OpenStreetMap and Urban Data
What is OpenStreetMap?
OpenStreetMap (OSM) is a global collaborative (crowd-sourced) dataset and project that aims at creating a free editable map of the world containing a lot of information about our environment. It contains data for example about streets, buildings, different services, and landuse to mention a few.
OSM has a large userbase with more than 4 million users that contribute actively on OSM by updating the OSM database with 3 million changesets per day. In total OSM contains more than 4 billion nodes that form the basis of the digitally mapped world that OSM provides (stats from November 2017.
OpenStreetMap is used not only for integrating the OSM maps as background maps to visualizations or online maps, but also for many other purposes such as routing, geocoding, education, and research. OSM is also widely used for humanitarian response e.g. in crisis areas (e.g. after natural disasters) and for fostering economic development (see more from Humanitarian OpenStreetMap Team (HOTOSM) website.
Download and visualize OpenStreetMap data with osmnx
This lesson we will explore a new and exciting Python module called osmnx that can be used to retrieve, construct, analyze, and visualize street networks from OpenStreetMap. In short it offers really handy functions to download data from OpenStreet map, analyze the properties of the OSM street networks, and conduct network routing based on walking, cycling or driving.
There is also a scientific article available describing the package:
Boeing, G. 2017. “OSMnx: New Methods for Acquiring, Constructing, Analyzing, and Visualizing Complex Street Networks.” Computers, Environment and Urban Systems 65, 126-139. doi:10.1016/j.compenvurbsys.2017.05.004
As said, one the most useful features that osmnx provides is an easy-to-use way of retrieving OpenStreetMap data (using OverPass API ).
Let’s see how we can download and visualize street network data from a district of Tartu in City Centre, Estonia. Osmnx makes it really easy to do that as it allows you to specify an address to retrieve the OpenStreetMap data around that area. In fact, osmnx uses the same Nominatim Geocoding API to achieve this which we tested during the Lesson 2.
Let’s retrieve OpenStreetMap (OSM) data by specifying "Tartu, Estonia" as the address where the data should be downloaded.
In [1]: import osmnx as ox
In [2]: import matplotlib.pyplot as plt
In [3]: place_name = "Tartu, Estonia"
In [4]: graph = ox.graph_from_place(place_name)
In [5]: type(graph)
Out[5]: networkx.classes.multidigraph.MultiDiGraph
Okey, as we can see the data that we retrieved is a special data object called networkx.classes.multidigraph.MultiDiGraph. A DiGraph is a data type that stores nodes and edges with optional data, or attributes.
What we can see here is that this data type belongs to a Python module called networkx
that can be used to create, manipulate, and study the structure, dynamics, and functions of complex networks.
Networkx module contains algorithms that can be used for example to calculate shortest paths
along networks using e.g. Dijkstra’s or A* algorithm.
Let’s see how our street network looks like. It is easy to visualize the graph with osmnx with plot_graph() function. The function utilizes Matplotlib for visualizing the data, hence as a result it returns a matplotlib figure and axis objects.
In [6]: fig, ax = ox.plot_graph(graph)
In [7]: plt.tight_layout()
Great! Now we can see that our graph contains the nodes (circles) and the edges (lines) that connects those nodes to each other.
Let’s explore the street network a bit. The library allows us to convert the nodes and edges dataset into two separate geodataframes.
In [8]: nodes, edges = ox.graph_to_gdfs(graph)
In [9]: print(edges.head(3))
osmid oneway lanes ref \
u v key
8220933 6854135436 0 117178126 True 5 3
8220941 0 [731962213, 730852870, 29394711] False 4 3
8220941 332221897 0 28906993 True 2 3
name highway maxspeed length \
u v key
8220933 6854135436 0 Riia trunk 50 65.343
8220941 0 [Narva mnt, Riia] trunk 50 137.133
8220941 332221897 0 Narva mnt trunk 40 55.405
geometry \
u v key
8220933 6854135436 0 LINESTRING (26.73016 58.37857, 26.72998 58.378...
8220941 0 LINESTRING (26.73016 58.37857, 26.73027 58.378...
8220941 332221897 0 LINESTRING (26.73056 58.37979, 26.73061 58.379...
bridge junction service tunnel access width
u v key
8220933 6854135436 0 NaN NaN NaN NaN NaN NaN
8220941 0 yes NaN NaN NaN NaN NaN
8220941 332221897 0 NaN NaN NaN NaN NaN NaN
print(edges.crs)
print(edges.head(3))
As you will see, there are several interesting columns, for example:
‘oneway’, ‘lanes’, ‘name’, or ‘maxspeed’
But like with all data we get from somewhere else, we need to check datatypes and potentially clean up the data. Let’s look at the speed limit maxspeed information that is entered in the OSM dataset for many streets. Here is again a very manual and defensive way of making sure to convert the information in the maxspeed column into a predictable numerical format.
