1
- kui grammatikafaili nimi on xxx.grm, siis finame:=xxx.sem
- kui fail finame on kettal, siis mine readit
- tee kattale fail finame
- i:=1;
- S2: semantikai:=i
- kui i≤tnr, siis kirjuta faili finame kirje
fprintf(Sem,"%d=%d $ %s\n",i,i,T[i]);,
- muidu
fprintf(Sem,"P%d=%d <SPACE>$ ",i-tnr,i);Print_rule_f(SD[i-tnr],SR[i-tnr]);
- (moodul Print_rule_f kirjutab semantikafaili produktsiooni Pi-tnr
kujul A®x)
- i:=i+1; kui i<(piir-1), siis mine S2
- mine showit
- readit: B:=r_text(finame) -- see moodul sisestab etteantud tekstifaili ja
- omistab muutujale P_length selle pikkuse
- i:=0;
- S3: kui i<P_length, siis i:=i+make_sem(B+i); mine S3
- showit: kirjuta omistatud/loetud semantika logifaili
moodul make_sem töötleb järjekordset semantika-tekstifaili rida
make_sem(char *B)
- muutujad: int i,p,ix,kood,piir
- piir:=tnr+Pnr+1; p:=0
- kui Bi='$', siis
- S1: i:=i+1
- end: kui Bi='\n', siis i:=i+1; return(i);
- mine S1
- kui Bi='P' või Bi='p', siis
- i:=i+sscanf(B+i,"%d",&ix); p:=p+ix
- S2: kuni Bi≠'=' i:=i+1; mine S2
- i:=i+1; i:=i+sscanf(B+i,"%d",&kood);
- semantikap:=kood; mine end
Tabelite kirjutamine kettale
struct parm{
int nr; //tähestiku V pikkus
int tnr; //tähestiku VT pikkus
int BRC; //BRC=1, kui redutseerimiseks tuleb kasutada konteksti
int Pnr; //produktsioonide arv
int dep; //dep=1, kui redutseerimiseks tuleb kasutada sõltuvat
//konteksti
int itl; //identifikaatorite tabeli pikkus (täidab analüsaator)
int ktl; //konstantide tabeli pikkus (täidab analüsaator)
};
moodul w_tabs() kirjutab kettale Konstruktori tabelid
w_tabs(void)
- parameetrite tabeli xxx.prm salvestamine
- PARM:=(struct parm *)malloc(sizeof(struct parm));
- PARM->nr:=nr; PARM->tnr:=tnr; PARM->Pnr:=Pnr;
- PARM->BRC:=context; PARM->dep:=dc
- sprintf(rida,"%s.prm",Nimi); of:=opw();
- fwrite(PARM,sizeof(struct parm),1,of); fclose(of);
- eelnevusmaatriksi xxx.pm salvestamine
- w_PM();
- tähestiku V xxx.t salvestamine
- sprintf(rida,"%s.t",Nimi); of:=opw();
fwrite(&T,20,nr+1,of); fclose(of);
- skaneerimistabeli xxx.tt salvestamine
- make_TT(); sprintf(rida,"%s.tt",Nimi); of:=opw()
- fwrite(&TT,20,tnr+1,of);
fclose(of);
- redutseerimistabelii xxx.ht salvestamine
- sprintf(rida,"%s.ht",Nimi); of:=opw(); w_HT(of); fclose(of);
- semantikavektori xxx.sm salvestamine
- kui semantika≠Æ, siis
- sprintf(rida,"%s.sm",Nimi); of:=opw();
- fwrite(semantika,(tnr+Pnr+1)*sizeof(int),1,of); fclose(of);
- grammatika puu xxx.v salvestamine
- sprintf(rida,"%s.v",Nimi); of:=opw(); w_V(of,DT); fclose(of);
- sõltumatu konteksti maatriksite xxx.lc ja xxx.rc ning
- sõltuva konteksti tabeli xxx.dc salvestamine
- kui context=1, siis
- sprintf(rida,"%s.lc",Nimi); of:=opw();
fwrite(LC,(nr+1)*(nr+1),1,of);
- fclose(of);
- sprintf(rida,"%s.rc",Nimi); of:=opw();
- fwrite(RC,(nr+1)*(nr+1),1,of); fclose(of);
- kui dc=1, siis sprintf(rida,"%s.dc",Nimi);
of:=opw(); w_DEP(of); fclose(of);
moodul opw() loob ja avab kettal bin-faili
FILE *opw(void)
- FILE *of=NULL;
- of=fopen(rida,"wb");
- if (of==NULL){
- fclose(of);
- fprintf(Logi,"cannot create the file %s",rida);
- }
- return(of);
- }
moodul make_TT teeb skaneerimistabeli
make_TT(void)
- muutujad: int i,j; i:=0
- S1: memcpy(TT[i],T[i],20); i:=i+1; kui i≤tnr, siis mine S1
- i:=0
- S2: j:=i+1
- S3: kui strlen(TT[i])<strlen(TT[j]), siis
-
- memcpy(word,TT[i],20); memcpy(TT[i],TT[j],20);
memcpy(TT[j],word,20);
- j:=j+1; kui j≤tnr, siis mine S3
- i:=i+1; kui i<tnr, siis mine S2
Viidastruktuuride kettalekirjutamise ja lugemise näitena esitame allpool
redutseerimistabeli kirjutamise (w_HT()) ja lugemise (r_HT())
moodulite C-keelsed tekstid.
void w_HT(FILE *of){
int i,q;
q=fwrite(HT,sizeof(struct h *),HTL,of);
if(q!=HTL){
sprintf(rida,"write error w_HT()<BR>");
ExiT(rida);
}
for(i=0;i<HTL;i++){
if(HT[i]!=(struct h *)NULL) w_hr(of,HT[i]);
}
}
void w_hr(FILE *of,struct h *r){
int q;
q=fwrite(r,sizeof(struct h),1,of);
if(q!=1){
sprintf(rida,"write error w_hr()");
ExiT(rida);
}
q=fwrite(r->d,r->n*sizeof(int),1,of);
if(q!=1){
sprintf(rida,"write error w_hr()");
ExiT(rida);
}
if(r->same!=(struct h *)NULL) w_hr(of,r->same);
if(r->col!=(struct h *)NULL) w_hr(of,r->col);
}
HR>
void r_HT(void){
int i;
fread(HT,sizeof(struct h *),HTL,of);
for(i=0;i<HTL;i++){
if(HT[i]!=(struct h *)NULL) HT[i]=r_hr();
}
}
struct h *r_hr(void){
struct h *r;
r=grec();
fread(r,sizeof(struct h),1,of);
r->d=(int *)malloc(r->n*sizeof(int));
fread(r->d,r->n*sizeof(int),1,of);
if(r->same!=(struct h *)NULL) r->same=r_hr();
if(r->col!=(struct h *)NULL) r->col=r_hr();
return(r);
}
struct h *grec(void){
struct h *L;
L=(struct h *)malloc(sizeof(struct h));
if(L==(struct h *)NULL){
fprintf(Logi,"I haven't memory enough..");
ExIT();
}
return(L);
}
Analüsaator (Parser)
Konstandid, muutujad ja andmestruktuurid:
#define idtl 50 // identifikaatorite tabeli pikkus
#define ctl 50 // konstantide tabeli pikkus
int itl; // identifikaatorite tabeli index/pikkus
int ktl; // konstantide tabeli indeks/pikkus
int IT[50]; // identifikaatorite tabel; elemendid on vahekeelsed koodid
int KT[50]; // konstantide tabel; elemendid on vahekeelsed koodid
char *PBuf // programmi teksti puhver
int Plen // programmi teksti pikkus
analüüsi puu tipp:
struct top{
int kood; // vahekeelne kood
int leks; // kui tipp=ident/const, siis selle jrk-nr.
int sem; // semantikakood
int label; // kui tipp on märgendatud operaator - märgendi nr
int truel; // kompilaator: go to true
int falsel; // kompilaator: go to false
struct top *up; // puuviidad: üles,
struct top *right; // naabrile ja
struct top *down; // alluvale
};
Käsurealt käivitatakse analüsaator järgmiselt:
parser32 <grammatika> <programm>
Näiteks
parser32 tri p7 //grammatika on tri.grm ja programm p7.tri
parser32 g1 a //grammatika on g1.grm ja programm a.g1
Analüsaatori juhtmoodul on järgmine:
main(int argc,char **argv)
- parameetrite töötlemine: nimede tegemine
- logi avamine
- programmi sisestamine: PBuf:=jarray(pr_name) -- PBuf on sisestatud
teksti puhver, Plen on selle teksti pikkus ja moodul jarray
sisestab etteantud nimega tekstifaili
- kui analyzer()≠Æ, siis
int analyzer(void)
- sisestatakse analüüsitav sõna ("programm")
- kui r_tabs()=0, siis return(0);
- Sn:=nr; P:=PBuf; logisse teade "Scanner started"
- kui scanner()=0 või VEAD>0, siis return(0);
- logisse teade "Parser started"
- p_:=parser()
- kui p_=Æ, siis return(0);
- logisse teade "Parsing tree"; pp2html(p_)
- return(1);
Tekstimassiivi sisestamine kettalt
char *jarray(char *pealkiri){
FILE *tekst=NULL;
char *B;
char c;
int i;
int k;
struct stat *buf;
buf=(struct stat *)malloc(sizeof(struct stat));
if(buf==NULL){
fprintf(Logi,"r_text: I haven't %d bytes of memory..",
sizeof(struct stat));
ExIT();
}
tekst = fopen(pealkiri, "r");
if (tekst==NULL){
fprintf(Logi,"cannot find the file %s" ,pealkiri);
ExIT();
}
if(stat(pealkiri,buf)==-1){
fprintf(Logi,"r_text: stat failed");
ExIT();
}
k=buf->st_size;
B = (char *)malloc(k+10);
if(B == NULL){
fprintf(Logi,"I don't have memory enaugh..");
ExIT();
}
memset(B,'\0',k+10);
/* fill buffer */
rewind(tekst);
i=0;
while (!feof(tekst)){
c=fgetc(tekst);
B[i]=c;
i++;
}
P_length=i;
for(i=P_length;i>0;i--){
if(isgraph(B[i])){
i++;
B[i]='\n';
i++;
B[i]='\0';
P_length=i;
goto out;
}
}
out: fclose(tekst);
return(B);
}
Konstruktori tabelite sisestamine
int r_tabs(void)
- muutuja flag:=1
- parameetrite lugemine: flag:=r_parm(); kui flag=0, siis mine out
- tähestiku V lugemine: flag:=r_t(); kui flag=0, siis mine out
- skanneri tabeli lugemine: flag:=r_tt(); kui flag=0, siis mine out
- semantikavektori lugemine: flag:=r_sm(); kui flag=0, siis mine out
- grammatika puu lugemine: flag:=r_v(); kui flag=0, siis mine out
- redutseerimistabeli lugemine: flag:=r_ht(); kui flag=0, siis mine out
- eelnevusmaatriksi lugemine: PM:=DefArray(nr+1); flag:=r_pm();
- kui flag=0, siis mine out
- kui context>0, siis
- LC:=DefArray(nr+1); RC:=DefArray(nr+1)
- sõltumatu konteksti maatriksite lugemine: flag:=inxt()
- kui flag=0, siis mine out
- kui dc>0, siis
- sõltuva konteksti tabeli lugemine: flag:=depc()
- kui flag=0, siis mine out
- out: kui flag=0, siis
- logisse teade "cannot read all the tables.."
