Tänases praktikumis
Eelmisel korral
- Tingimuslikud otsustuspuud
- Otsustuspuude visualiseerimine
Sel korral
- Otsustuspuude headuse näitajad
- Juhumetsad (random forests)
- Juhumetsade visualiseerimine
Otsustuspuude headuse näitajad
Nii, nagu logistilises regressiooniski, ennustab otsustuspuu sisuliselt igale teatud omadustega vaatlusele mingi uuritava tunnuse klassi või keskväärtuse, mille põhjalt saab hinnata mudeli sobivust päris andmetega.
Kategoriaalne uuritav tunnus
Vaatame eelmises praktikumis tehtud otsustuspuud, mis ennustab hulga seletavate tunnuste põhjal asesõna mina/ma esinemise tõenäosust koos tegusõnaga.
load("isik1suur.RData")
library(partykit)
isik1suur$Sone <- gsub("['#()\\*\\.`]", "", isik1suur$Sone)
isik1suur$Sonepikkus <- nchar(isik1suur$Sone)
# Teeme puumudeli
puu2 <- ctree(Pron ~ Lopp + Aeg + Sonepikkus + Ref_kaugus_num + Verbiklass + Murre,
data = isik1suur,
control = ctree_control(minbucket = 200, alpha = 0.01))
# Visualiseerime puud
plot(puu2, gp = gpar(fontsize = 8))
Nagu logistilises regressioonis, saame ka kategoriaalse uuritava tunnusega puumudeli puhul hinnata mudeli headust klassifitseerimistäpsuse abil (vt 13. praktikumi materjale).
# Mudeli ennustatud klassid
# Puumudeli puhul saab funktsiooniga predict()
# vaikimisi kohe ennustatud klassid, mitte tõenäosused.
# Klassi kohal olev number näitab selle lehe/lõpusõlme
# numbrit, kuhu vaatlus on klassifitseeritud.
enn <- predict(puu2)
head(enn)
## 23 15 23 21 21 21
## jah jah jah ei ei ei
## Levels: ei jah
# Vaatluste tegelikud uuritava tunnuse klassid
teg <- isik1suur$Pron
head(teg)
## [1] ei ei ei ei ei ei
## Levels: ei jah
# Ennustatud ja tegelike klasside risttabel
t <- table(enn, teg)
t
## teg
## enn ei jah
## ei 1041 511
## jah 852 1662
# Klassifitseerimistäpsus
(klass <- (t["jah", "jah"]+t["ei", "ei"])/sum(t)) # klassifitseerimistäpsus
## [1] 0.6647811
# või ka sum(diag(t))/sum(t)Meie puumudel ennustab ~66% juhtudest vaatlusele õige uuritava tunnuse klassi. See on pisut parem kui ilma seletavate tunnusteta kõikidele vaatlustele lihtsalt sagedamat klassi ennustades (~53%).
Binaarse uuritava tunnuse puhul saab leida ka C-indeksi/AUC, mis hindab mudeli eristusvõimet mitte ennustatud klasside, vaid tõenäosuste põhjal. Kuna nüüd on meil vaja tõenäosusi, lisame funktsiooni predict() argumendi type = "prob". See annab meile iga vaatluse jaoks ennustatud “ei” ja “jah” klassi tõenäosused (kokku annavad 1).
head(predict(puu2, type = "prob"))
## ei jah
## 23 0.4003067 0.5996933
## 15 0.4045455 0.5954545
## 23 0.4003067 0.5996933
## 21 0.6542553 0.3457447
## 21 0.6542553 0.3457447
## 21 0.6542553 0.3457447C-indeksi arvutamiseks vajame sellest tabelist ainult ühe klassi tõenäosusi (“jah”).
library(Hmisc)
# Leiame puumudeli ennustatud tõenäosused
enn_probs <- predict(puu2, type = "prob")[,"jah"]
head(enn_probs)
## 23 15 23 21 21 21
## 0.5996933 0.5954545 0.5996933 0.3457447 0.3457447 0.3457447
# Teisendame uuritava tunnuse tegelikud väärtused
# samuti tõenäosusteks 0 ("ei") ja 1 ("jah")
teg_probs <- as.numeric(isik1suur$Pron)-1
# Sama, mis nt (isik1suur[["Pron"]] == "jah") + 0
# C-indeks
somers2(enn_probs, teg_probs)["C"]
## C
## 0.7158212Kuna meie C väärtus on veidi suurem kui 0.7, võime lugeda mudeli eristusvõimet rahuldavaks.
Kui uuritaval tunnusel rohkem kui 2 klassi, on AUC kasutamine pisut keerukam. On pakutud, et sellisel juhul võib leida eraldi AUC-väärtused kõikide tunnuse klasside paaride vahel ning seejärel võtta nende aritmeetiline keskmine. Selleks on R-is eraldi funktsiooon multiclass.roc() paketist pROC.
Arvuline uuritav tunnus
Arvulise uuritava tunnusega mudeli jaoks vaatame uuesti reaktsiooniaegade andmestikku.
library(partykit)
ldt <- read.csv("ldt.csv")
puu4 <- ctree(Mean_RT ~ Length + Freq, data = ldt)
plot(puu4, gp = gpar(fontsize = 8))
Üheks variandiks hinnata mudeli ligikaudset headust on leida mudeli ennustatud keskväärtuste ja tegelike vaatluste väärtuste vaheline korrelatsioon.
# Leia ennustatud reaktsiooniajad
enn <- predict(puu4)
head(enn)
## 7 7 4 4 9 9
## 855.6022 855.6022 786.9471 786.9471 989.8239 989.8239
# Tegelikud reaktsiooniajad
teg <- ldt$Mean_RT
head(teg)
## [1] 819.19 977.63 908.22 766.30 1125.42 948.33
# Ennustatud ja tegelike väärtuste korrelatsioon
cor(enn, teg)
## [1] 0.7026489Vaikimisi kasutab funktsioon cor() mäletatavasti Pearsoni korrelatsioonikordajat, mille kasutamise eelduseks on see, et tunnused on normaaljaotusega ning tunnuste vahel on lineaarne seos. Ehkki puumudelite hindamise puhul seda sageli ignoreeritakse ning lähtutakse Pearsoni kordajast kui ligikaudsest näitajast, võiksime siiski selle kasutamise eeldused üle kontrollida.