In [10]: def clean_speed(x):
....: try:
....: if isinstance(x, str):
....: return float(x)
....: elif isinstance(x, float):
....: return x
....: elif isinstance(x, int):
....: return x
....: elif isinstance(x, list):
....: return clean_speed(x[0])
....: elif x is None:
....: return 20
....: elif np.isnan(x):
....: return 20
....: else:
....: return x
....: except:
....: print(type(x))
....: return 20
....: edges['speed'] = edges['maxspeed'].apply(clean_speed)
....:
Now let’s have a more colourful look at the streets of Tartu, based on the estimated max-speed attribute. Let’s also reproject to Estonian National Grid (EPSG:3301):
In [11]: streets_3301 = edges.to_crs(3301)
In [12]: streets_3301.plot(column='speed', cmap='viridis', legend=True)
Out[12]: <AxesSubplot:>
In [13]: plt.tight_layout()
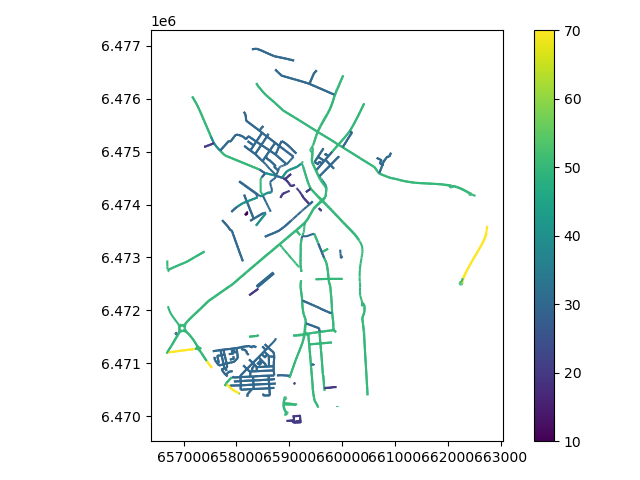
It is also possible to retrieve other types of OSM data features with osmnx.
Let’s download the buildings with geometries_from_place() function and plot them on top of our street network in Tartu.
# specify that we're retrieving building footprint geometries
In [14]: tags = {'building': True}
In [15]: gdf = ox.geometries_from_place('Kesklinn, Tartu, Estonia', tags)
In [16]: gdf.head(3)
Out[16]:
source \
element_type osmid
node 2345996395 NaN
way 30221557 Tartu City Government
30221588 Tartu City Government
geometry \
element_type osmid
node 2345996395 POINT (26.71552 58.37320)
way 30221557 POLYGON ((26.71092 58.38214, 26.71117 58.38227...
30221588 POLYGON ((26.71623 58.38370, 26.71638 58.38364...
man_made amenity operator wheelchair building \
element_type osmid
node 2345996395 NaN NaN NaN NaN yes
way 30221557 NaN NaN NaN NaN school
30221588 NaN NaN NaN NaN yes
name height level ... grades \
element_type osmid ...
node 2345996395 TÜ Geograafia osakond NaN NaN ... NaN
way 30221557 Joosepi maja NaN NaN ... NaN
30221588 NaN NaN NaN ... NaN
community_centre automated payment:coins self_service \
element_type osmid
node 2345996395 NaN NaN NaN NaN
way 30221557 NaN NaN NaN NaN
30221588 NaN NaN NaN NaN
fixme building:flats ways abandoned:amenity type
element_type osmid
node 2345996395 NaN NaN NaN NaN NaN
way 30221557 NaN NaN NaN NaN NaN
30221588 NaN NaN NaN NaN NaN
[3 rows x 103 columns]
As a result we got the data as GeoDataFrames. Hence, we can plot them using the familiar plot() function of Geopandas. However, the data comes in WGS84. For a cartographically good representation lower scales that keeps shapes from being distorted, a Marcator based projection is ok. OSMnx provides a project function, that selects the local UTM Zone as CRS and reprojects for us.
# projects in local UTM zone
In [17]: gdf_proj = ox.project_gdf(gdf)
In [18]: gdf_proj.crs
Out[18]:
<Projected CRS: +proj=utm +zone=35 +ellps=WGS84 +datum=WGS84 +unit ...>
Name: unknown
Axis Info [cartesian]:
- E[east]: Easting (metre)
- N[north]: Northing (metre)
Area of Use:
- undefined
Coordinate Operation:
- name: UTM zone 35N
- method: Transverse Mercator
Datum: World Geodetic System 1984
- Ellipsoid: WGS 84
- Prime Meridian: Greenwich
OSMnx provides an adhoc plotting function for geometry footprints, esp. useful for our building footprints:
In [19]: fig, ax = ox.plot_footprints(gdf_proj, dpi=400, show=True)
In [20]: plt.tight_layout()
Nice! Now, as we can see, we have our OSM data as GeoDataFrames and we can plot them using the same functions and tools as we have used before.
Note
There are also other ways of retrieving the data from OpenStreetMap with osmnx such as passing a Polygon to extract the data from that area, or passing a Point coordinates and retrieving data around that location with specific radius. Take a look at te developer tutorials to find out how to use those features of osmnx.
Let’s create a map out of the streets and buildings but again exclude the nodes (to keep the figure clearer).