- return(flag);
Parameetrite tabeli sisestamine
int r_parm(void){
PARM=(struct parm *)malloc(sizeof(struct parm));
if(PARM==(struct parm *)NULL) ExIT();
memset(PARM,'\0',sizeof(struct parm));
sprintf(rida,"%s.prm",Nimi);
if(opr()!=NULL){
fread(PARM,sizeof(struct parm),1,of);
fclose(of);
nr=PARM->nr;
tnr=PARM->tnr;
Sn=nr;
context=PARM->BRC;
Pnr=PARM->Pnr;
dc=PARM->dep;
return(1);
}
return(0);
}
Skanner teisendab lähteprogrammi vahekeelseks.
globaalne muutuja char word[20] on lekseemi kogumiseks.
int scanner(void)
- muutujad: struct D *t; int i,j,k,r,olek
- globaalne muutuja int VKL on lekseemide arv vektoris VK (VK on vahekeelse
koodi ühemõõtmeline int-massiiv)
- j:=0; itl:=0; ktl:=0
(itl on identifikaatorite ja ktl konstantide tabeli pikkus)
- m_k:=0; k_k:=0 (m_k on lekseemiklassi #i# ja k_k #c# kood)
- VEAD:=0;
- t:=getV("#i#"); kui t≠Æ, siis m_k:=t->code
- t:=getV("#c#"); kui t≠Æ, siis k_k:=t->code
- vahekeelse koodi vektorile mälu eraldamine:
vkl:=Plen*8; VK:=(int *)malloc(vkl)
- i:=0; olek:=0
- t:=getV("#"); kui t≠Æ, siis marker:=t->code;
- VK0:=marker; k:=1; kui PBufi='#', siis i:=1
- memset(word,'\0',20)
- S1: kui i=Plen, siis mine out
- kui olek=0, siis
- kui PBufi on tühik, tabulatsioon või reavahetus,
siis i:=i+1; mine S1
- kui k_k>0, siis
ja kui PBufi on number,
siis j:=0; olek:=2; mine S1
- r:=lekseem(i); kui r>0,
siis
- VKk:=KOOD; k:=k+1; memset(word,'\0',20);
i:=i+r; j:=0; mine S1
- j:=0; memset(word,'\0',20);
- kui PBufi on täht,
siis j:=0; olek:=1; mine S1
- kui PBufi pole number ega täht, siis
- p_viga(i); i:=i+1; j:=0; memset(word,'\0',20); mine S1
- kui olek=1, siis
- kui PBufi on täht, siis wordj:=PBufi; i:=i+1; j:=j+1
- kui PBufi on number, siis wordj:=PBufi; i:=i+1; j:=j+1
- kui PBufi pole number ega täht, siis
k:=Ident(k); j:=0; olek:=0; mine S1
- kui PBufi on tühik, tabulatsioon või reavahetus, siis
- i:=i+1;k:=Ident(k); j:=0; olek:=0; mine S1
- kui olek=2, siis
- kui PBufi on täht, siis
- p_viga(i); i:=i+1; j:=0; memset(word,'\0',20); mine S1
- kui PBufi on number, siis wordj:=PBufi; i:=i+1; j:=j+1
- kui PBufi pole number ega täht,
siis k:=Const(k); j:=0; olek:=0; mine S1
- kui PBufi on tühik, tabulatsioon või reavahetus, siis
- i:=i+1;k:=Const(k); j:=0; olek:=0; mine S1
- out: kui VEAD>0 siis return(0);
- kui VKk-1≠marker, siis VKk:=marker ja k:=k+1
print_VK(k); VKL:=k; memcpy(word,"DUMMY",5); Ident(k);
- dummy:=nr; NR:=nr; nr:=Sn
- dummy on libaidentifikaator, aitamaks jatkata veasituatsioonis
- return(1);
Moodul getV: tähestiku V elemendi otsimine
struct D *getV(char *key)
- muutujad: struct D *t; int res
- t:=DT;
- ring: kui t->loc=0, siis res:=strcmp(key,T[t->code]);,
- muidu res:=strcmp(key,T[t->loc]);
- kui res=0, siis mine out
- kui res<0, siis
- kui t->left≠Æ, siis t:=t->left; mine ring
- mine exit
- kui res>0, siis
- kui t->right≠Æ, siis t:=t->right; mine ring
- exit: t:=Æ
- out: return(t);
Moodul lekseem tagastab reservsõna või eraldaja koodi
int lekseem(int i)
- muutujad: char *b,*g; struct D *t; int a,j,s,n
- b:=PBuf+i; s:=0
- S1: kuni s≤tnr
- g:=TTs; kui g=Æ, siis return(0);
- n:=strlen(g); j:=0; a:=0
- S2: kuni a<n
- kui ba≠ga, siis mine next
- wordj:=bj; j:=j+1; a:=a+1; mine S2
- i:=i+j; t:=getV(word); kui t=Æ, siis väju analüsaatorist
- KOOD:=t->code; return(j);
- next: s:=s+1; j:=0; mine S1
- return(0);
Moodul Ident töötleb identifikaatorit
int Ident(int k)
- muutujad: int t,i:=0; char *id
- S1: kuni i<itl
- t:=ITi; id:=Tt; kui id=word, siis goto itis;
- i:=i+1; mine S1
- nr:=nr+1; Tnr:=word; VKk:=m_k; ITitl:=nr
- itl:=itl+1; k:=k+1; VKk:=nr; k:=k+1; mine ok
- itis: VKk:=m_k; k:=k+1; VKk:=t; k:=k+1
- ok: return(k);
Moodul Const töötleb konstanti
int Const(int k)
- muutujad: int t,i:=0; char *con
- S1: kuni i<ktl
- t:=KTi; con:=Tt; kui con=word, siis mine itis
- i:=i+1; mine S1
- nr:=nr+1; Tnr:=word; VKk:=k_k; KTktl:=nr; ktl:=ktl+1;k:=k+1 mine ok
- itis: VKk:=k_k; k:=l+1; VKk:=t; k:=k+1
- ok: return(k);
Analüsaatori põhiprogramm
globaalsed muutujad:
- int Stack[200]; char rela[200]; int lausevorm[20]; struct top *puu[200]
- struct h *hc; //BRC-analüüsil detekteeritud kirje viit
struct top *parser(void)
- muutujad: int i,j,r; char c:=' ';
- Stack0:=marker; x_:=marker; J:=1; I:=1
- S1: kuni I<VKL
- rel:=PMx_,VKI; j:=VKI; relaJ:=rel
- kui rel=0
- logisse teade: "no relationship between the symbols Tx_ and Tj"
- kui grammatika pole Trigol, siis p_:=Æ; return(p_);
- logisse teade: "I'll try to correct.."