# Lineaarne seos?
library(ggplot2)
ggplot(data = data.frame(enn, teg),
aes(x = teg, y = enn)) +
geom_point(alpha = 0.5) +
geom_smooth() +
ggtitle("Ennustatud ja tegelikud väärtused")

shapiro.test(teg)
##
## Shapiro-Wilk normality test
##
## data: teg
## W = 0.92006, p-value = 1.418e-05
shapiro.test(enn)
##
## Shapiro-Wilk normality test
##
## data: enn
## W = 0.87098, p-value = 7.677e-08
# Aga logaritmides?
hist(log(teg))
hist(log(enn))
shapiro.test(log(teg))
##
## Shapiro-Wilk normality test
##
## data: log(teg)
## W = 0.97509, p-value = 0.05481
shapiro.test(log(enn))
##
## Shapiro-Wilk normality test
##
## data: log(enn)
## W = 0.88045, p-value = 1.897e-07Kuna meil ei ole tegemist päris lineaarse seosega ja logaritmimine lähendab normaaljaotusele ainult tegelike reaktsiooniaegade jaotust, siis oleks turvalisem kasutada headuse hindamisel ka kas Spearmani või Kendalli korrelatsioonikordajat.
cor(enn, teg, method = "spearman")
## [1] 0.7352883
cor(enn, teg, method = "kendall")
## [1] 0.6020279Selleks, et mitte üle hinnata mudeli headust, võiks kasutada konservatiivsemat Kendalli kordajat.
Selleks, et puumudeli (ligikaudset) headust võiks võrrelda ka nt lineaarse regressioonimudeli omaga, võib korrelatsioonikordaja põhjal leida mudeli poolt seletatud varieerumise protsendi R2.
Kui leiaksime R2 Pearsoni kordajaga, siis saaksime oluliselt parema tulemuse.
Teine variant jõuda sellesama Pearsoni-põhise R2-ni on lahutada 1st koguruutude summa (Total Sum of Squares) ja jääkide ruutude summa (Residual Sum of Squares) jagatis.
Otsustuspuude valideerimine
Tingimuslikud otsustuspuud on väga head tunnustevaheliste interaktsioonide visuaalseks vaatlemiseks, ent need ei ole kõige stabiilsemad mudelid ning võivad olla tundlikud sisendandmete suhtes. Kõikumised andmestikus võivad anda natuke teistsuguse lõpptulemuse, eriti väiksemate andmestike puhul.
Asendame näiteks esmalt 4066 vaatlusega 1. isiku andmestikus 300 juhuslikul vaatlusel pöördelõpu olemasolu pöördelõpu puudumisega.
# Teeme testimiseks ühe samasuguse lisaandmestiku
isik1suur_mod <- isik1suur
set.seed(1)
# Juhuslikult valitud ridade indeksid pöördelõpu asendamiseks
lopp <- sample(rownames(isik1suur_mod[isik1suur_mod$Lopp == "jah",]), 300, replace = FALSE)
# Asenda 300 "jah"-i "ei"-dega
isik1suur_mod[lopp,"Lopp"] <- "ei"
# Tee uus puu
puu_test <- ctree(Pron ~ Lopp + Aeg + Sonepikkus + Ref_kaugus_num + Verbiklass + Murre,
data = isik1suur_mod,
control = ctree_control(minbucket = 200,
alpha = 0.01))
plot(puu_test, gp = gpar(fontsize = 8))
Nüüd saame puu, milles kõige tugevam seletav tunnus on hoopiski tegusõna pikkus tähemärkides ja pöördelõpp saab oluliseks alles puu alumistes hargnemistes.
Selleks, et ühe puu põhjalt mitte liiga palju järeldada, tuleks mudelit valideerida. Valideerimiseks võib andmestiku jagada jällegi kaheks: treening- ja testandmeteks. Treeningandmetel tehtud mudeli ennustusi saab testida testandmetel funktsiooniga predict(puumudel, newdata = testandmestik) ning arvutada nende põhjalt mudeli täpsuse näitajad.
Teeme seda siin ilma puud trimmimata (st jätame määramata argumendid minbucket ja alpha).
# Võtame treeningandmestikku 70% originaalandmestiku vaatlustest
set.seed(100)
trenn_id <- sample(1:nrow(isik1suur), round(0.7*nrow(isik1suur)), replace = FALSE)
trenn <- isik1suur[trenn_id,]
test <- isik1suur[-trenn_id,]
puu_trenn <- ctree(Pron ~ Lopp + Aeg + Sonepikkus + Ref_kaugus_num + Verbiklass + Murre,
data = trenn)Mudeli täpsus treeningandmestikul:
enn_trenn <- predict(puu_trenn)
teg_trenn <- trenn$Pron
t_trenn <- table(enn_trenn, teg_trenn)
# klassifitseerimistäpsus
(klass_trenn <- (t_trenn["jah","jah"]+t_trenn["ei", "ei"])/sum(t_trenn))
## [1] 0.6799016
# library(Hmisc)
enn_probs_trenn <- predict(puu_trenn, type = "prob")[,"jah"]
teg_probs_trenn <- as.numeric(trenn$Pron)-1
somers2(enn_probs_trenn, teg_probs_trenn)["C"]
## C
## 0.7347267Mudeli täpsus testandmestikul:
enn_test <- predict(puu_trenn, newdata = test)
teg_test <- test$Pron
t_test <- table(enn_test, teg_test)
# klassifitseerimistäpsus
(klass_test <- (t_test["jah","jah"]+t_test["ei","ei"])/sum(t_test))
## [1] 0.6409836
# library(Hmisc)
enn_probs <- predict(puu_trenn, newdata = test, type = "prob")[,"jah"]
teg_probs <- as.numeric(test$Pron)-1
somers2(enn_probs, teg_probs)["C"]
## C
## 0.69541Antud juhul sobib mudel enam-vähem kirjeldama ka testandmestikku, ent kui headuse näitajad test- ja treeningandmestiku vahel on väga erinevad, siis võib proovida mudelit erinevate parameetrite abil trimmida (vt control = ctree_control()).