In [21]: buildings_3301 = gdf_proj.to_crs(3301)
In [22]: plt.style.use('dark_background')
In [23]: fig, ax = plt.subplots(figsize=(21,17))
In [24]: streets_3301.plot(ax=ax, linewidth=2, alpha=0.9, column='speed', cmap='Greens_r')
Out[24]: <AxesSubplot:>
In [25]: buildings_3301.plot(ax=ax, lw=4, edgecolor='lightgreen', facecolor='white', alpha=0.8)
Out[25]: <AxesSubplot:>
In [26]: plt.tight_layout()
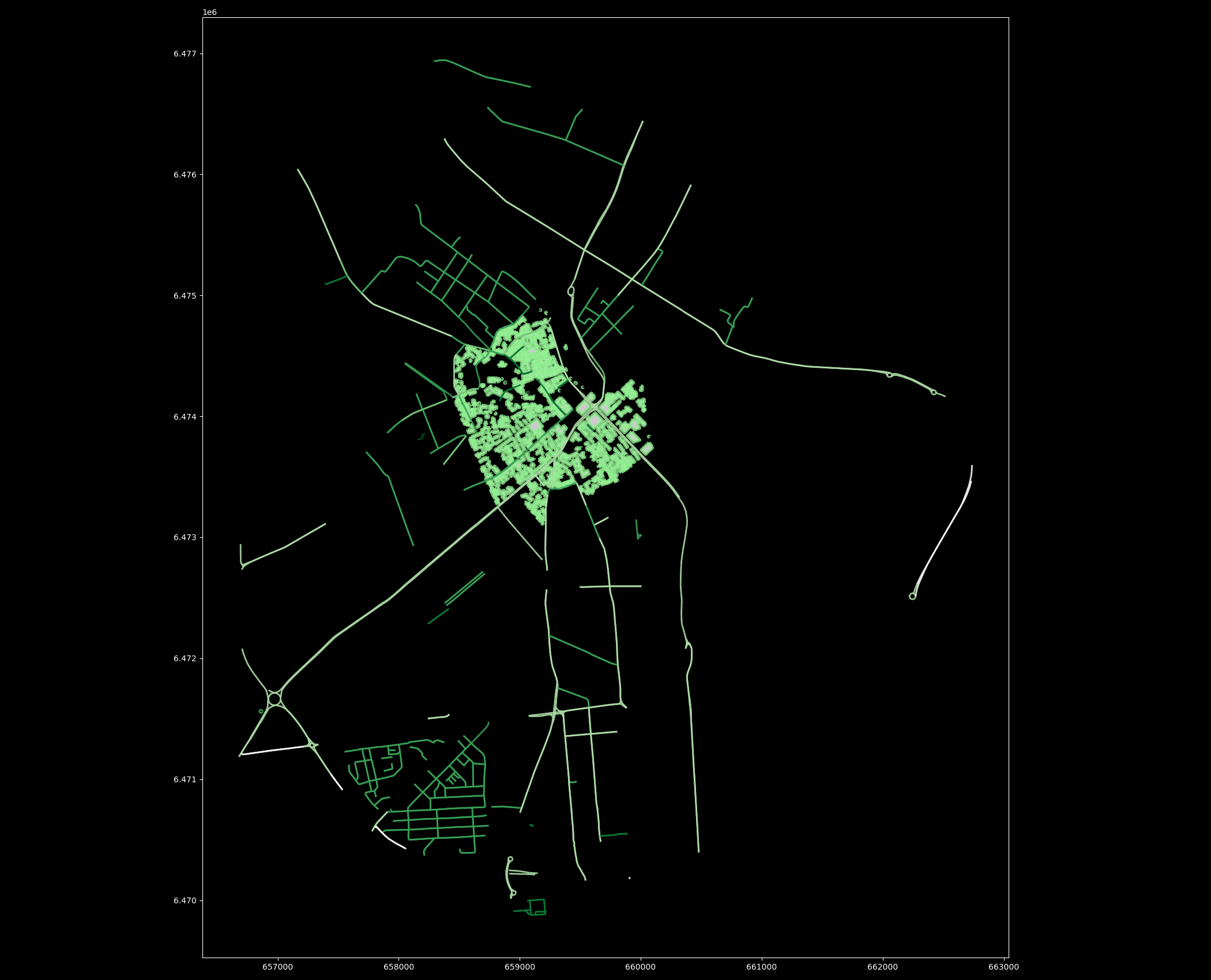
Cool! Now we have a map where we have plotted the buildings, streets and the boundaries of the selected region of ‘Tartu’ in City Centre. And all of this required only a few lines of code.
Note
Try following task yourself - Explore the column highway in our edges GeoDataFrame, it contains information about the type of the street (such as primacy, cycleway or footway).
Select the streets that are walkable or that can be used with cycle and visualize only them with the buildings and the area polygon. Use different colors and line widths for the cycleways and footways.
Hint
There are a few nice and convenient high-level functions in osmnx that can be used to produce nice maps directly just by using a single function that might be useful. If you are interested take a look of this tutorial. In the lesson we won’t cover these, because we wanted to keep as much control to ourselves as possible, hence using lower-level functions.
More dynamic urban data
From OSM we loaded comparatively static geographic data. Now we want to throw in some spatio-temporal data into the mix.
In this lesson’s data package is an export of a dataset from the Tartu City Government’s open data portal. If you haven’t downloaded the data yet, you can download (and then extract) the dataset zip-package from this link.
Originally, the dataset can only be accessed via a webservice API. This is an excerpt for the weeks 2021-03-02 to 2021-04-06 and contains traffic counter data, in 15 minute intervals for several streets and intersections in central Tartu - it counts the amounts of cars passing through. At the end of the lesson is an example how to access the API live with Python. But the time being let’s use the exported data now.
In [27]: import geopandas as gpd
In [28]: traffic_data = gpd.read_file('source/_static/data/L4/tartu_export_5km_buffer_week.gpkg', driver="GPKG", layer="liiklus")
In [29]: traffic_data.head(3)
Out[29]:
name count lane objectid time text_time \
0 LKL_Tiksoja 1 2 296992 1616452200041 2021-03-22 22:30:00
1 LKL_Roopa 17 1 296993 1616435100041 2021-03-22 17:45:00
2 LKL_Tiksoja 3 2 296994 1616455800041 2021-03-22 23:30:00
geometry
0 POINT (26.65439 58.40841)
1 POINT (26.69739 58.34843)
2 POINT (26.65439 58.40841)
traffic_data.info()
traffic_data.describe()
The time field is currently a text field. Pandas supports proper datetime indexing and querying, so we want to convert the current string object into a datetime datatype. The easiest is to delegate the hard work of guessing snd trying the right format to ‘pandas’:
In [30]: import pandas as pd
In [31]: traffic_data['datetime'] = traffic_data['text_time'].apply(pd.to_datetime, infer_datetime_format=True )
For the ‘time’ column you could guess that it might look like an epoch time stamp. In general, at some point it makes sense to get more familiar with Python’s datetime functions and Pandas datetime indexing and parsing support. Then you could try to parse it as a datetime timestamp, like so:
traffic_data['datetime'] = pd.to_datetime(traffic_data['time'], unit='ms')
For a moment, you might have considered to use the chronological timestamps as an index, like for a time-series for a weather station? But in this example we can’t do that because technically each location is its own separate time-series, and right now we don’t even know how many distinct locations (in terms of identical Point geometries) we have.