- kui correct()=0, siis I:=I+1; mine S1
- kui rel=1
- kui VKI=marker, siis logisse teade "the parsing is completed";
return(p_);
- StackJ:=VKI; x_:=StackJ
- kui x_=m_k või x_=k_k, siis I:=I+1
- puuJ:=newtop(x_,I,x_); J:=J+1; I:=I+1; mine S1
- kui rel=2
- StackJ:=VKI; x_:=StackJ; kui x_=m_k või x_=k_k, siis I:=I+1
- puuJ:=newtop(x_,I,x_); J:=J+1; I:=I+1; mine S1
- kui rel=4
- sentential_form(); t_:=ReadHash(n_,lausevorm);
- kui t_=Æ, siis p_:=Æ; return(p_);
- N_:=reduce(t_,Stacks_-1,VKI); t_:=hc;
- kui N_=0, siis logisse teade "reduce error"; p_:=Æ; return(p_);
- relas_:=PMStacks_-1,N_; Stacks_:=N_; x_:=N_
- p_:=newtop(N_,I,t_->P+tnr); red_tree(puu,p_,s_,n_)
- puus_:=p_; p_stack("<BR>",Stack,rela,0,s_+1,I)>;
- kui semantikat_->P+tnr>0, siis logisse teade "Parsing tree";
pp2html(p_)
- J:=s_+1; mine S1
- return(p_);
Analüüsi jatkamine vea korral
int correct(void){
int i,r;
if(x_==VK[I]) return(0);
for(i=1;i<tnr;i++){
r=PM[adr(x_,i)];
if(r!=0){
Stack[J]=i;
rela[J]=r;
x_=i;
p_stack("\n",Stack,rela,0,J+1,I);
if((x_==m_k)||(x_==k_k)) puu[J]=newtop(x_,0,x_);
J++;
return(1);
}
}
return(0);
}
Analüüsi puu uue tipu moodustamine
struct top *newtop(int x,int i,int sem)
- muutujad: struct top *ptr:=Æ
- kui x<tnr+1 ja semantika[sem]=0, siis mine out
- ptr:=(struct top *)malloc(sizeof(struct top));
- ptr->up:=Æ; ptr->right:=Æ ptr->down:=Æ
- ptr->kood:=x; ptr->sem:=semantika[sem]
- kui x=m_k või x=k_k, siis
- kui i=0, siis ptr->leks:=dummy, muidu ptr->leks:=VKi
- out: return(ptr);
Lausevormi detekteerimine
void sentential_form(void)
- s_:=J
- S1: kui s_>0, siis
- kui relas_=2, siis mine S2
- s_:=s_-1; mine S1
- S2: n_:=J-s_; l_:=0
- S3: kuni l_<n_
- lausevorml_:=Stacks_+l_; l_:=l_+1; mine S3
Produktsiooni otsimine paisktabelist
struct h *ReadHash(int n,int *key)
- muutujad: struct h *t; int i,a
- a:=hfunc(n,key); t:=HTa
- otsi: kui t≠Æ, siis
- kui n=t->n, siis i:=0;
- S1:kuni i<n
- kui keyi≠t->di, siis mine next
- kui keyi≠t->di, siis mine next
- i:=i+1; mine S1
- return(t);
- next: t:=t->col; mine otsi
- return(Æ);
Redutseerib lausevormi mitteterminali koodiks
int reduce(struct h *t,int x, int y)
- muutujad: int ret:=0; struct h *S
- hc:=Æ
- kui t->same=Æ, siis hc:=t; return(t->NT);
- S:=t;
- S1: kuni S≠Æ
- kui S->nc>0, siis ret:=red_dep(S,x,y);
kui ret>0, siis return(ret);
- S:=S->same; mine S1
- ret:=red_indep(t,x,y); return(ret);
Moodul red_dep kasutab redutseerimiseks sõltuvat konteksti
int red_dep(struct h *S,int x,int y)
- muutujad: char **L; char *rc
- L:=DEP[S->NT];
- kui L≠Æ, siis
- rc:=Lx; kui rc=Æ, siis return(0);
- kui rcy=1, siis hc:=S ja return(S->NT);
return(0);
Moodul red_indep kasutab redutseerimiseks sõltumatut konteksti
int red_indep(struct h *t,int x,int y)
- muutujad: int ret=0; int r=0; struct h *S
- S:=t
- S1: kuni S≠Æ
- kui S->nc=0, siis
- kui LCS->NT,x>0, siis
- r:=r+1; ret:=S->NT; hc:=S
- S:=S->same; mine S1
- kui r=0,siis
- logisse teade "Tx is not in any LCs"; hc:=Æ; return(0);
- kui r=1, siis return(ret);
- S:=t;
- S2: kuni S≠Æ
- kui S->nc=0, siis
- S:=S->same; mine S2
- logisse teade "Ty is not in any RC"; hc:=Æ; return(0);
Analüüsi puu moodustamine: uue tipu/alampuu lisamine
void red_tree(struct top *puu[],struct top *p,int s,int n)
- muuutujad: int i; struct top *cp:=Æ; struct top *first:=Æ;
struct top *last:=Æ
- i:=0
- S1: kuni i<n
- kui puui+s≠Æ, siis
- cp:=puui+s; kui cp->sem=0, siis
- kui cp->down≠Æ, siis
- cp:=cp->down; kui first≠Æ, siis first:=cp
- kui last≠Æ, siis last->right:=cp
- S2: kuni cp->right≠Æ
- cp->up:=Æ; mine next
- kui first=Æ, siis first:=cp
- kui last≠Æ, siis last->right:=cp
- next: last:=cp
- i:=i+1; mine S1
- p->down:=first; kui last≠Æ, siis last->up:=p
Analüüsi puu (fragmendi) trükk
int pp2html(struct top *p)
- muutujad: double pr; int n:=1; struct top *t; char s[20]
- t:=p
- naaber: kui t->right≠Æ, siis
- n:=n+1; t:=t->right; mine naaber
- pr:=100.0/n; sprintf(s,"\"%2.0f%\"",pr);
fprintf(Logi,"<table border=1><tr>");
- next: fprintf(Logi,"<td width=%s valign=\"top\"><STRONG>",s);
- kui p->kood=m_k või p->kood=k_k, siis fprintf(Logi,"%s",T[p->leks]),
- muidu fprintf(Logi,"%s",T[p->kood]);
- kui p->down≠Æ, siis pp2html(p->down)
- fprintf(Logi,"</td>"); kui p->right≠Æ, siis
- fprintf(Logi,"</tr></table>"); return(1)
Magasini ja analüüsimata lekseemide trükk
int p_stack(char *name,int *v,char *rel,int a,int n,int k)
- muutujad: int i,j,lv
- fprintf(Logi,"<BR><TABLE BORDER=1><B><TR><TD NOWRAP>Stack & Word</TD>");
- lv:=n
- S1: kuni lv>0
- kui rellv=2, siis mine S2; lv:=lv-1; mine S1
- S2: i:=a
- S3: kuni i<n
- j:=reli; fprintf(Logi,"<TD NOWRAP> %s",s[j]); j:=vi
- kui i<lv, siis
- fprintf(Logi,
"<FONT COLOR=\"#0000FF\"><STRONG>%s</FONT></TD>",T[j]);
- muidu fprintf(Logi,
"<FONT COLOR=\"#FF0000\"><STRONG>%s</FONT></TD>",T[j]);
- i:=i+1; mine S3
- i:=k;
- S4: kuni i<VKL
- j:=VKi; fprintf(Logi,"<TD>%s </TD>",T[j]);
- i:=i+1; mine S4
- fprintf(Logi,"</TR></TABLE>"); return(0);
Analüsaatori tabelite kirjutamine kettale
int w_p_tabs(void)
- w_parm() kirjutab kettale parameetrite tabeli
- w_t() ¾ tähestiku V (massiiv T)
- w_it() ¾ identifikaatorite tabeli IT
- w_kt() ¾ konstantide tabeli KT
- w_ptree() ¾ analüüsi puu
Analüüsi puu kirjutamine kettale
void w_ptree(struct top *p)
- fwrite(p,sizeof(struct top),1,of)
- kui p->right≠Æ, siis w_ptree(p->right)
- kui p->down≠Æ, siis w_ptree(p->down)
Moodul make_rtf()
genereerib kettale html-faili, demonstreerimaks tegelikke andmestruktuure.
Kui analüüsitav sõna on failis xxx.yyy, siis genereeritava
faili nimi on xxxrd.htm. Vt. näiteks p6rd.htm
Interpretaator (Interpreter)
Trigoli interpretaator ja kompilaator kasutavad järgmisi konstante
(vt. Trigoli semantikat), andmestruktuure ja globaalseid muutujaid:
#define muut 1 // #i# - identifikaator
#define konst 2 // #c# - konstant
#define pisem 3 // <
#define suurem 4 // >
#define piv 5 // <=
#define suv 6 // >=
#define pov 7 // /=
#define vord 8 // =
#define omist 10 // omistamisoperaator
#define jag 11 // jagamistehe
#define korrut 12 // korrutamistehe
#define lahut 13 // lahutustehe
#define liit 14 // liitmistehe
#define labl 15 // märgend
#define suunam 16 // suunamisoperaator
#define kuisiis 18 // if-lause
#define tingop 19 // tingimusoperaator
#define lugem 20 // lugemisoperaator
#define kirjut 21 // kirjutamisoperaator
identifikaatorite tabeli kirje:
struct itr{
int nr; // jrk-nr tähestikus V
int loc;
int value; // interpretaator: muutuja väärtus
struct top *t; // kui id=märgend: viit operaatorile
int io; // 0, kui pole, 1: read, 2: write, 3: r&w
};
konstantide tabeli kirje:
struct ctr{
int nr; // jrk-nr tähestikus V
int loc;
int value; // konstandi väärtus
};
struct ctr *CT[ctl];
struct itr *IDT[idtl];
interpretaatori (ja kompilaatori) magasinielement:
struct item{
int liik; // 0 töömuutuja, 1 id, 2 c, 3 top
int index; // töömuutuja väärtus
struct itr *id; // liik = 1 (muutuja)
struct ctr *c; // liik = 2 (konstant)
struct top *t; // liik = 3 (märgend)
};
struct item *stack[20]; // interpretaatori (ja kompilaatori) magasin
Interpretaatori juhtprogramm on põhimõtteliselt järgmine:
- m_k=4; k_k=11 (identifikaatorite klassi ja konstantide klassi semantika)
- Analüsaatori tabelite lugemine: kui r_tabs()=0, siis return(0);
- programmi teksti trükk: p_prog(p_);
- analüüsi puu trükk: pp2html(p_);
- identifikaatorite ja konstantide tabelite tegemine: ctree()
- trigol_Int(p_);
Analüsaatori tabelite lugemine
int r_tabs(void)
- muutuja int flag:=1
- parameetrite lugemine: flag:=r_parm(); kui flag=0, siis mine out
- tähestiku V lugemine: flag:=r_t(); kui flag=0, siis mine out
- identifikaatorite tabeli lugemine: flag:=r_it(); kui flag=0, siis mine out
- konstantide tabeli lugemine: flag:=r_kt(); kui flag=0, siis mine out
- analüüsi puu lugemine flag:=r_tree(); kui flag=0, siis mine out
- out: kui flag=0, siis
fprintf(Logi,"cannot read all the tables..");