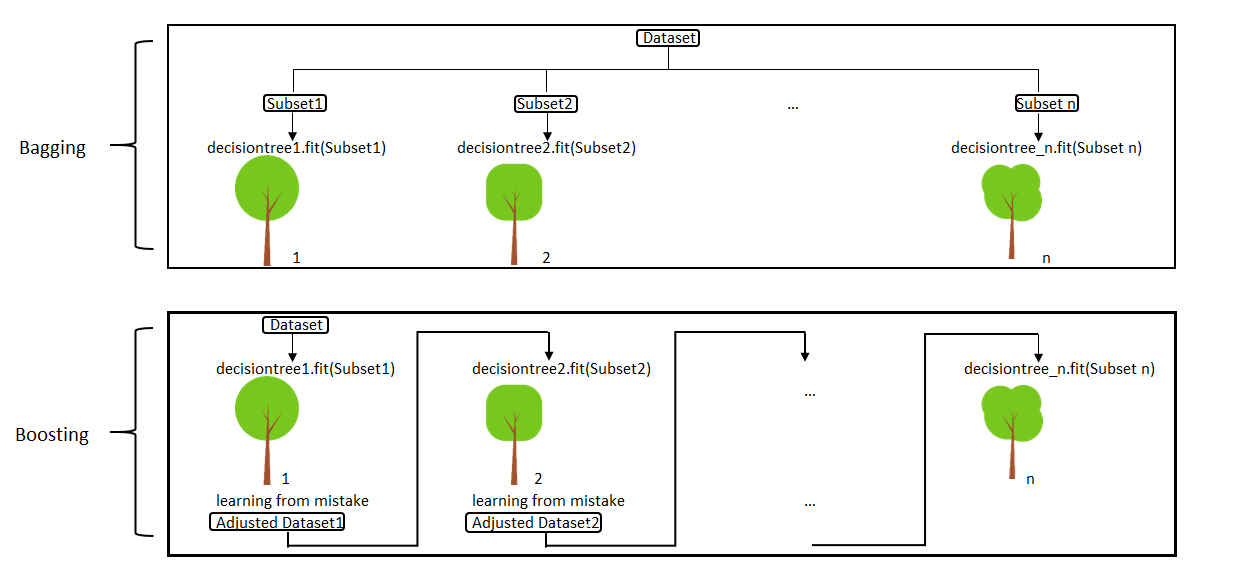
Teine variant ennustustes kindlamaks saamiseks on kasutada nn ansamblimeetodeid (ensemble methods), mis kasutavad sageli bootstrap-valimeid (vt 13. praktikumi materjale) ning milles lõplik ennustus uuritava tunnuse väärtustele üldistatakse mitmete üksikute mudelite põhjal. Ka ansamblimeetoditele on palju algoritme, põhilistena eristatakse nn bagging- ja boosting-algoritme.
- Bagging-algoritmides treenitakse paralleelselt mitut mudelit mitme üksteisest pisut erineva juhusliku valimi peal ning üldistatakse lõpuks nende mudelite ennustused.
- Boosting-algoritmides treenitakse mudeleid järjekorras ja iga järgmine mudel saab midagi eelmiselt mudelilt õppida.

Bagging ja boosting, https://miro.medium.com/max/2000/1*bUySDOFp1SdzJXWmWJsXRQ.png
Vaatame lähemalt nn juhumetsa meetodit (random forest), mis on bagging-algoritmi eritüüp.
Juhumets (random forest)
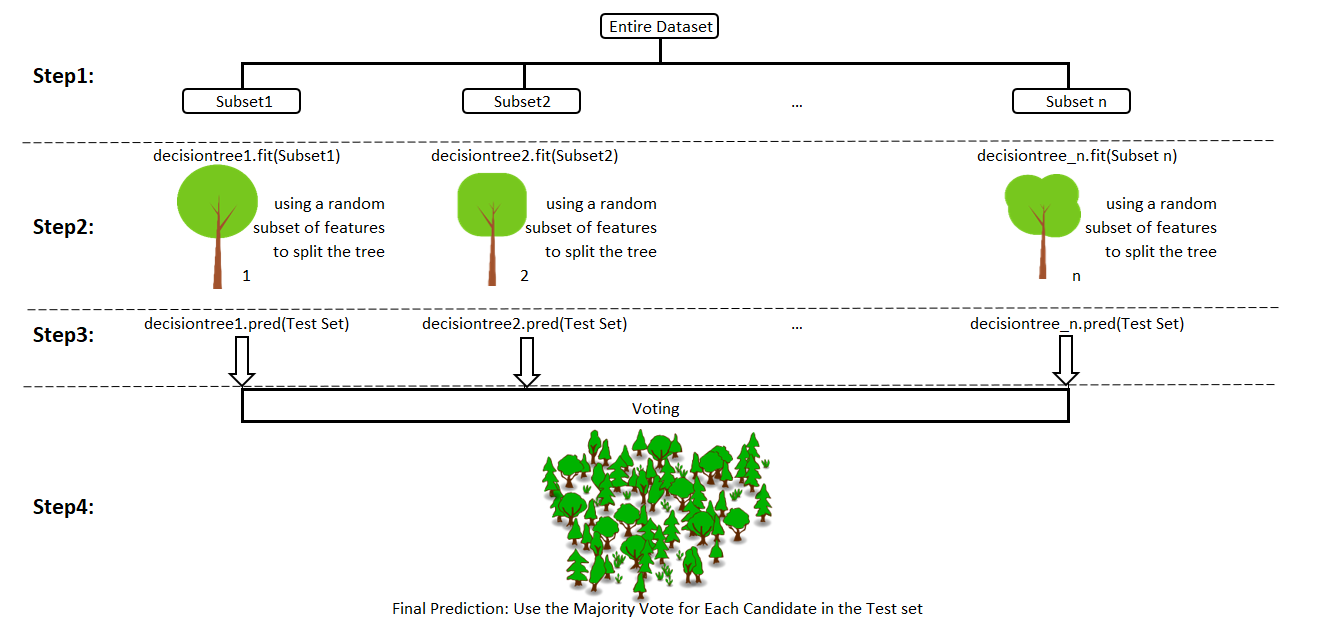
Juhumets (random forest) on mudel, mis üldistab oma ennustused terve hulga juhuslike puude põhjal. Juhuslikkus tuleneb sealjuures kahest asjaolust:
- andmestikust võetakse mingi hulk juhuslikke valimeid (kas bootstrap-valimeid ehk sama suuri valimeid, kus mõni vaatlus võib korduda, mõni aga jääb välja, või väiksemaid valimeid, milles vaatlused korduda ei või) ja sellest kasvatatakse puumudel. Vaatlused, mis valimisse ei satu, on nn out-of-bag ehk OOB-vaatlused. Iga puu võib teistest natuke erineda, sest tema aluseks olev valim on veidi erinev. See on tavaline bagging-algoritmi põhimõte;
- iga juhusliku puu igas sõlmes kaalutakse jagunemiseks juhuslikku hulka kõigist seletavatest tunnustest. See loob veelgi erinevamad puud ja annab hääle ka nõrgematele seletavatele tunnustele (kui mõni väga tugev tunnus, nt pöördelõpp esimese sõlme jagunemise valikusse ei satu). See on see, mille poolest juhumets tavalisest bagging’ust erineb.