As we have little knowledge about the dataset, we should try to get a feeling of value ranges, categories, times etc. For example, let’s check how many different names there are. Maybe it gives us a clue as to what the spatial spread might be:
In [32]: stations = len(traffic_data['name'].unique())
In [33]: print(stations)
16
In [34]: print(traffic_data['name'].value_counts())
LKL_Voru 1885
LKL_Narva_mnt 1881
LKL_Ilmatsalu 1881
LKL_Riia_mnt_LV 1880
LKL_Roomu 1880
LKL_Arukula 1879
LKL_Viljandi_mnt 1876
LKL_Riia_mnt_LS 1876
LKL_Rapina_mnt 1874
LKL_Tiksoja 1873
LKL_Ringtee_3 1872
LKL_Lammi 1871
LKL_Ihaste 1871
LKL_Ringtee_2 1871
LKL_Ringtee_1 1868
LKL_Roopa 1862
Name: name, dtype: int64
Officially a handful of distinct names. something we could now explore further as one way of aggregation. Let’s look at the value distribution per “name” class. While the classic “Matplotlib” has the whole toolbox to plot whatever you desire or imagine, sometimes it is nice to use some higher level packages so we don’t have to do all the coding by hand. Let me introduce to you the Seaborn package. Seaborn builds on top of the Python statistical and scientific ecosystem, and of course on top of Matplotlib, and provides a large number of high-quality and practical statistical plots and works nicely with dataframes. In the following image we are using a BoxPlot.
In [35]: import seaborn as sns
In [36]: import matplotlib.pyplot as plt
In [37]: fig, ax = plt.subplots(figsize=(17,13))
In [38]: sns.boxplot(x='name', y='count', data=traffic_data)
Out[38]: <AxesSubplot:xlabel='name', ylabel='count'>
In [39]: plt.title(f"Boxplot of Traffic Count values for different location names", fontsize='x-large')
Out[39]: Text(0.5, 1.0, 'Boxplot of Traffic Count values for different location names')
In [40]: plt.xticks(rotation=45, fontsize='large')
Out[40]:
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]),