- return(flag);
Analüüsi puu lugemise juhtmoodul
int r_tree(void)
- sprintf(rida,"%s.pt",Pr_name);
- kui opr()≠NULL, siis
return(0);
Analüüsi puu lugemine
struct top *r_ptree(void)
- muutujad: struct top *p
- p:=(struct top *)malloc(sizeof(struct top));
- fread(p,sizeof(struct top),1,of);
- kui p->right≠Æ, siis p->right:=r_ptree();
- kui p->down≠Æ, siis p->down:=r_ptree();
- return(p);
Analüüsi puu üles-viitade tegemine
void set_up(struct top *root)
- muutujad: struct top *p;
- p:=root; kui p->down≠Æ, siis
- p:=p->down
- S1: kuni p->right≠Æ
- p->up:=root
- kui root->down≠Æ, siis set_up(root->down);
- kui root->right≠Æ, siis set_up(root->right);
Programmi teksti trükk analüüsi puu järgi
void p_prog(struct top *root)
- muutuja: struct top *t
- t:=root->down; fprintf(Logi,"#");
- naaber: print_Op(t);
- kui t->sem≠kuisiis ja t->sem≠labl ja t->up≠root, siis ps()
- t:=t->right; kui t=Æ, siis mine ok
- mine naaber
- ok: fprintf(Logi,"#");
Operaatori teksti trükk analüüsi puu järgi
int print_Op(struct top *t)
- muutujad: int fg=0
- kui t=Æ, siis return(0);
- kui t->sem=labl, siis
- t:=t->down; fprintf(Logi,"%s: ",T[t->leks]); return(0);
- kui t->sem=lugem või t->sem=kirjut, siis
- tprop(t->sem); t:=t->down; fprintf(Logi,"%s",T[t->leks]); return(0);
- kui t->sem=suunam, siis
- tprop(t->sem); t:=t->down; t:=t->down
- fprintf(Logi," %s",T[t->leks]); return(0);
- kui t->sem=kuisiis, siis
- fprintf(Logi,"IF "); print_Op(t->down);
- fprintf(Logi," THEN "); return(0);
- kui t->down≠Æ ja t->sem≠omist, siis
- print_Op(t->down);
- kui t->leks≠0, siis fprintf(Logi,"%s",T[t->leks]); muidu tprop(t->sem);
- t:=t->down; kui t≠Æ, siis
- print_Op(t->right); kui fg=1, siis fprintf(Logi,")")
- return(0);
Operaatori trükk
void tprop(int s){
switch(s){
case 0: fprintf(Logi,"root"); break;
case pisem: fprintf(Logi,"<"); break;
case suurem: fprintf(Logi,">"); break;
case piv: fprintf(Logi,"<="); break;
case suv: fprintf(Logi,">="); break;
case pov: fprintf(Logi,"/="); break;
case vord: fprintf(Logi,"="); break;
case omist: fprintf(Logi,":="); break;
case jag: fprintf(Logi,"/"); break;
case korrut: fprintf(Logi,"*"); break;
case lahut: fprintf(Logi,"-"); break;
case liit: fprintf(Logi,"+"); break;
case suunam: fprintf(Logi,"GOTO "); break;
case kuisiis: fprintf(Logi,"IF "); break;
case tingop: fprintf(Logi," "); break;
case lugem: fprintf(Logi,"READ "); break;
case kirjut: fprintf(Logi,"WRITE "); break;
case labl: fprintf(Logi,"label"); break;
default: fprintf(Logi,"%d",s); break;
}
}
void ps(void){
fprintf(Logi,"<BR>");
}
Identifikaatorite ja konstantide tabelite tegemine
void ctree(void)
Konstantide tabeli moodustamine
int make_CT(void)
- muutujad: int t; struct ctr *c; int i
- i:=0
- S1: kuni i<ktl
- t:=KTi; c:=(struct ctr *)malloc(sizeof(struct ctr));
- c->nr:=t; c->value:=atoi(Tc->nr); CTi:=c
- i:=i+1; mine S1
Identifikaatorite tabeli moodustamine
int make_IDT(void)
- muutujad: int t; struct itr *c; int i
- i:=0
- S1: kuni i<itl
- t:=ITi; c:=(struct itr *)malloc(sizeof(struct itr));
- c->nr:=t; c->value:=atoi(Tc->nr); IDTi:=c
- i:=i+1; mine S1
Trigoli interpretaator
void trigol_Int(struct top *root)
- muutujad: struct itr *id; struct ctr *c; struct top *t; struct item *s
- int op; int i=0; int j,k,x
- t:=root->down;
- down: p_label(t);
- kui t->down≠Æ,siis
- //leht => stack
- s:=make_item(); op:=t->sem
- kui op=muut, siis
- s->liik:=1; k:=0
-
- S1: kuni k<itl
- kui ITk=t->leks, siis
- k:=k+1; mine S1
- iok: s->id:=id
- kui id->t≠Æ,siis
- mine S3
- kui op=konst, siis
- s->liik:=2; k:=0
- S2: kuni k<itl
- kui KTk=t->leks, siis
- k:=k+1; mine S2
- cok: s->c:=c
- S3: stacki:=s; i:=i+1; prist(i,0);
- naaber: kui t->up≠Æ,siis
- t:=t->up; kui t=root, siis mine ok
- fprintf(Logi,"interpreting the operator "); print_Op(t);
- pp2html(t); op:=t->sem
- kui op≥pisem ja op≤vord, siis
- kui op=omist, siis
- kui op≥jag ja op≤liit, siis
- aritm(i,op); i:=i-1; mine S4
- kui op=suunam, siis
- s:=stacki-1; t:=s->t; id:=s->id
- fprintf(Logi,"goto %s",T[id->nr]);
- freestack(i,1); i:=i-1; mine down
- kui op=kuisiis, siis
- kui op=tingop, siis mine S4
- kui op=lugem, siis
- s:=stacki-1; id:=s->id
- printf("\aInput %s= ",T[id->nr]); scanf("%d",&x);
- fprintf(Logi,"Input %s=%d",T[id->nr],x);
- id->value:=x; freestack(i,1); i:=i-1; mine S4
- kui op=kirjut, siis
- s:=stacki-1; id:=s->id
- fprintf(Logi,"Output %s=%d",T[id->nr],id->value);
- freestack(i,1); i:=i-1; mine S4
- S4: prist(i,0); mine naaber
- ok: fprintf(Logi,"program %s is completed",pr_name);
- jokk: print_variables();
Märgendi trükk
void p_label(struct top *p)
- kui p->label>0, siis fprintf(Logi,"%s: ",T[p->label]);
Magasini elemendi mälueraldus
struct item *make_item(void)
- muutujad: struct item *c;
- c:=(struct item *)malloc(sizeof(struct item));
- memset(c,'\0',sizeof(struct item));
- return(c);
Magasini trükk
void prist(int i,int ic)
- struct item *s; struct ctr *c; struct itr *id; int k;
- fprintf(Logi,"<BR><TABLE BORDER=1><B><TR>");
- fprintf(Logi,"<TD><FONT COLOR=\"#0000FF\"><STRONG>Stack<FONT></TD>");
- k:=0;
- S1: kuni k<i
- s:=stackk;
- kui s->liik=0, siis
- fprintf(Logi,"<TD>tm=%d</TD>",s->index); mine S2
- kui s->liik=1, siis
- id:=s->id;
- kui ic=0, siis fprintf(Logi,
"<TD>id %s=%d</TD>",T[id->nr],id->value); muidu
- fprintf(Logi,"<TD>id %s</TD>",T[id->nr]);
- mine S2
- kui s->liik=2, siis
- c:=s->c; fprintf(Logi,"<TD>const=%d</TD>",c->value);
- mine S2
- kui s->liik=3, siis
- s:=s->id; fprintf(Logi,"<TD>%s:</TD>",T[id->nr]);
- mine S2
- S2: k:=k+1; mine S1
- fprintf(Logi,"</TR></TABLE>");
Võrdlustehete täitja C-tekst
void loogik(int i,int r){
struct item *s;
int x,y;
int res=0; /* false */
x=get_x(i,2);
y=get_x(i,1);
s=make_item();
s->liik=0;
fprintf(Logi,"<BR>");
switch(r){
case pisem: if(x<y) res=1; fprintf(Logi,"%d < %d ?",x,y); break;
case suurem: if(x>y) res=1; fprintf(Logi,"%d > %d ?",x,y); break;
case piv: if(x<=y) res=1; fprintf(Logi,"%d <= %d ?",x,y); break;
case suv: if(x>=y) res=1; fprintf(Logi,"%d >= %d ?",x,y); break;
case pov: if(x!=y) res=1; fprintf(Logi,"%d /= %d ?",x,y); break;
case vord: if(x==y) res=1; fprintf(Logi,"%d = %d ?",x,y); break;
}
fprintf(Logi,"<BR>");
s->index=res;
freestack(i,2);
stack[i-2]=s;
}
Anna muutuja, konstandi või töömuutuja väärtus
int get_x(int i,int k)
- muutujad: struct item *s; struct ctr *c; struct itr *id; int x=0;
- s:=stacki-k;
- kui s->liik=0, siis
- kui s->liik=1, siis
- id:=s->id; x:=id->value; mine out
- kui s->liik=2, siis
- out: return(x);
Salvesta muutuja väärtus
void write_x(int x,int i)
- muutujad: struct item *s; struct itr *id;
- s:=stacki-2; id:=s->id; id->value:=x;
- fprintf(Logi,"<BR>%s:=%d<BR>",T[id->nr],id->value);
Aritmeetiliste tehete täitja C-tekst
void aritm(int i,int r)
struct item *s;
int x,y,res=0;
x=get_x(i,2);
y=get_x(i,1);
s=make_item();
s->liik=0;
fprintf(Logi,"<BR>");
switch(r){
case jag: res=x/y; fprintf(Logi,"%d = %d / %d",res,x,y); break;
case korrut: res=x*y; fprintf(Logi,"%d = %d * %d",res,x,y); break;
case lahut: res=x-y; fprintf(Logi,"%d = %d - %d",res,x,y); break;
case liit: res=x+y; fprintf(Logi,"%d = %d + %d",res,x,y); break;
}
fprintf(Logi,"<BR>");
s->index=res;
freestack(i,2);
stack[i-2]=s;
}
Muutujate väljatrükk
void print_variables(void)
- muutujad: struct itr *id; int i;
- logisse teade: "THE VARIABLES:"; i:=0
- S1: kuni i<itl
- id:=IDT[i]; kui id->t=Æ,
siis fprintf(Logi,"%s=%d<BR>",T[id->nr],id->value);
- i:=i+1; mine S1
Kompilaator (Compiler)
Trigol-kompilaator käivitatakse käsurealt järgmiselt:
cmp32 <programmi_nimi> [o]
Näiteks: cmp32 p6 või cmp32 p7 o
Fakultatiivne parameeter 'o' nõuab optimeerivat transleerimist.
Globaalsed muutujad:
int IX; //töömärgendi jooksev indeks
int tmarv; //töömuutujate arv
int Label;
int opt; //0 ¾ ei optimeeri, 1 ¾ optimeerib
int nado=0;
Konstandid ja andmestruktuurid on samad nagu interpretaatoril.