Lõpliku ennustuse saamiseks puud “hääletavad” iga tegeliku vaatluse ennustatud klassi üle, kui uuritav tunnus on kategoriaalne, või keskmistavad tegeliku vaatluse ennustatud väärtust, kui uuritav tunnus on arvuline.
Out-of-bag vaatlused (iga juhusliku valimi puhul umbes kolmandik andmestikust) toimivad hiljem iga puu n-ö sisseehitatud testandmestikuna.

{kind=link}
{kind=link}
randomForest
Kasutame alustuseks funktsiooni randomForest() samanimelisest paketist. See on kõige põhilisem juhumetsade tegemise pakett, kuna on kasutajasõbralik, lihtne õppida ja arvutuslikult võrdlemisi kiire.
Paketi miinuseks on see, et puid vaikimisi ei trimmita ning need võivad ülesobitada. Samuti kalduvad puud eelistama sõlmedes arvulisi tunnuseid ja kategoriaalseid tunnused, millel on palju tasemeid. Selles paketis ei tehta niisiis tingimuslikke otsustuspuid, vaid tavalisi regressiooni- ja klassifikatsioonipuid (vt ka 14. praktikumi materjale).
Kuna juhumetsade mudelid sisaldavad juhuslikkust, tuleks tulemuste korratavuse huvides mudeldamisel alati määrata ka seeme (seed), mis tagab juhuslikkuses teatud fikseeritud seisu. Seemneks sobib mis tahes arv.
Argumendi importance lisamine võimaldab meil hiljem võrrelda tunnuste olulisust nii nende täpsuse kui ka klasside puhtuse suurendamise seisukohalt.
set.seed(100)
mets_rf <- randomForest(Pron ~ Lopp + Aeg + Sonepikkus + Ref_kaugus_num + Verbiklass + Murre,
data = isik1suur,
importance = TRUE)
class(mets_rf)
## [1] "randomForest.formula" "randomForest"
mets_rf
##
## Call:
## randomForest(formula = Pron ~ Lopp + Aeg + Sonepikkus + Ref_kaugus_num + Verbiklass + Murre, data = isik1suur, importance = TRUE)
## Type of random forest: classification
## Number of trees: 500
## No. of variables tried at each split: 2
##
## OOB estimate of error rate: 32.51%
## Confusion matrix:
## ei jah class.error
## ei 1234 659 0.3481247
## jah 663 1510 0.3051081Vaikimisi tehakse 500 puumudelit ja iga puu igas sõlmes katsetatakse jagunemiseks 2 juhuslikult valitud tunnust (enamasti on see arv ruutjuur seletavate tunnuste arvust, mille randomForest ümardab allapoole). Sellise metsa eksimismäär (OOB estimate of error rate) on 32.51%, mis tähendab, et klassifitseerimistäpsus on 100-32.51=67.49%.
randomForest’i mudel annab väljundis automaatselt ka õigete ja valede ennustuste risttabeli (ridades tegelikud vaatlused ning tulpades ennustatud klassid) ning lisaks iga klassi eksimismäära eraldi (class.error). See on kasulik, kuna vahel võib juhtuda, et mudel suudab ennustada väga hästi üht, aga mitte teist klassi.
Saame ennustuste põhjal leida jällegi ka C/AUC (binaarse uuritava tunnuse puhul).
# library(Hmisc)
# Leiame metsamudeli ennustatud tõenäosused
enn_probs <- predict(mets_rf, type = "prob")[,"jah"]
head(enn_probs)
## 1 2 3 4 5 6
## 0.8404255 0.5297619 0.6162791 0.2883436 0.2406417 0.4093264
# Teisendame uuritava tunnuse tegelikud väärtused
# samuti tõenäosusteks 0 ("ei") ja 1 ("jah")
teg_probs <- as.numeric(isik1suur$Pron)-1
# Sama, mis nt (isik1suur[["Pron"]] == "jah") + 0
head(teg_probs)
## [1] 0 0 0 0 0 0
# C-indeks
somers2(enn_probs, teg_probs)["C"]
## C
## 0.7295476Tunnuste olulisus
Tunnuste olulisust saab küsida metsamudelist funktsiooniga importance(), juhul kui randomForest()-funktsioonis on metsamudeli tegemisel eelnevalt täpsustatud argument importance = TRUE.
importance(mets_rf)
## ei jah MeanDecreaseAccuracy MeanDecreaseGini
## Lopp 12.162352 39.04112 54.60883 76.42651
## Aeg 14.208940 19.47413 29.29969 34.81483
## Sonepikkus 22.413315 18.69587 34.23355 122.08286
## Ref_kaugus_num 34.391337 28.44134 40.16023 158.56193
## Verbiklass 40.187576 29.32396 50.20105 80.76762
## Murre 3.330291 37.69204 43.99026 106.35963randomForest esitab tunnuste olulisust kahe mõõdiku järgi:
MeanDecreaseAccuracynäitab nn permutatsiooniolulisust ehk keskmist kahanemist klassifitseerimistäpsuses, kui konkreetset seletavat tunnust on kõikides puudes permuteeritud. Permuteerimine on protsess, kus- esmalt loetakse kokku selle seletava tunnuse osas õigesti klassifitseeritud vaatlused igas puus (ütleme, et see on mingi arv X). Näiteks pöördelõpu puhul vaadatakse, kui paljudel vaatlustel on pöördelõpu tegelik väärtus “jah” lehtedes, kus see mudeli järgi peaks nii olema, ning kui paljudel vaatlustel on tegelik väärtus “ei” lehtedes, kuhu mudel on ka “ei”-d ennustanud;
- seejärel võetakse OOB-vaatlused ja ajatakse nendes selle sama seletava tunnuse (nt pöördelõpu) väärtused segamini. Nii võivad vaatlused, millel algandmestikus on väärtus “jah”, saada väärtuseks “ei” ja vastupidi;
- igale segiaetud vaatlusele OOB-rühmas lastakse ennustada iga puu poolt klass/väärtus ja loetakse uuesti kokku õiged ennustused (see on nt mingi arv Y);
- esimesest arvust X lahutatakse teine arv Y ning arvutatakse siis kõikide puude keskmine. Mida rohkem sassiajamine tunnuses suurendas valesti klassifitseerimist, seda suurem on ka tunnuse olulisus.