[Text(0, 0, 'LKL_Tiksoja'),
Text(1, 0, 'LKL_Roopa'),
Text(2, 0, 'LKL_Lammi'),
Text(3, 0, 'LKL_Viljandi_mnt'),
Text(4, 0, 'LKL_Ringtee_3'),
Text(5, 0, 'LKL_Riia_mnt_LS'),
Text(6, 0, 'LKL_Ringtee_1'),
Text(7, 0, 'LKL_Riia_mnt_LV'),
Text(8, 0, 'LKL_Narva_mnt'),
Text(9, 0, 'LKL_Roomu'),
Text(10, 0, 'LKL_Ilmatsalu'),
Text(11, 0, 'LKL_Ihaste'),
Text(12, 0, 'LKL_Ringtee_2'),
Text(13, 0, 'LKL_Arukula'),
Text(14, 0, 'LKL_Voru'),
Text(15, 0, 'LKL_Rapina_mnt')])
In [41]: plt.xlabel("location name", fontsize='x-large')
Out[41]: Text(0.5, 0, 'location name')
In [42]: plt.yticks(fontsize='large')
Out[42]:
(array([-100., 0., 100., 200., 300., 400., 500.]),
[Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, ''),
Text(0, 0, '')])
In [43]: plt.ylabel("count", fontsize='x-large')
Out[43]: Text(0, 0.5, 'count')
In [44]: plt.tight_layout()
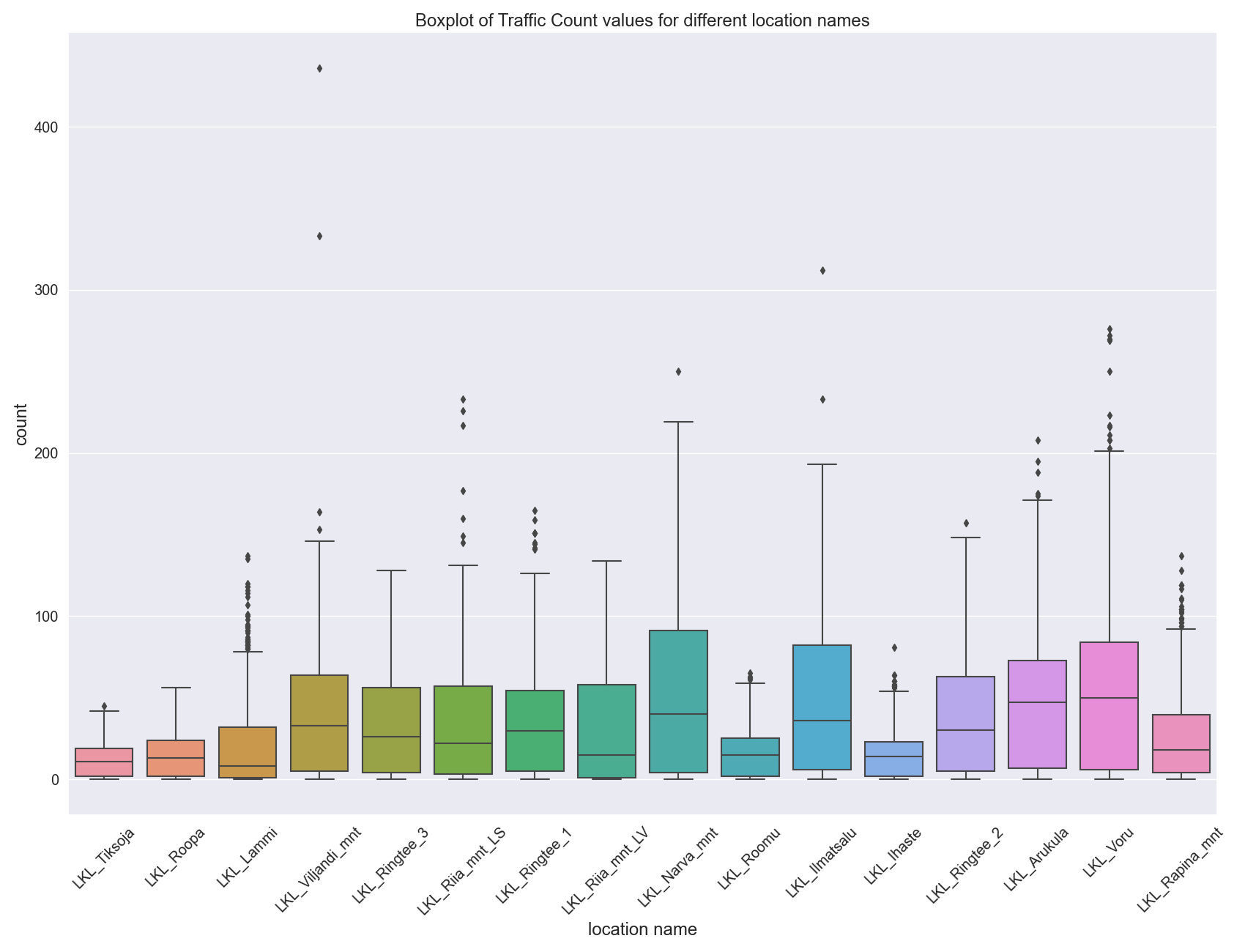
It looks like the traffic counters at Narva street have a wider variation then most. Let’s explore only the counts for one “name” class for now. Later we can go back and apply the functions the whole dataset.
In [45]: narva_lk = traffic_data.loc[traffic_data['name'] == "LKL_Narva_mnt"].copy()
In [46]: fig, ax = plt.subplots(figsize=(17,13))
In [47]: sns.histplot(data=narva_lk, x="count")
Out[47]: <AxesSubplot:xlabel='count', ylabel='Count'>
In [48]: plt.title(f"Histogram of Traffic Count values for Narva Maantee location", fontsize='x-large')
Out[48]: Text(0.5, 1.0, 'Histogram of Traffic Count values for Narva Maantee location')
In [49]: plt.tight_layout()
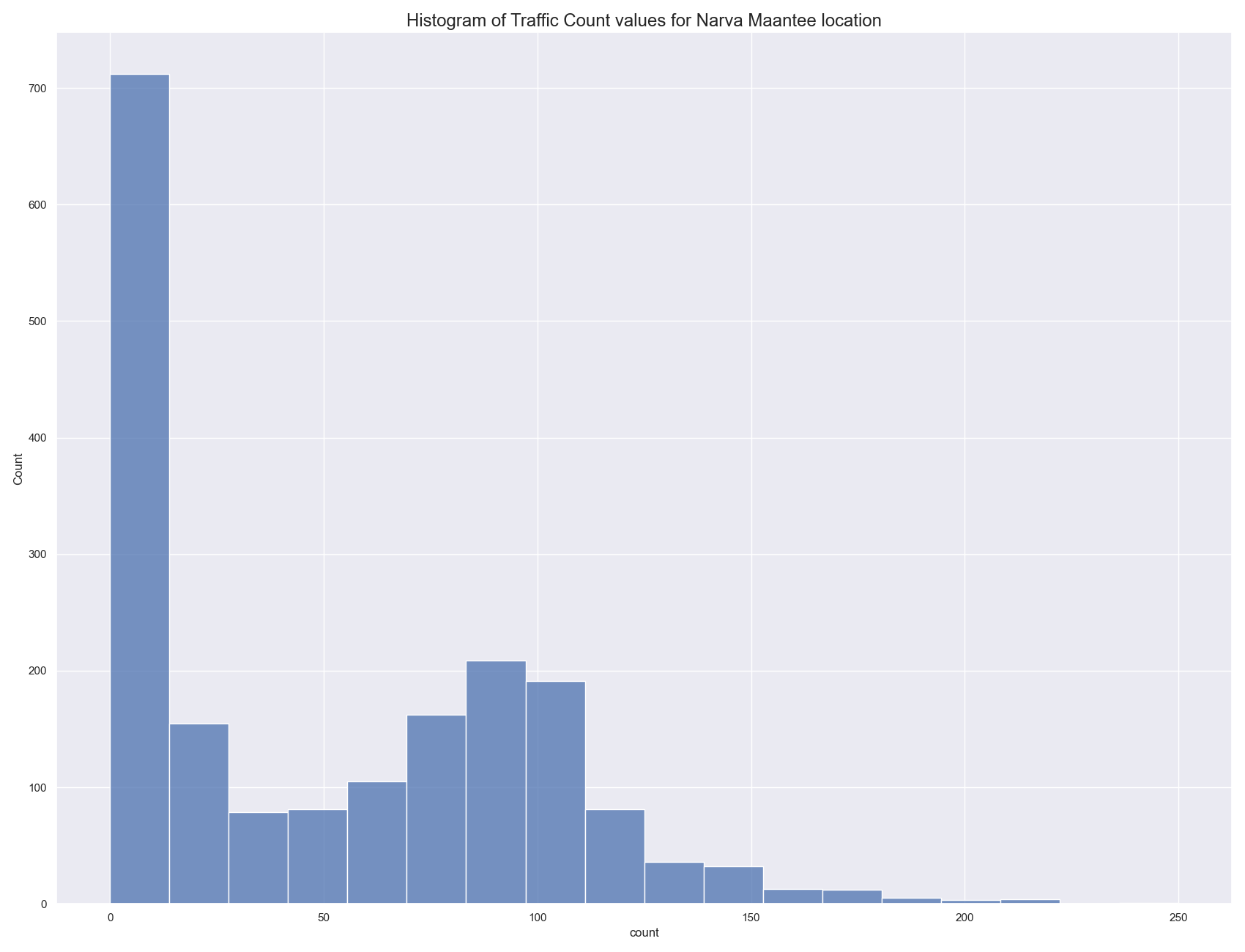
The histogram above shows the general distribution of measurement values, obviously, in most cases there are none or only very few cars measured per time interval. Let’s make an aggregation for the hour of the day. Overall all days, take “sum()” for all counts that are during the same time of the day.