Kompilaatori juhtprogramm on põhimõtteliselt järgmine:
- m_k=4; k_k=11 (identifikaatorite klassi ja konstantide klassi semantika)
- Analüsaatori tabelite lugemine: kui r_tabs()=0, siis return(0);
- programmi teksti trükk: p_prog(p_)
- analüüsi puu trükk: pp2html(p_)
- identifikaatorite ja konstantide tabelite tegemine: ctree()
- puu teisendamine: kui det_label(p_->down)>0, siis set_label(p_->down);
- to_asm(p_);
Märgendatud operaatorite otsimine
int det_label(struct top *P)
- muutujad: struct top *t,*op,*lab; struct itr *id; int k,flag=0;
- t:=P;
- ring: kui t=Æ, siis mine out
- kui t->sem=labl, siis
- op:=t->right; lab:=t->down; k:=0;
- S1: kui k=itl, mine
- kui ITk=lab->leks, siis
- k:=k+1; mine S1
- iok: kui id->t≠Æ, siis
- fprintf(Logi,"label '%s' repeats<BR>",T[lab->leks]);
- flag:=flag+1; mine next
- id->t:=op;
- fprintf(Logi,
"label '%s' is address of the operator {%s} (%p)<BR>",
T[lab->leks],T[op->kood],op);
- t:=op; mine ring
- next: t:=t->right; mine ring
- out: return(flag);
Puu teisendamine
int set_label(struct top *P)
- muutujad: struct top *t,*op,*lab,*prev; struct itr *id; int k;
- t:=P; prev:=P;
- ring: kui t=Æ, siis return(1);
- kui t->sem=labl, siis
- op:=t->right; lab:=t->down; k:=0;
- S1: kuni k<itl
- kui ITk=lab->leks, siis
- k:=k+1; mine S1
- iok: id->t:=op; prev->right:=op; op->label:=lab->leks;
- free(t); free(lab); t:=op; mine ring
- prev:=t; t:=t->right; mine ring
Kompilaator TRIGOList Assemblerisse
void to_asm(struct top *p)
- Rd:=0; Wr:=0; tmarv:=det_nrlv(p);
- kui tmarv<0, siis mine ots
- logisse trade: "Modified tree:"; pp2html(p_);
- kui gen_header()=0, siis mine ots
- kui opt=0, siis trigol_Asm(p_); muidu trigol_Asm_O(p);
- logisse teade: "I'll start compiler from assembler, and linker"
- sprintf(rida,"tasm %s >>%s\n",Pr_name,L_name);
- fprintf(Logi,"<BR>%s<BR>",rida);
- fflush(Logi); fclose(Logi); system(rida);
- Logi=fopen(L_name,"a+"); sprintf(rida,"tlink %s+teek >>%s\n",Pr_name,L_name);
- fprintf(Logi,"<BR>%s<BR>",rida);
- fflush(Logi); fclose(Logi); system(rida); Logi=fopen(L_name,"a+");
- ots: fflush(Logi); fflush(rules); fclose(rules);
Luurab töömuutujate arvu (tmarv), töötleb if-lause puud
int det_nrlv(struct top *root)
- muutujad: struct top *t,*t1,*t2,*t3,*t4; struct itr *id;
- int k; char st[20]; int op; int tm=0;
- int N=0; // maks. töömuutuja number
- int i=0; // magasiniindeks
- IX:=1; // töömärgendi nr
- t:=root->down; memset(st,'\0',20);
- down: kui t->down≠Æ, siis
- leht: op:=t->sem;
- kui op=muut, siis
- sti:=1; k:=0; //muutuja
- S1: kui k=itl, siis mine S2
- kui ITk=t->leks, siis
- k:=k+1; mine S1
- iok: kui id->t≠Æ, siis sti=3; //märgend
- mine S2
- kui op=konst, siis sti=2; //konstant
- i:=i+1;
- naaber: kui t->up=Æ, siis
- t:=t->right;
- kui t->down≠Æ, siis mine down, muidu mine leht
- t:=t->up; kui t=root, siis mine ok
- op:=t->sem; kui op≥pisem ja op≤vord, siis
- kui sti-2=4, siis tm:=tm-1; kui sti-1=4, siis tm:=tm-1;
- i:=i-2; mine naaber
- kui op≥jag ja op≤liit, siis
- kui sti-2=4, siis tm:=tm-1; kui sti-1=4, siis tm:=tm-1;
- sti-2:=4; tm:=tm+1; kui tm>N, siis N:=tm; i:=i-1; mine naaber
- kui op=omist, siis
- kui sti-2=4, siis tm:=tm-1; kui sti-1=4, siis tm:=tm-1; i:=i-2;
mine naaber
- kui op=suunam, siis i:=i-1; mine naaber
- kui op=kuisiis, siis
- t1:=t->down; t2:=t->right; kui t2->sem=suunam, siis
- t3:=t2->down; t4:=t3->down; t1->truel:=t4->leks;
free(t3); free(t4);
- t->up:=t2->up; t->right:=t2->right; free(t2); mine naaber;
// eemaldan 'goto'
- kui t2->sem≠suunam, siis
- t3:=t2->right; t1->truel:=IX; t2->label:=IX; IX:=IX+1;
- t1->falsel:=IX; t3->label:=IX; IX:=IX+1; mine naaber
- kui op=lugem, siis
- t1:=t->down; k:=0;
- S3: kuni k<itl
- kui ITk=t1->leks, siis
- id:=IDTk; mine lok
- k:=k+1; mine S3
- lok: id->io:=id->io Ú 1; Rd:=1; i:=i-1; mine naaber
- kui op=kirjut, siis
- t1:=t->down; k:=0;
- S4: kuni k<itl
- kui ITk=t1->leks, siis
- id:=IDTk; mine kok
- k:=k+1; mine S4
- kok: id->io:=id->io Ú 2; Wr:=1; i:=i-1; mine naaber
ok: return(N);
Genereerib .asm-programmi päise
int gen_header(void)
- muutujad: struct itr *id; int i,j; int id_nr=0;
- täidab "rea" nullidega: memset(rida,'\0',80);
sprintf(rida,"%s.asm",Pr_name);
- avab kirjutamiseks tekstifaili: rules:=fopen(rida, "w");
- blue("<BR><BR>Compiler to Assembler started<BR><BR>");
- green("; gen_header: source text<BR>");
- j:=0; i:=0;
- S1: kuni i<Plen
- ridaj:=PBufi; j:=j+1; kui PBufi='\n'), siis
- fprintf(rules,"; %s",rida);
- green("; %s",rida); j:=0;
- i:=i+1; mine S1
- fprintf(rules,";\n"); green(";<BR>");
- id_nr:=0; i:=0;
- S2: kuni i<itl
- id:=IDTi; kui id->t=Æ, siis id_nr:=id_nr+1;
- i:=i+1; mine S2
- fprintf(Logi,"<CODE><PRE><BIG>");
sprintf(rida,"; Program %s.asm\n",Pr_name);
- Put(rida); Put("\t.MODEL\tsmall\n"); Put("\t.STACK\t100h\n");
- sprintf(rida,"; gen_header: Rd=%d Wr=%d<BR>",Rd,Wr); green(rida);
- kui Rd=1, siis Put("\tEXTRN\treadint:PROC\n");
- kui Wr=1, siis Put("\tEXTRN\tbin2dec:PROC\n");
- kui id_nr>0, siis
- sprintf(rida,"; gen_header: # of identifiers=%d<BR>",id_nr);
- green(rida); Put("\t.DATA\n"); i:=0;
- S3: kuni i<itl
- id:=IDTi; kui id->t=Æ, siis
- sprintf(rida,"%s\tDW\t0\n",T[id->nr]); Put(rida);
- i:=i+1; mine S3
- kui tmarv>0, siis
- sprintf(rida,"; gen_header: # of workvariables=%d<BR>",tmarv); i:=0;
- S5: kuni i<tmarv
- sprintf(rida,"dTv%d\tDW\t0\n",i); Put(rida);
- i:=i+1; mine S5
- kui Rd=0 ja Wr=0siis mine code
- green("; gen_header: generate I/O-text<BR>");
- kui Rd=1, siis Put("Sisse\tDB\t'Input the variable ','$'\n");
- kui Wr=1, siis Put("Trykk\tDB\t'Variable ','$'\n");
- kui itl>0, siis i:=0
- S5: kuni i<itl
- id:=IDTi;
- kui id->t=Æ ja id->io≠0, siis
- sprintf(rida,"%s_S\tDB\t'%s=','$'\n",T[id->nr],T[id->nr]);
Put(rida);
- i:=i+1; mine S5
- code: green("; gen_header: code segment'll start<BR>");
- Put("\t.CODE\nProgramStart:\n");
- Put("\tmov\tax,@data\n");
- Put("\tmov\tds,ax\n");
- return(1);
Kompilaator: väljund- ja sisendoperaatorite ASM-tekstid (teek.asm)
Väljund:
; The Waite Group's MS-DOS Developer's Guide, Second Edition,
; John Angermeyer jt,Howard W. Sams & Company, 1989, pp 724-725
;
; bin2dec
; INPUT: AX - number to be displayed
; CH - minimum number of digits to be displayed
; DX = 0, if number is unsigned, 1, if signed
; OUTPUT None
;
;
.MODEL small
.STACK 100h
.DATA
.CODE
PUBLIC bin2dec
PUBLIC readint
;
bin2dec PROC NEAR
push ax
push bx
push cx
push dx
mov cl,0
mov bx,10
cmp dx,0
je more_dec
or ax,ax
jnl more_dec
neg ax
; @DisChr '-'
push ax
push dx
mov dl,'-'
mov ah,02h
int 21h
pop dx
pop ax
more_dec:
xor dx,dx
div bx
push dx
inc cl
or ax,ax
jnz more_dec
; Main Digit Print Loop - Reverse Order
sub ch,cl
jle morechr
xor dx,dx
morezero:
push dx
inc cl
dec ch
jnz morezero
morechr:
pop dx
add dl,30h
; DisChr
push ax
push dx
mov ah,02h
int 21h
pop dx
pop ax
dec cl
jnz morechr
pop dx
pop cx
pop bx
pop ax
ret
bin2dec ENDP
Sisend:
;
; vt. ka
; Turbo Assembler. Users Guide, Version 1.0, Borland International, 1989 p55;
; Angermayer et al, p.560
;
; readint
; INPUT: none
; OUTPUT AX - sisestatud ja teisendatud arv
;
;
readint PROC NEAR
push bx
push cx ;save
push dx ;registers; res=ax
xor ax,ax ;arv
ring: push ax ;save
mov ah,1 ;DOS keyboard input
int 21h ;get the next symbol
mov cl,al ;new digit in cl
sub cl,30h ;symbol->10nd-nr
cmp al,13 ;Enter?