MeanDecreaseGinipõhineb lehtede puhtusel ja Gini-informatsioonikriteeriumil, millest rääkisime juba ka otsustuspuude juures.
Gini-mõõdik kaldub eelistama arvulisi tunnuseid ja tunnuseid, millel on mitu taset. Näiteks on mets_rf mudelis selle põhjal kõige olulisemad kaks arvulist tunnust Sonepikkus ja Ref_kaugus_num ning kategoriaalne tunnus Murre, millel on tervelt 5 taset. Seega on parem tunnuste olulisuse hindamisel lähtuda permutatsiooniolulisusest, mis on vähem kallutatud.
importance()-funktsioon näitab vaikimisi z-skoore ehk jagab permutatsiooniolulisuse mõõdikud läbi nende standardvigadega. Vahel on soovitatud kasutada nn “tooreid”, standardiseerimata (scale = FALSE) olulisusmõõdikuid, kuna z-skoorid on tundlikumad valimi suuruse ja puude arvu suhtes.
# standardiseerimata mõõdikud
importance(mets_rf, scale = FALSE)
## ei jah MeanDecreaseAccuracy MeanDecreaseGini
## Lopp 0.023029938 0.07960069 0.05321072 76.42651
## Aeg 0.011612589 0.01439815 0.01309213 34.81483
## Sonepikkus 0.028056491 0.02000315 0.02372657 122.08286
## Ref_kaugus_num 0.027129401 0.02040484 0.02351673 158.56193
## Verbiklass 0.025790669 0.01812467 0.02167830 80.76762
## Murre 0.005805347 0.06337653 0.03649868 106.35963Tunnuste olulisust esitatakse tihtipeale ka graafikul. Paketil randomForest on selleks sisse-ehitatud funktsioon varImpPlot().


varImpPlot(mets_rf,
main = "Tunnuste permutatsiooniolulisus (standardiseerimata)",
scale = FALSE,
type = 1)
Tunnuste olulisust võib visualiseerida ka nt ggplot2-ga.
library(ggplot2)
# Tee olulisuse mõõdikutest andmetabel
df <- as.data.frame(importance(mets_rf, scale = FALSE))
head(df)
## ei jah MeanDecreaseAccuracy MeanDecreaseGini
## Lopp 0.023029938 0.07960069 0.05321072 76.42651
## Aeg 0.011612589 0.01439815 0.01309213 34.81483
## Sonepikkus 0.028056491 0.02000315 0.02372657 122.08286
## Ref_kaugus_num 0.027129401 0.02040484 0.02351673 158.56193
## Verbiklass 0.025790669 0.01812467 0.02167830 80.76762
## Murre 0.005805347 0.06337653 0.03649868 106.35963
# Joonista ggploti graafik
ggplot(data = df,
aes(x = rownames(df))) +
geom_bar(aes(y = MeanDecreaseAccuracy),
stat = "identity") +
scale_x_discrete(limits = c("Aeg", "Verbiklass", "Ref_kaugus_num", "Sonepikkus", "Murre", "Lopp")) +
labs(x = "",
title = "Tunnuste permutatsiooniolulisus juhumetsa mudelis",
subtitle = "(standardiseerimata)",
caption = "R-i paketiga randomForest") +
coord_flip()
# Teistsugune graafik
ggplot(data = df,
aes(x = rownames(df), y = MeanDecreaseAccuracy)) +
geom_point(aes(fill = MeanDecreaseAccuracy), size = 4, shape = 22, show.legend = FALSE) +
scale_x_discrete(limits = c("Aeg", "Verbiklass", "Ref_kaugus_num", "Sonepikkus", "Murre", "Lopp")) +
scale_fill_gradient(low = "steelblue4", high = "tomato2") +
labs(x = "",
title = "Tunnuste permutatsiooniolulisus juhumetsa mudelis",
subtitle = "(standardiseerimata)",
caption = "R-i paketiga randomForest") +
theme_minimal() +
theme(text = element_text(size = 14),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank()) +
coord_flip()
Puude ja tunnuste arv
Nagu öeldud, teeb R vaikimisi mudeli, kus kasvatatakse 500 puud ja proovitakse iga puu igas sõlmes nii mitut juhuslikult valitud tunnust, kui suur on ruutjuur tunnuste arvust. Neid parameetreid saab aga soovi korral muuta vastavalt argumentidega ntree ja mtry.
Vaatame, kas mudeli täpsus paraneb, kui proovime sõlmedes erineval hulgal seletavaid tunnuseid.
# Tee tühi vektor
tapsused <- vector()
# Teeme tsükli, kus
for(i in 2:5){ # iga arvu i kohta 2st 5ni (i = 2, i = 3, i = 4, i = 5)
set.seed(100)
# tee mudel, kus seletavate tunnuste arv võrdub i-ga
mudel <- randomForest(Pron ~ Lopp + Murre + Ref_kaugus_num + Sonepikkus + Aeg + Verbiklass,
data = isik1suur,
mtry = i)
# ja lisa tapsuste vektorisse iga mudeli klassifitseerimistäpsus
# see on sama klassifitseerimistäpsus, mida varem table-käsu abil arvutasime
tapsused[i-1] <- sum(diag(mudel$confusion))/sum(mudel$confusion)
}
tapsused
## [1] 0.6777082 0.6668850 0.6363836 0.6221172
plot(2:5, tapsused,
cex = 1.5,
xlab = "Juhuslike tunnuste arv sõlmes",
ylab = "Mudeli klassifitseerimistäpsus",
main = "Mudeli klassifitseerimistäpsus sõltuvalt sellest,\nkui mitut juhuslikku tunnust igas sõlmes proovitakse")
Näeme, et 2 tunnust igas sõlmes on meie mudeli jaoks tõepoolest optimaalne väärtus, sest rohkematega läheb klassifitseerimistäpsus alla.
Vaatame, kas mudeli täpsus paraneb, kui kasvatame erineval hulgal puid.