In [50]: narva_lk['hour_of_day'] = narva_lk['datetime'].apply(lambda dtx: dtx.hour)
In [51]: agg_narva_hours = []
In [52]: for hod, sub_df in narva_lk.groupby(by='hour_of_day'):
....: all_counts = sub_df['count'].sum()
....: agg_narva_hours.append( { 'hod': hod, 'count': all_counts} )
....:
In [53]: nava_hod_sum_df = pd.DataFrame(agg_narva_hours).set_index('hod')
In [54]: nava_hod_sum_df.plot(kind='bar')
Out[54]: <AxesSubplot:xlabel='hod'>
In [55]: plt.title(f"Bar plot of the sum of Traffic Count values for the Narva Maantee location, per hour of the day", fontsize=12)
Out[55]: Text(0.5, 1.0, 'Bar plot of the sum of Traffic Count values for the Narva Maantee location, per hour of the day')
In [56]: plt.tight_layout()
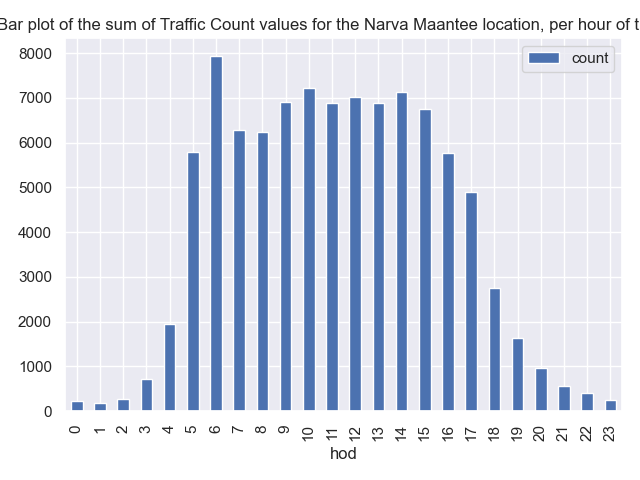
This is a bit easier, when you start getting more used to grouping and aggregating. You can write this now for the “average” (mean) in one line:
In [57]: narva_lk.groupby(by='hour_of_day')['count'].mean().plot(kind='bar')
Out[57]: <AxesSubplot:xlabel='hour_of_day'>
In [58]: plt.title(f"Bar plot of the mean of Traffic Count values for the Narva Maantee location, per hour of the day", fontsize=12)
Out[58]: Text(0.5, 1.0, 'Bar plot of the mean of Traffic Count values for the Narva Maantee location, per hour of the day')
In [59]: plt.tight_layout()
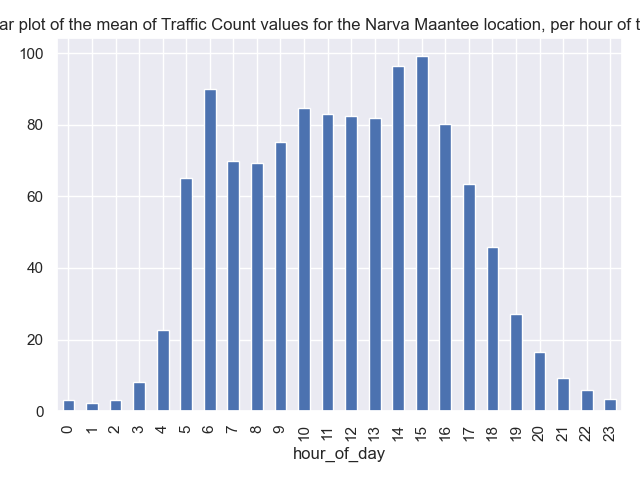
In the same way we should now also look at the weekday pattern.