jz oki ;valmis
pop ax ;senine arv
mov dx,10
mul dx ;senine arv * 10
xor ch,ch ;prepare for 16-bit add
add ax,cx ;new digit is added in
jmp ring
oki: mov dl,10 ;linefeed
mov ah,2 ;DOS display output
int 21h
pop ax
pop dx
pop cx
pop bx
ret
readint ENDP
END
Kirjutab logisse "sinise teate"
void blue(char *t){
fprintf(Logi,"<FONT COLOR=\"0000FF\">%s</FONT>",t);
}
Kirjutab logisse "rohelise teate"
void green(char *t){
fprintf(Logi,"<FONT COLOR=\"008000\">%s</FONT>",t);
}
Kirjutab teksti .asm-faili ja logisse
void Put(char *c)
- fprintf(rules,"%s",c);
- kui c0=';', siis fprintf(Logi,"<FONT COLOR=\"008000\">%s</FONT>",c);
- muidu fprintf(Logi,"%s",c);
Lihtkompilaator
void trigol_Asm(struct top *root)
- muutujad: struct top *t; int op; int i=0; int j;
- IX:=0; //töömuutuja index
- Label:=0; t:=root->down;
- down:
- kui t->label>0, siis Label:=t->label;
- kui t->down≠Æ, siis
- stacki:=leaf(t); i:=i+1; prist(i,0);
- naaber: kui t->up=Æ, siis
- t:=t->up; kui t=root, siis mine ok
- green(";compiling the operator ");
- print_Op(t); ps(); pp2html(t);
- kui Label≠0, siis w_label(Label);
- op:=t->sem; kui op≥pisem ja op≤vord, siis
- i:=logic(i,t); mine naaber
- kui op≥jag ja op≤liit, siis
- i:=Aritm(i,t); mine naaber
- kui op=omist, siis
- kui op=suunam, siis
- kui op=kuisiis, siis mine naaber
- kui op=tingop, siis mine naaber
- kui op=lugem, siis i:=InOut(i,t); mine naaber
- kui op=kirjut, siis i:=InOut(i,t); mine naaber
- prist: prist(i,0);
- mine naaber
- ok: Put("\tmov\tah,4ch\n"); //DOS terminate program f.
- Put("\tint\t21h\n"); //terminate the program
- Put("\tEND\tProgramStart\n");
- fflush(rules); fclose(rules);
- fprintf(Logi,
"<FONT COLOR=\"008000\">programm %s.asm is compiled<BR></FONT>",Pr_name);
Kompilaator: magasini mälu vabastamine
void freestack(int i,int k)
- muutujad: struct item *c;
- S1: kuni k>0
- c:=stacki-k; free(c); stacki-k:=Æ; k:=k-1;
- mine S1
Kompilaator: lehe töötlemine
struct item *leaf(struct top *t)
- muutujad: int k,op; struct item *s; struct itr *id; struct ctr *c;
- s:=make_item(); op:=t->sem;
- kui op=muut, siis
- s->liik:=1; k:=0;
- S1: kuni k<itl
- kui ITk=t->leks, siis
- k:=k+1; mine S1
- iok: s->id:=id;
- kui id->t≠Æ, siis
- märgend: s->liik:=3; s->t:=id->t;
- return(s);
- kui op=konst, siis
- s->liik:=2; k:=0;
- S2: kuni k<ktl
- kui KTk=t->leks, siis
- k:=k+1; mine S2
- cok: s->c:=c;
- return(s);
Märgendi kompileerimine
void w_label(int label)
- kui label>0, siis
- kui label>tnr, siis sprintf(rida,"%s:",T[label]);
- muidu sprintf(rida,"MExi%d:",label); Put(rida); Label:=0;
Kompilaator: võrdlustehted
int logic(int i, struct top *t)
- muutujad: int op;
- op:=t->sem; Put("\tmov\tax,");
- w_addr(i,2); Put("\n\tcmp\tax,"); w_addr(i,1); Put("\n");
- kui op=pisem, siis Put("\tjb\t"); mine free
- kui op=suurem, siis Put("\tgb\t"); mine free
- kui op=piv, siis Put("\tjbe\t"); mine free
- kui op=suv, siis Put("\tjge\t"); mine free
- kui op=pov, siis Put("\tjne\t"); mine free
- kui op=vord, siis Put("\tje\t");
- free: freestack(i,2); i:=i-2;
- kui t->truel>0, siis
- kui t->truel>tnr, siis sprintf(rida,"%s\n",T[t->truel]);
- muidu sprintf(rida,"MExi%d\n",t->truel); Put(rida);
- kui t->falsel>0, siis
sprintf(rida,"\tjmp\tMExi%d\n",t->falsel); Put(rida);
- return(i);
Kompilaator: aritmeetika
int Aritm(int i,struct top *t)
- muutujad: int op; struct item *s; struct top *t1;
- op:=t->sem; Put("\tmov\tax,"); w_addr(i,2);
- kui op=jag, siis
- kui op=korrut, siis
- Put("\n\tmov\tdx,"); w_addr(i,1); Put("\n")tmul\tdx\n"); Put("\n");
- Put("\tmul\tdx\n");mine free
- kui op=lahut, siis
- kui op=liit, siis
- free: freestack(i,2);
- kui opt=1, siis
- t1:=t->up; kui t1->sem=omist, siis
- i:=i-2; nado:=1; return(i);
- makeitem:
- s:=make_item(); s->liik:=0; s->index:=IX;
- stacki-2:=s; sprintf(rida,"\tmov\tdTv%d,ax\n",IX); Put(rida);
- IX:=IX+1; i:=i-1; return(i);
Kompilaator: magasini elemendi mälueraldus
struct item *make_item(void)
- muutujad: struct item *c;
- c:=(struct item *)malloc(sizeof(struct item));
- memset(c,'\0',sizeof(struct item));
- return(c);
Kompilaator: aadressi genereerimine
void w_addr(int i,int k)
- muutujad: struct item *s; struct ctr *c; struct itr *id;
- s:=stacki-k;
- kui s->liik=0, siis
- sprintf(rida,"dTv%d",s->index); Put(rida); IX:=IX-1;
- kui s->liik=1, siis
- id:=s->id; sprintf(rida,"%s",T[id->nr]); Put(rida);
- kui s->liik=2, siis
- c:=s->c; sprintf(rida,"%s",T[c->nr]); Put(rida);
- kui s->liik=3, siis
- id:=s->id; sprintf(rida,"%s",T[id->nr]); Put(rida);
- kui s->liik=4, siis
- sprintf(rida,"%d",s->index); Put(rida); IX:=IX-1;
Kompilaator: omistamine
int Assign(int i)
Kompilaator: sisend- ja väljundoperaatorid
int InOut(int i, struct top *t)
- muutujad: struct item *s; struct itr *id; int op, x;
- s:=stacki-1; id:=s->id; x:=strlen(T[id->nr]);
- Put("\tmov\tah,9h\n"); Put("\tmov\tbx,1\n");
- op:=t->sem;
- kui op=lugem, siis
- Put("\tmov\tcx,17\n");
- Put("\tmov\tdx,OFFSET Sisse\n");
- Put("\tint\t21h\n");
- Put("\tmov\tah,9h\n");
- Put("\tmov\tbx,1\n");
- sprintf(rida,"\tmov\tcx,%d\n",x+1); Put(rida);
- sprintf(rida,"\tmov\tdx,OFFSET %s_S\n",T[id->nr]); Put(rida);
- Put("\tint\t21h\n");
- Put("\tcall\treadint\n");
- Put("\tmov\t"); w_addr(i,1);
- Put(",ax\n");
- mine free
- kui op=kirjut, siis
- Put("\tmov\tcx,8\n");
- Put("\tmov\tdx,OFFSET Trykk\n");
- Put("\tint\t21h\n");
- Put("\tmov\tah,9h\n");
- Put("\tmov\tbx,1\n");
- sprintf(rida,"\tmov\tcx,%d\n",x+1); Put(rida);
- sprintf(rida,"\tmov\tdx,OFFSET %s_S\n",T[id->nr]); Put(rida);
- Put("\tint\t21h\n");
- sprintf(rida,"\tmov\tax,%s\n",T[id->nr]);
- Put(rida);
- Put("\tmov\tdx,0\n");
- Put("\tcmp\tax,0\n");
- Put("\tjg\ts1h2o3w\n");
- Put("\tmov\tdx,1\n");
- Put("s1h2o3w:\n");
- Put("\tmov\tch,1\n");
- Put("\tcall\tbin2dec\n");
- free: freestack(i,1); i:=i-1; return(i);
Optimiseeriv kompilaator
void trigol_Asm_O(struct top *root)
- muutujad: int op; int i=0; int j;
- IX:=0; // töömuutuja indeks
- Label:=0; t:=root->down;
- down: kui t->label>0, siis Label:=t->label;
- kui t->down≠Æ, siis
- stacki:=leaf(t); i:=i+1; prist(i,0);
- naaber: kui t->up=Æ, siis
- t:=t->up; kui t=root, siis mine ok
- green("; compiling the operator "); print_Op(t); ps(); pp2html(t);
- kui Label≠0, siis w_label(Label); op:=t->sem;
- kui op≥pisem ja op≤vord, siis
- j:=i; i:=LogicO(i,t); kui i=j, siis i:=logic(i,t); mine naaber
- kui op≥jag ja op≤liit, siis
- j:=i; i:=AritmO(i,t); kui i=j, siis i:=Aritm(i,t); mine naaber
- kui op=omist, siis i:=Assign(i); mine prist
- kui op=suunam, siis
- kui op=kuisiis, siis mine prist
- kui op=tingop, siis mine prist
- kui op=lugem, siis i:=InOut(i,t); mine prist
- kui op=kirjut, siis i:=InOut(i,t); mine prist
- prist: prist(i,0);
- mine naaber;
- ok:
- Put("\tmov\tah,4ch\n"); // DOS terminate program f.