# Võtab natuke aega...
tapsused2 <- vector()
puude_arv <- c(10, 100, 500, 1000, 1500, 2000, 3000, 4000)
n <- 1
for(i in puude_arv){
set.seed(100)
mudel <- randomForest(Pron ~ Lopp + Murre + Ref_kaugus_num + Sonepikkus + Aeg + Verbiklass, data = isik1suur, importance = TRUE, ntree = i)
tapsused2[n] <- sum(diag(mudel$confusion))/sum(mudel$confusion)
n <- n+1
}
tapsused2
## [1] 0.6551203 0.6720505 0.6730345 0.6769702 0.6762323 0.6784461 0.6789381
## [8] 0.6794301
plot(puude_arv, tapsused2,
cex = 1.5,
xlab = "Kasvatatud puude arv mudelis",
ylab = "Mudeli klassifitseerimistäpsus",
main = "Mudeli klassifitseerimistäpsus sõltuvalt sellest,\nkui mitu puud kasvatatakse")
Näeme, et puude arvu kasvades mudeli klassifitseerimistäpsus paraneb. Küll aga nõuab iga puu kasvatamine ressurssi, mistõttu mingist punktist alates ei ole täpsuse parandamine enam arvutuslikus mõttes mõistlik. Seega nt 2000 ja 4000 puu vahel enam väga olulist erinevust ei ole. Täpset kriteeriumit puude arvu määramiseks aga paraku ei olegi.
cforest
Tingimuslikud otsustuspuud on tavalistest klassifikatsiooni- ja regressioonipuudest selles mõttes paremad, et need võtavad puude jagunemise aluseks p-väärtused ning on sõlmedesse valitud tunnuste valikul vähem kallutatud (vt ka 14. praktikumi materjale). Tingimuslike otsustuspuude metsa jaoks võib kasutada partykit-paketi funktsiooni cforest(). See on uuem ning natuke ressursiahnem kui randomForest(), aga ka oluliselt täpsem. cforest-funktsiooni soovitatakse randomForest-funktsioonile eelistada eriti siis, kui mudelis on eri tüüpi seletavad tunnused (elimineerib kallutatuse arvuliste tunnuste ja mitme tasemega kategoriaalsete tunnuste valikule). Vaikimisi teeb partykit’i cforest() mudeli algandmestikust võetud väiksemate juhuslike valimitega, kus vaatlused ei või korduda. Kui tahta teha mudeleid bootstrap-meetodil, st võtta sama suured valimid, kus mõned vaatlused võivad korduda, mõned aga jäävad välja, siis peab täpsustama mudeli funktsioonis parameetri perturb = list(replace = TRUE).
cforest()-funktsioon on ka party paketis, ent seal tuleb parameetreid sättida pisut teistmoodi. Vaatame siin partykit-paketi funktsiooni.
# library(partykit)
# Kuna cforest nõuab palju arvutusmahtu, teeme hetkel mudeli 200 puuga.
set.seed(100)
mets_cf <- cforest(Pron ~ Lopp + Murre + Ref_kaugus_num + Sonepikkus + Aeg + Verbiklass,
data = isik1suur,
ntree = 200)
class(mets_cf)
## [1] "cforest" "constparties" "parties"cforest() kasutab samuti vaikimisi ühes sõlmes testitavate tunnuste arvuna ruutjuurt kõikide mudelisse kaasatud seletavate tunnuste arvust, ent ümardab väärtuse ülespoole.
Leiame klassifitseerimistäpsuse ja C. Kuna cforest() ei väljasta ise õigete ja valede ennustuste risttabelit, tuleb klassifitseerimistäpsuseni jõuda jälle ennustatud väärtuste ja tegelike väärtuste võrdlemise kaudu.
# Klassifitseerimistäpsus
enn <- predict(mets_cf)
head(enn)
## 1 2 3 4 5 6
## jah jah jah ei ei ei
## Levels: ei jah
teg <- isik1suur$Pron
head(teg)
## [1] ei ei ei ei ei ei
## Levels: ei jah
t <- table(enn, teg)
t
## teg
## enn ei jah
## ei 1303 574
## jah 590 1599
(t["jah", "jah"]+t["ei", "ei"])/sum(t)
## [1] 0.7137236
# C
# library(Hmisc)
enn_probs <- predict(mets_cf, type = "prob")[,"jah"]
head(enn_probs)
## 1 2 3 4 5 6
## 0.6958636 0.5103594 0.5813970 0.4434836 0.3847333 0.4449935
teg_probs <- as.numeric(isik1suur$Pron)-1
head(teg_probs)
## [1] 0 0 0 0 0 0
somers2(enn_probs, teg_probs)["C"]
## C
## 0.7895699Nagu näha, saame cforest()-funktsiooniga oluliselt täpsema mudeli ka väiksema arvu puudega. Kuna juhumetsa mudelitesse on OOB-vaatluste näol testandmestik juba sisse ehitatud, ei ole otseselt vajadust metsamudeleid muude andmete peal valideerida, ent mida kindlam tahta olla tulemuses, seda enamate erinevate valimite peal võib mudelit testida. Erinevaid valimeid saab juhumetsades ka mudeldamisel erineva seemne (seed) seadmisega.
Tunnuste olulisust saab cforest-objektist kätte funktsiooniga varimp(). cforest väljastab ainult tunnuste permutatsiooniolulisuse.
# Tunnuste olulisus
imps <- varimp(mets_cf)
imps
## Lopp Murre Ref_kaugus_num Sonepikkus Aeg
## 0.10894035 0.08344926 0.06477770 0.06339361 0.02507018
## Verbiklass
## 0.15086338
# Teeme olulisusest andmetabeli
imps_df <- data.frame(olulisus = imps, tunnus = names(imps), row.names = NULL)
head(imps_df)
## olulisus tunnus
## 1 0.10894035 Lopp
## 2 0.08344926 Murre
## 3 0.06477770 Ref_kaugus_num
## 4 0.06339361 Sonepikkus
## 5 0.02507018 Aeg
## 6 0.15086338 Verbiklass
# Teeme joonise
ggplot(data = imps_df,
aes(x = tunnus, y = olulisus)) +
geom_point(aes(fill = olulisus), size = 4, shape = 22, show.legend = FALSE) +
scale_x_discrete(limits = imps_df[order(imps_df$olulisus),"tunnus"]) +
scale_fill_gradient(low = "steelblue4", high = "tomato2") +
labs(x = "",
title = "Tunnuste permutatsiooniolulisus juhumetsa mudelis",
caption = "R-i paketiga partykit") +
theme_minimal() +
theme(text = element_text(size = 14),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank()) +
coord_flip()
Tavaline permutatsiooniolulisus võib ülehinnata omavahel seotud/korreleeruvate seletavate tunnuste olulisust. Selle vältimiseks on partykit-paketis võimalik hinnata tunnuste tingimuslikku olulisust (conditional importance, conditional = TRUE). Kuna see on arvutusmahukas protsess, paneme siia ainult koodi.