In [60]: narva_lk['day_of_week'] = narva_lk['datetime'].apply(lambda dtx: dtx.day_of_week)
In [61]: fig, (ax_a, ax_b) = plt.subplots(1, 2, figsize=(18,15))
In [62]: narva_lk.groupby(by='day_of_week')['count'].sum().plot(kind='bar', ax=ax_a)
Out[62]: <AxesSubplot:xlabel='day_of_week'>
In [63]: narva_lk.groupby(by='day_of_week')['count'].mean().plot(kind='bar', ax=ax_b)
Out[63]: <AxesSubplot:xlabel='day_of_week'>
In [64]: plt.tight_layout()
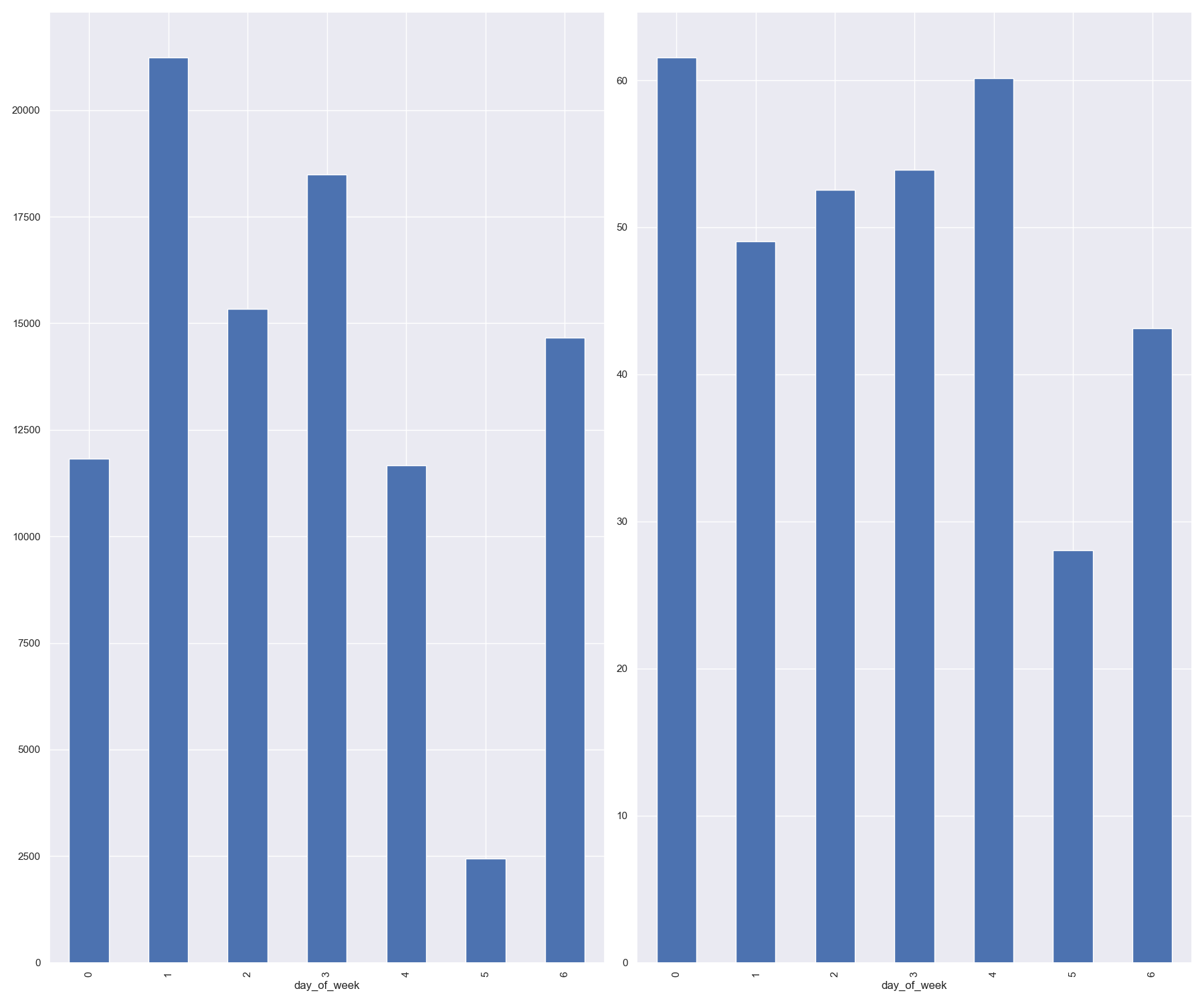
Now we have drilled down into the data quite a bit. Now let’s figure out the spatial characteristics of the Narva station data.
In [65]: print(len(narva_lk['geometry'].unique() ))
6
Although they share the same station name, there are still a few different geometries in this data slice. However, we can’t aggregate directly on the Shapely geometry object type. But we know we can aggregate/groupby on strings. So now we use the WKT geometry text representation in order to group on those.
Shapely support loading and “dumping” geometries in WKT format.