- Put("\tint\t21h\n"); // terminate the program
- Put("\tEND\tProgramStart\n");
- fflush(rules); fclose(rules);
- fprintf(Logi,
"<FONT COLOR=\"008000\">programm %s.asm is compiled<BR></FONT>",Pr_name);
Optimiseeriv kompilaator: võrdlustehted
int LogicO(int i, struct top *t)
- struct item *s1,*s2; struct ctr *c; int op,r,x,y;
- s1:=stacki-2; s2:=stacki-1;
- kui (s1->liik=2 või s1->liik=4) ja (s2->liik=2 või s2->liik=4), siis
- green("constant expression, I'll optimize..<BR>"); r:=0;
- kui s1->liik=2, siis
- kui s1->liik≠2, siis
- x:=s1->index; kui s2->liik=2, siis
- kui s1->liik=2, siis y:=s2->index; op:=t->sem;
- kui op=pisem, siis
- kui x<y, siis r:=1;
- fprintf(Logi,
"<FONT COLOR=\"008000\">%d < %d ?<BR></FONT>",x,y);
- kui op=suurem, siis
- kui x>y, siis r:=1;
- fprintf(Logi,
"<FONT COLOR=\"008000\">%d > %d ?<BR></FONT>",x,y);
- kui op=piv, siis
- kui x≤y, siis r:=1;
- fprintf(Logi,
"<FONT COLOR=\"008000\">%d ≤ %d ?<BR></FONT>",x,y);
- kui op=suv, siis
- kui x≥y, siis r:=1;
- fprintf(Logi,
"<FONT COLOR=\"008000\">%d ≥ %d ?<BR></FONT>",x,y);
- kui op=pov, siis
- kui x≠y, siis r:=1;
- fprintf(Logi,
"<FONT COLOR=\"008000\">%d /= %d ?<BR></FONT>",x,y);
- kui op=vord, siis
- kui x≠y, siis r:=1;
- fprintf(Logi,
"<FONT COLOR=\"008000\">%d = %d ?<BR></FONT>",x,y);
- freestack(i,2); i:=i-2; kui r=1, siis
- kui t->truel>tnr, siis
- sprintf(rida,"\tjmp\t%s\n",T[t->truel]); Put(rida);
- muidu
- return(i);
Optimiseeriv kompilaator: aritmeetikatehted
int AritmO(int i,struct top *t)
- muutujad: struct item *s1,*s2; struct ctr *c; int op,r,x,y;
- s1:=stacki-2; s2:=stacki-1;
- kui (s1->liik=2 või s1->liik=4) ja (s2->liik=2 või s2->liik=4), siis
- green("constant expression, I'll optimize..<BR>"); r:=0;
- muidu x:=s1->index;
- kui s2->liik=2, siis
- muidu y:=s2->index;
- op:=t->sem;
- kui op=jag, siis
- r:=x/y; fprintf(Logi,
"<FONT COLOR=\"008000\">%d = %d / %d<BR></FONT>",r,x,y);
- mine S1
- kui op=korrut, siis
- r:=x*y; fprintf(Logi,
"<FONT COLOR=\"008000\">%d = %d * %d<BR></FONT>",r,x,y);
- mine S1
- kui op=lahut, siis
- r:=x-y; fprintf(Logi,
"<FONT COLOR=\"008000\">%d = %d - %d<BR></FONT>",r,x,y);
- mine S1
- kui op=liit, siis
- r:=x+y; fprintf(Logi,
"<FONT COLOR=\"008000\">%d = %d + %d<BR></FONT>",r,x,y);
- S1: s1->liik:=4; s1->index:=r; freestack(i,1); i:=i-1;
- return(i);
Terminaalse tähestiku koostamine
int Terms(void)
- muutujad: int i,l,mid,left; char k; int res=0;
- i:=0; left:=0; olek:=0; mid:=0;
- nstate: memset(word,'\0',20); l:=0;
- loop: kui i≥Glen, siis mine out;
//Glen on produktsioonide faili GBuf pikkus
- kui GBufi='\t', siis i:=i+1 ja mine loop
- kui olek=0, siis
- //produktsiooni vasak pool
- kui GBufi='-', siis
- olek:=1; mid:=0; mine nstate
- kui GBufi=' ', siis i:=i+1 ja mine loop
- kui GBufi='`', siis
- kui left=1, siis viga(i) ja res:=1;
- left:=1; i:=i+1; mine loop
- kui GBufi='\', siis
- mid:=0; olek:=1; i:=i+1; mine nstate
- i:=i+1; mine loop
- kui olek=1, siis
- //vasaku ja parema poole eraldaja
- kui GBufi=' ', siis i:=i+1 ja mine loop
- kui GBufi='-', siis
- kui mid=0, siis
- mid:=1; i:=i+1; mine loop
- kui mid=1, siis
- viga(i); i:=i+1; res:=1; mine loop
- kui GBufi='>', siis
- kui mid=0, siis
- i:=i+1; viga(i); i:=i+1; res:=1; mine loop
- kui mid=1, siis
- i:=i+1; olek:=2; mine nstate
- kui olek=2, siis
- //produktsiooni parem pool
- kui GBufi=' ', siis i:=i+1 ja mine loop
- kui GBufi='`', siis
- olek:=3; i:=i+1; mine nstate
- kui GBufi='\n', siis //'\n' on reavahetuse kood
- left:=0; olek:=0; i:=i+1; mine nstate
- k:=GBufi; kui isgraph(k), siis olek:=4; ja mine nstate
- viga(i); i:=i+1; res:=1; mine loop
- kui olek=3, siis
- //mitteterminali töötlemine
- k:=GBufi; kui isalnum(k), siis i:=i+1 ja mine loop
- kui GBufi='`', siis
- viga(i); i:=i+1; res:=1; mine loop
- kui GBufi='\', siis
- i:=i+1; left:=0; olek:=2; mine nstate
- kui GBufi='', siis i:=i+1 ja mine loop
- viga(i); i:=i+1; res:=1; mine loop
- kui olek=4, siis
- //terminali töötlemine
- kui GBufi='`', siis
- term(l,0); olek:=2; mine nstate
- k:=GBufi; kui isgraph(k), siis
- word[l]:=GBuf[i]; i:=i+1; l:=l+1; mine loop
- kui GBufi=' ', siis
- i:=i+1; term(l,0); olek:=2; mine nstate
- kui GBufi='\n', siis
- i:=i+1; term(l,0); olek:=0; left:=0; mine nstate
- out: return(res);
Tähestiku V moodustamine: veateade
void viga(int i)
- int j;
- fprintf(Logi,
"error in grammar: nr of symbol=%d GrammarLength=%d<BR>",i,Glen);
for(j=0;j<i;j++) fprintf(Logi,"%c",GBuf[j]);
fprintf(Logi,"%c",sk);
while(i<Glen){
fprintf(Logi,"%c",GBuf[i]);
i++;
}
fprintf(Logi,"<BR>");
}
Terminal tähestikku V (flag=0) või definitsiooni (flag=1)
void term(int l,int flag)
- muutujad: struct D *t;
- DC:=newD();
- DC->tunnus:=1; DC->L:=l; t:=search(1);
- kui t->code=0, siis
- tnr:=tnr+1; t->code:=tnr; memcpy(T[tnr],word,20);
- kui flag=1, siis defdl:=t->code ja dl:=dl+1
Eraldab mälu uuele tipule tähestiku V puusse
struct D *newD(void)
- muutuja: struct D *ptr;
- ptr:=(struct D *)malloc(sizeof(struct D));
- kui ptr=Æ, siis
- sprintf(rida,"newD: I don't have memory enaugh..");
- ExiT(rida);
- memset(ptr,'\0',sizeof(struct D)); ptr->left=(struct D *)NULL;
- ptr->right=(struct D *)NULL; ptr->def=(struct R *)NULL; return(ptr);
Avarii
void ExiT(char *t)
fprintf(Logi,"%s<BR>",t);
fprintf(Logi,"<"/BODY><"/HTML>");
fflush(Logi);
fclose(Logi);
printf("%s",t);
getchar();
abort();
}
Tähestiku V elemendi otsimine/lisamine (x=1), otsimine (x=0)
struct D *search(int x)
- muutuja: struct D *t; int res;
- t:=DT; kui t=Æ, siis
- kui x=0, siis mine exit
- DT:=DC; t:=DC; mine out
- ring: kui t->loc=0, siis res:=strcmp(word,T[t->code]);
- muidu res:=strcmp(word,T[t->loc]);
- kui res=0, siis mine out
- kui res<0, siis
- kui t->left≠Æ, siis t:=t->left ja mine ring
- kui x=0, siis mine exit
- t->left:=DC; t:=DC; mine out
- kui res>0, siis
- kui t->right≠Æ, siis t:=t->right ja mine ring
-
kui x=0, siis mine exit
- t->right:=DC; t:=DC; mine out
- mine out
- exit: t:=Æ
- out: return(t);
Eraldab mälu uuele NT-definitsioonile
struct R *newR(void)
- muutuja: struct R *ptr;
- ptr:=(struct R *)malloc(sizeof(struct R));
- kui ptr=Æ, siis
- sprintf(rida,"newR: I don't have memory enaugh..");
- ExiT(rida);
- memset(ptr,'\0',sizeof(struct R)); ptr->alt:=Æ
- return(ptr);
Mitteterminaalse tähestiku ja produktsioonide hulga koostamine
int Rules(void)
- muutujad: int i,l,mid,left; char k; int res=0;
- i:=0; left:=0; olek:=0; mid:=0;
- nstate:memset(word,'\0',20); l:=0;
- loop: kui i≥Glen, siis return(0);
//Glen on produktsioonide faili GBuf pikkus
- kui GBufi='\t', siis i:=i+1 ja mine loop
- kui olek=0, siis
- //produktsiooni vasak pool
- kui GBufi='-', siis
- olek:=1; mid:=0; mine nstate
- kui GBufi=' ', siis i:=i+1 ja mine loop
- kui GBufi='`', siis
- kui left=1, siis viga(i), i:=i+1 ja res:=1;
- left:=1; i:=i+1; mine loop
- kui GBufi='\', siis
- mid:=0; olek:=1; i:=i+1; DL:=leftside(l); left:=0; mine nstate
- k:=GBuf[i];kui isalnum(k), siis
- wordl:=GBufi; l:=l+1; i:=i+1; mine loop
- muidu
- viga(i); i:=i+1; res:=1; mine loop
- kui olek=1, siis