# Tunnuste tingimuslik olulisus (NB! võib võtta kaua aega)
imps2 <- varimp(mets_cf, conditional = TRUE)
imps2
# Teeme olulisusest andmetabeli
imps2_df <- data.frame(olulisus = imps2, tunnus = names(imps2), row.names = NULL)
head(imps2_df)
# Teeme joonise
ggplot(data = imps2_df,
aes(x = tunnus, y = olulisus)) +
geom_point(aes(fill = olulisus), size = 4, shape = 22, show.legend = FALSE) +
scale_x_discrete(limits = imps2_df[order(imps2_df$olulisus),"tunnus"]) +
scale_fill_gradient(low = "steelblue4", high = "tomato2") +
labs(x = "",
title = "Tunnuste tingimuslik permutatsiooniolulisus\njuhumetsa mudelis",
caption = "R-i paketiga partykit") +
theme_minimal() +
theme(text = element_text(size = 14),
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank()) +
coord_flip()Võiksime teha ka juhumetsa, kus trimmime üksikuid puid samade parameetrite järgi, nagu tegime ctree()-ga (nt minbucket, alpha jne). Samuti saab teha juhumetsi arvuliste uuritavate tunnustega ning hinnata metsa headust ligikaudselt R2 järgi või korrelatsioonikoefitsiendiga.
Juhumetsade visualiseerimine
Üldjuhul kasutatakse juhumetsi kõige olulisemate tunnuste väljaselgitamiseks ning parima mudeli tegemiseks, mida saaks praktikas uute vaatluste klasside/väärtuste ennustamiseks kasutada. Juhumets on oma olemuselt nn musta kasti mudel ega võimalda vaadata metsa sisse samamoodi nagu üksikute puude puhul. Seega ei tea me, mil moel täpselt mingid tunnused uuritava tunnuse väärtust mõjutavad.
On siiski mõned visualiseerimistehnikad, mis võimaldavad seletavate tunnuste üldmõjusid ja interaktsioone visualiseerida sarnaselt regressioonimudelitele. Üheks selliseks tehnikaks on nn osasõltuvusgraafikud (partial dependence plots), mis visualiseerivad korraga ühe seletava tunnuse (või tunnustevahelise interaktsiooni) mõju uuritavale tunnusele.
Vaatame funktsiooni plotmo() võimalusi samanimelises paketis.
Selle kõige lihtsamas versioonis hoitakse ühe seletava tunnuse mõju uurimisel uuritavale tunnusele teiste arvuliste seletavate tunnuste väärtused nende mediaani peal ning kategoriaalsete tunnuste väärtused nende kõige sagedamal/tüüpilisemal tasemel. Määrates funktsioonis argumendi trace = 1, näitab funktsioon ka seda, millised need väärtused täpsemalt on. Tasemeid saab muuta argumentidega grid.func ja grid.levels (vt lähemalt paketi dokumentatsioonist). plotmo paketi tegijad ise nimetavad seda ka “vaese mehe osasõltuvusgraafikuks”. See on kiirem ning annab enam-vähem ülevaate tunnustevahelistest sõltuvussuhetest.
## variable importance: Verbiklass Lopp Murre Ref_kaugus_num Sonepikkus Aeg
## stats::predict(cforest.object, data.frame[3,6], type="response")
## stats::fitted(object=cforest.object)
## got model response from model.frame(Pron~Lopp+Murre+Ref_kaugus_num+Sonepi...,
## data=object$data, na.action="na.fail")
##
## plotmo grid: Lopp Murre Ref_kaugus_num Sonepikkus Aeg Verbiklass
## jah SAARTE 4 5 ipf muu
Vaikimisi teeb plotmo graafiku, mis ennustab uuritava tunnuse klasse (type = "response"). Seega tähendab “1” meie andmestiku puhul seda, et asesõna pigem ei esine, ning “2” seda, et asesõna esineb (juhul, kui hoida kõik teised tunnused kindlal tasemel!). Näiteks kontekstis, kus Murre = "SAARTE", Ref_kaugus_num = 4, Sonepikkus = 5, Aeg = "ipf" ja Verbiklass = "muu", asesõna pigem esineks, kui Lopp = "ei", ja pigem ei esineks, kui Lopp = "jah" (joonis “1 Lopp”). Kontekstis, kus Lopp = "jah", Ref_kaugus_num = 4, Sonepikkus = 5, Aeg = "ipf" ja Verbiklass = "muu", pigem ei kasutataks asesõna üheski murdes (joonis “2 Murre”) jne. Selles mõttes sarnaneb nende graafikute tõlgendamine paljuski regressioonimudelite tõlgendamisega.
Lisaks üksikute tunnuste mõjude kuvamisele näitab plotmo 3D-graafikul ka olulisemate interaktsioonide mõju uuritavale tunnusele (kui tahta kuvada kõiki võimalikke interaktsioone, siis saab täpsustada funktsioonis all2 = TRUE). Nii näiteks näeb, et ehkki üldiselt murretes asesõna pigem ei esine (teiste tunnuste fikseeritud kontekstis), siis ida- ja saarte murdes ilma pöördelõputa tegusõnadega pigem ikkagi esineb (joonis “1 Lopp: Murre”). Nooled näitavad, mispidi tunnuse väärtused graafikul muutuvad: arvuliste tunnuste puhul suunab nool väiksemast väärtusest suuremani ning kategoriaalsete tunnuste puhul tähestiku järjekorras esimesest tasemest tagumiseni.
Ilmselt oleks aga informatiivsem vaadata graafikuid mitte ennustatud klasside, vaid tõenäosuste põhjal, kuna see võimaldab paindlikumat analüüsi.