- //vasaku ja parema poole eraldaja
- kui GBufi=' ', siis i:=i+1 ja mine loop
- kui GBufi='-', siis
- kui mid=0, siis
- mid:=1; i:=i+1; mine loop
- kui mid=1, siis
- viga(i); i:=i+1; res:=1; mine loop
- kui GBufi='>', siis
- kui mid=0, siis
- i:=i+1; viga(i); i:=i+1; res:=1; mine loop
- kui mid=1, siis
- i:=i+1; kui GBufi='\t', siis
- i:=i+1; olek:=2; mine nstate
- kui olek=2, siis
- //produktsiooni parem pool
- kui GBufi=' ', siis i:=i+1 ja mine loop
- kui GBufi='`', siis
- olek:=3; i:=i+1; mine nstate
- kui GBufi='\n', siis //'\n' on reavahetuse kood
- makerul() left:=0; olek:=0; i:=i+1; mine nstate
- k:=GBufi; kui isgraph(k), siis olek:=4; ja mine nstate
- viga(i); i:=i+1; res:=1; mine loop
- i:=i+1; mine loop
kui olek=3, siis
- //mitteterminali töötlemine
- k:=GBufi; kui isalnum(k), siis
- wordl:=GBufi; i:=i+1 l:=l+1; mine loop
- kui GBufi='`', siis
- viga(i); i:=i+1; res:=1; mine loop
- kui GBufi='\', siis
- nonterm(l); i:=i+1; left:=0; olek:=2; mine nstate
- kui GBufi=' ', siis i:=i+1 ja mine loop
- viga(i); i:=i+1; res:=1; mine loop
kui olek=4, siis
- //terminali töötlemine
- kui GBufi='`', siis
- term(l,1); olek:=2; mine nstate
- k:=GBufi; kui isgraph(k), siis
- word[l]:=GBuf[i]; i:=i+1; l:=l+1; mine loop
- kui GBufi=' ', siis
- i:=i+1; term(l,1); olek:=2; mine nstate
- kui GBufi='\n', siis
- i:=i+1; term(l,1); makerul(); olek:=0; left:=0; mine nstate
out: return(res);
Produktsiooni "vasaku poole" salvestamine
struct D *leftside(int l)
- muutujad: struct D *t; dl:=0;
- DC:=newD(); DC->L:=l; DL:=DC;
- t:=search(1); memset(def,'\0',20);
- kui t->code=0. siis
- nr:=nr+1; t->code:=nr; memcpy(T[nr],word,l+1); return(t);
Terminal tähestikku V (flag=0) või definitsiooni (flag=1)
void term(int l,int flag)
- muutuja: struct D *t;
- DC:=newD(); DC->tunnus:=1; DC->L:=l;
- t:=search(1);
- kui t->code=0, siis
- tnr:=tnr+tnr+1; t->code:=tnr; memcpy(T[tnr],word,20);
- kui flag=1, siis defdl:=t->code ja dl:=dl+1;
Kirjutab mitteterminali koodi definitsiooni
void nonterm(int l)
- muutuja: struct D *t;
- DC:=newD(); DC->L:=l; t:=search(1);
- kui t->code=0, siis
- nr:=nr+1; kui nr>HTL, siis
- sprintf(rida,"too many symbols: nr=%d limes=%d<BR>",nr,HTL);
- ExiT(rida);
- t->code:=nr; memcpy(T[nr],word,l+1);
- defdl:=t->code; dl:=dl+1;
Produktsiooni moodustamine ja salvestamine
void makerul(void)
- muutujad: struct R *r; int i;
- r:=newR(); r->P:=Pnr; Pnr:=Pnr+1; r->n:=dl;
- r->d:=(int *)malloc(dl*sizeof(int));
- kui r->d=Æ, siis
- sprintf(rida,"makerul: I don't have memory<BR>"); ExiT(rida);
- for(i=0;i<dl;i++) r->d[i]=def[i];
- for(i=0;i<20;i++) def[i]=0;
- r->alt:=DL->def; DL->def:=r; dl:=0;
MENÜÜD (Menus)
Grammar
Grammatikaid on süsteemis kolme liiki: õppegrammatikad prefiksiga "g",
triviaalse interpreteeritava ja kompileeritava keele "tri" (edasiarendatud
variant on "trinew") ja mitte-programmeerimiskeele grammatika "form8". Allpool
näitame tabelis, millised on nende grammatikate omadused Konstruktori
vaatevinklist.
| Grammatika | eelnevusgrammatika? | pööratav? |
analüüsitavus | kommentaar |
| G1 | jah | jah | on | |
| G2 | jah | jah | on | |
| G3 | ei | jah | on | |
| G4 | ei | ei | pole | |
| G5 | jah | jah | on | |
| G6 | jah | ei | pole | |
| G7 | jah | ei | BRC(1|1) | |
| G8 | jah | ei | BRC(1,1) | |
| G9 | ei | ei | BRC(1,1) | |
| G10 | ei | ei | BRC(1,1) | |
| G11 | jah | ei | pole | |
| G12 | jah | ei | BRC(1,1) | |
| G13 | ei | ei | pole | |
| G15 | ei | jah | on | |
| G17 | jah | ei | pole | |
| G26 | jah | ei | BRC(1,1) | |
| G41 | ei | ei | BRC(1|1) | G4 juurdetoodud kontekstiga |
| G100 | jah | ei | pole | |
| G101 | jah | ei | BRC(1|1) | |
| Ga33 | jah | ei | BRC(1|1) | LL(k)-grammatika |
| Form8 | jah | ei | BRC(1,1) | |
| Tri | jah | ei | BRC(1|1) | |
| Trinew | jah | ei | BRC(1|1) | |
Standardsest failivalikuaknast saate valida grammatika; selle teksti
näitab Wordpad, edasi võite jatkata kas Konstruktoriga (kui olite
grammatikat muutnud) või vastava grammatikateklassi analüsaatoriga (selleks
peate valima grammatika poolt defineeritud keele sõna) või vaadata eelmise
seansi genereeritud väljundfaile (valides menüüst "Look at" ja "Files").
Constructor
Eelnevalt peab olema valitud grammatika; Konstruktori töö käiku ja resultaate
saate vaadata väljundfailist xxx.htm, kus xxx on grammatika laiendita nimi.
Learning
See menüüvalik võimaldab valida ühe õppegrammatika ¾ kas siis
analüsaatori käivitamiseks või võimaldamaks vaadata eelmise
seansi resultaate (valides "Look at" ja "Files").
- Word
Avatakse failivaliku aken ja võimaldatakse valida analüüsitav sõna.
- Parser
Käivitatakse analüsaator analüüsimaks valitud sõna.
Trigol
Võimaldatakse juurdepääs *.tri-programmide valiku menüüväljale
ning Konstruktori tabelitele (valides "Look at" ja "Files").
- Program
Avatakse failivaliku aken ja võimaldatakse valida
analüüsitav Trigol-programm.
- Interpreter
See valik käivitab valitud tri-programmi interpretaatori.
- Compiler
See valik käivitab valitud tri-programmi "lihtkompilaatori".
- Opt. compiler
See valik käivitab valitud tri-programmi optimiseeriva kompilaatori.
- Parser
See valik käivitab valitud tri-programmi analüsaatori, võimaldamaks
hilisemat interpreteerimist või kompileerimist.
Formula
Võimaldatakse juurdepääs *.frm-sõnade valiku menüüväljale
ning Konstuktori tabelitele (valides "Look at" ja "Files").
- Formula
Avatakse failivaliku aken ja võimaldatakse valida analüüsitav Form8-keelne
sõna.
- Translate
See valik käivitab valitud Form8-sõna interpretaatori (pole praegu
süsteemi lülitatud).
- Parser
See valik käivitab valitud Form8-sõna analüsaatori, võimaldamaks hilisemat
interpreteerimist.
Look at
See valik võimaldab vaadata nii genereeritud väljundfaile, süsteemsete
C-programmide tekste, TTSi header-faili ja kõikide grammatikate tekste.
- Files
See valik võimaldab vaadata eelneva(te) lahendus(t)e resultaate:
olgu grammatika nimi xxx.grm ja/või analüüsitava sõna nimi yyy.grm,
siis saate vaadata järgmisi väljundfaile:
| Konstruktor | näidatakse |
| xxx.grm | produktsioonide fail |
| xxx.htm | Konstruktori logi |
| xxx.sem | semantika-tekstifail |
| xxxrd.htm | "Reaalsed" Konstruktori tabelid |
| Analüsaator | näidatakse |
| yyy.xxx | Analüüsitav sõna/programm |
| yyyp.htm | Analüsaatori logi |
| yyyrd.htm | "Reaalsed" Analüsaatori tabelid |
| Trigol-interpretaator | näidatakse |
| yyyi.htm | Interpretaatori logi |
| Trigol-kompilaatoraator | näidatakse |
| yyyc.htm | Kompilaatori logi |
| yyyoc.htm | Optimiseeriva Kompilaatori logi |
| yyy.asm | Genereeritud assemblerprogrammi tekst |
- Constructor
Saate vaadata Konstruktori C-teksti (wcr32.c).
- Parser
Saate vaadata Analüsaatori C-teksti (parser32.c).
Tri Interpreter
Saate vaadata Tri-interpretaatori C-teksti (int32.c).
Tri Compiler
Saate vaadata Tri-Kompilaatori C-teksti (cmp32.c).
Main
Saate vaadata TTSi põhiprogrammi C-teksti (two.cpp).
Header
Saate vaadata TTSi header-faili teksti (two32.h).
Grammars
Saate vaadata kõikide süsteemsete grammatikate tekste (*.grm).
Help
Saate vaadata käesolevat teksti (help.htm).