## variable importance: Verbiklass Lopp Murre Ref_kaugus_num Sonepikkus Aeg
## stats::predict(cforest.object, data.frame[3,6], type="prob")
## stats::fitted(object=cforest.object)
## set nresponse=2
## nresponse=2 but for plotmo_y using nresponse=1 because ncol(y) == 1
## got model response from model.frame(Pron~Lopp+Murre+Ref_kaugus_num+Sonepi...,
## data=object$data, na.action="na.fail")
##
## plotmo grid: Lopp Murre Ref_kaugus_num Sonepikkus Aeg Verbiklass
## jah SAARTE 4 5 ipf muu
Kui tahaksime 3D-graafikute asemel kuvada tunnustevahelisi suhteid näiteks toonide kaudu, võime kasutada funktsioonis lisaks argumenti type2 = "image", kus tumedamad toonid näitavad väiksemat tõenäosust ning heledamad suuremat.
## variable importance: Verbiklass Lopp Murre Sonepikkus Ref_kaugus_num Aeg
## stats::predict(cforest.object, data.frame[3,6], type="prob")
## stats::fitted(object=cforest.object)
## set nresponse=2
## nresponse=2 but for plotmo_y using nresponse=1 because ncol(y) == 1
## got model response from model.frame(Pron~Lopp+Murre+Ref_kaugus_num+Sonepi...,
## data=object$data, na.action="na.fail")
##
## plotmo grid: Lopp Murre Ref_kaugus_num Sonepikkus Aeg Verbiklass
## jah SAARTE 4 5 ipf muu
Võime valida ka ainult kindlad graafikud, mida näha tahame. Peamõjude valimiseks saab kasutada argumenti degree1 ning interaktsioonide jaoks argumenti degree2.
plotmo(object = mets_cf,
trace = 1,
type = "prob",
type2 = "image",
degree1 = c("Lopp", "Verbiklass"),
degree2 = c("Lopp", "Verbiklass"))## variable importance: Verbiklass Lopp Murre Ref_kaugus_num Sonepikkus Aeg
## stats::predict(cforest.object, data.frame[3,6], type="prob")
## stats::fitted(object=cforest.object)
## set nresponse=2
## nresponse=2 but for plotmo_y using nresponse=1 because ncol(y) == 1
## got model response from model.frame(Pron~Lopp+Murre+Ref_kaugus_num+Sonepi...,
## data=object$data, na.action="na.fail")
##
## plotmo grid: Lopp Murre Ref_kaugus_num Sonepikkus Aeg Verbiklass
## jah SAARTE 4 5 ipf muu
plotmo-paketiga saab teha ka n-ö päris osasõltuvusgraafikuid, kus iga konkreetse seletava tunnuse juures kõikide teiste seletavate tunnuste tasemete mõju keskmistatakse selle asemel, et määrata lihtsalt läbivalt mingi fikseeritud taustakontekst. Need graafikud annavad seega pisut adekvaatsema pildi üksikute seletavate tunnuste marginaalsest mõjust, kuna ei arvesta ainult mingit üht spetsiifilist konteksti. Osasõltuvusgraafikute jaoks määrame arumendi pmethod väärtuseks partdep. Kuna tunnuseid on mitu ning meetod komplekssem ja arvutusmahukam, läheb sellise graafiku tegemiseks ka rohkem aega. Kuvame siin seega ressursi kokkuhoiu mõttes ainult peamõjud (degree2 = FALSE).
## variable importance: Verbiklass Lopp Murre Ref_kaugus_num Sonepikkus Aeg
## stats::predict(cforest.object, data.frame[3,6], type="prob")
## stats::fitted(object=cforest.object)
## set nresponse=2
## nresponse=2 but for plotmo_y using nresponse=1 because ncol(y) == 1
## got model response from model.frame(Pron~Lopp+Murre+Ref_kaugus_num+Sonepi...,
## data=object$data, na.action="na.fail")
## calculating partdep for Lopp## calculating partdep for Murre## calculating partdep for Ref_kaugus_num## calculating partdep for Sonepikkus## calculating partdep for Aeg## calculating partdep for Verbiklass
Osasõltuvusgraafikute tegemiseks on ka teisi pakette, nt pdp, ICEbox ja edarf. Ka randomForest-paketil on tegelikult sisseehitatud partialPlot() funktsioon, ent sellega saab korraga kuvada ainult üht tunnust ning y-teljel ei ole kuvatud mitte tõnäosused, vaid tunnuse väärtuste suhteline mõju uuritavale tunnusele (negatiivsel poolel “jah” esinemisele, positiivsel poolel “ei” esinemisele).
par(mfrow = c(3,2))
randomForest::partialPlot(mets_rf, x.var = "Lopp", pred.data = isik1suur)
randomForest::partialPlot(mets_rf, x.var = "Aeg", pred.data = isik1suur)
randomForest::partialPlot(mets_rf, x.var = "Sonepikkus", pred.data = isik1suur)
randomForest::partialPlot(mets_rf, x.var = "Ref_kaugus_num", pred.data = isik1suur)
randomForest::partialPlot(mets_rf, x.var = "Verbiklass", pred.data = isik1suur)
randomForest::partialPlot(mets_rf, x.var = "Murre", pred.data = isik1suur)
Kordamisküsimused
1. Milline väide on õige?
- R-ruut on täpne arvulise uuritava tunnusega puu- ja metsamudelite headuse näitaja.
- Seletavate tunnuste permutatsiooniolulisus on täpsem näitaja kui Gini-indeksil põhinev olulisus.
- Z-skoorid on tundlikud valimi suuruse ja puude arvu suhtes.
- Metsamudelite tunnuste olulisust saab visualiseerida osasõltuvusgraafikutel.
2. Milles seisneb juhumetsa juhuslikkus?
- Mudeli ennustused üldistatakse mitme puumudeli põhjalt, mis omakorda on treenitud algandmestikust juhuslikult võetud valimitel.
- Iga puu igas sõlmes tehakse vaatluste jagamiseks valik juhuslikult valitud seletavate tunnuste hulgast.
- Mudelis kasvatatavates puudes ennustatakse lehtedesse juhuslikke uuritava tunnuse väärtuseid.
- Seletavad tunnused, mida metsamudelisse kaasatakse, on valitud kõikidest andmestikus olevatest tunnustest juhuslikult.
3. Mis on out-of-bag-vaatlused?
- Metsamudeli poolt tegelikele vaatlustele ennustatud väärtused.
- Algandmestiku vaatlused, millel mudeleid treenitakse.
- Algandmestiku vaatlused, mis jäävad metsamudelis iga üksiku puu kasvatamiseks võetud juhuvalimist välja.
Järgmisel korral
- Korrespondentsanalüüs
NB! Järgmine kord 21. aprillil!