In [66]: narva_lk['wkt'] = narva_lk['geometry'].apply(lambda g: g.wkt)
In [67]: narva_lk.groupby(by='wkt')['count'].mean().plot(kind='bar')
Out[67]: <AxesSubplot:xlabel='wkt'>
In [68]: plt.tight_layout()
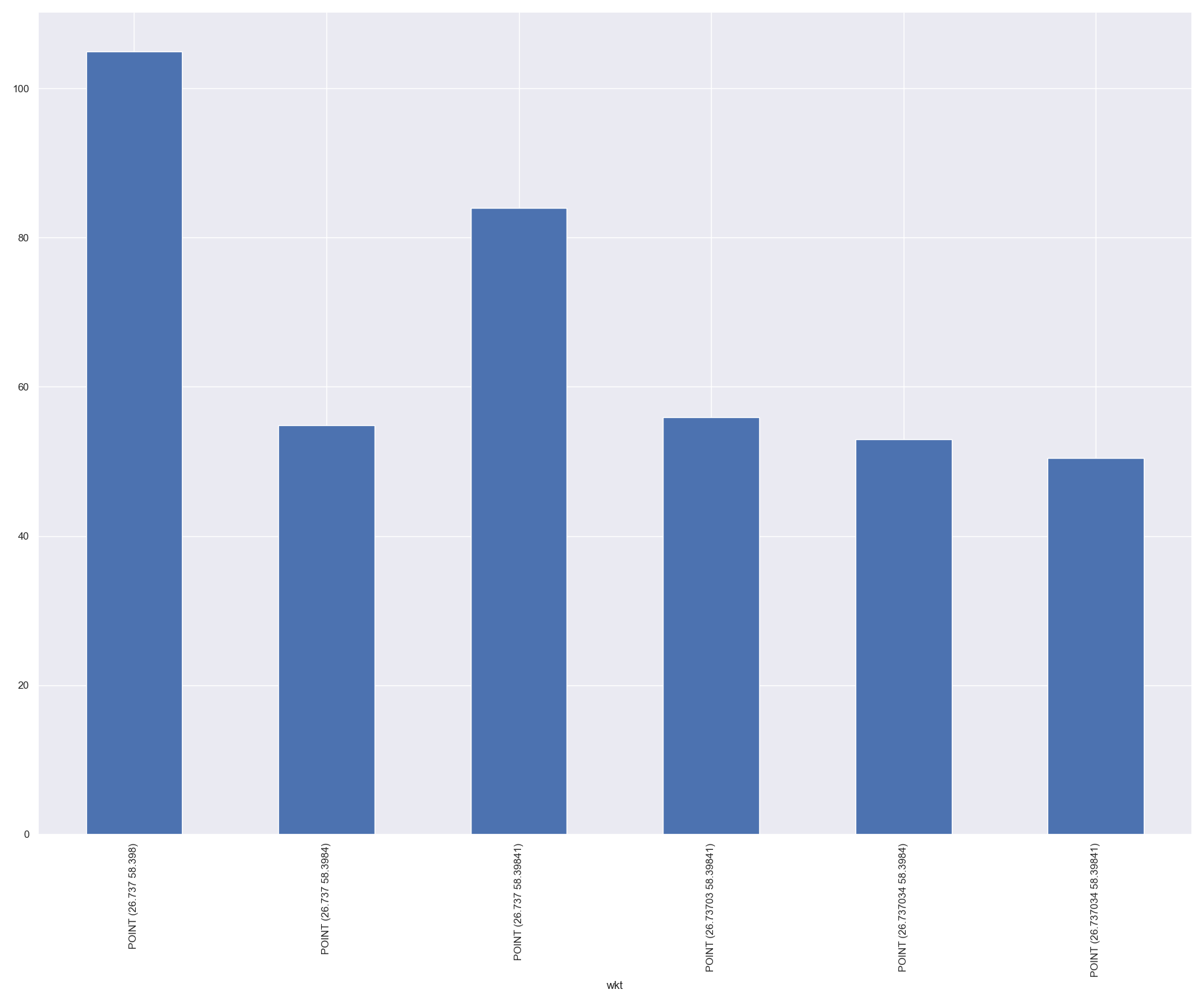
Let’s now apply the steps on the whole dataset in order to make a map to visualise the traffic counts in Tartu on Tuesdays. At first we create our “day of week” column, and only subselect the observations for tuesdays (day=1). Secondly, we “destructure” our geometries to WKT for the spatial aggregation. We could potentially also use the station name, if we could agree that the single points are too close to each other to be meaningfully visualised separately.
In [69]: traffic_data['day_of_week'] = traffic_data['datetime'].apply(lambda dtx: dtx.day_of_week)
In [70]: tuesday_traffic = traffic_data.loc[traffic_data['day_of_week'] == 1].copy()
In [71]: tuesday_traffic['wkt'] = tuesday_traffic['geometry'].apply(lambda g: g.wkt)
Now we will groupby WKT (i.e. location) at first, then take the mean for all observations at a single point (the location), and the mean represent the average of counts on all Tuesdays. We rejoin them into a separate geodataframe which we need to reproject into EPSG:3301 (Estonia) to plotted together with our OSM urban data from above.
In [72]: from shapely import wkt
In [73]: agg_traffic_day = []
In [74]: for geom, sub_df in tuesday_traffic.groupby(by='wkt'):
....: all_counts = sub_df['count'].mean()
....: name = sub_df['name'].to_list()[0]
....: agg_traffic_day.append( { 'name': name, 'count': all_counts, 'geometry': wkt.loads(geom)} )
....:
In [75]: tues_agg = pd.DataFrame(agg_traffic_day)
In [76]: tues_agg_3301 = gpd.GeoDataFrame(tues_agg, geometry='geometry', crs=4326).to_crs(3301)
Finally, we put the layers together in a single plot. The traffic counters seem to be distributed rather around the city than within.
In [77]: plt.style.use('dark_background')
In [78]: fig, ax = plt.subplots(figsize=(15,12))
In [79]: streets_3301.plot(ax=ax, linewidth=2, alpha=0.9, color="gray")
Out[79]: <AxesSubplot:>
In [80]: streets_3301.plot(ax=ax, linewidth=2, alpha=0.9, column='speed', cmap='Greens_r')
Out[80]: <AxesSubplot:>
In [81]: tues_agg_3301.plot(ax=ax, markersize=150, edgecolor='gray', lw=1, column="count", cmap="Reds", alpha=0.8, legend=True)
Out[81]: <AxesSubplot:>
In [82]: plt.title("Average traffic flow (number cars passing) on Tuesdays during March 2021")
Out[82]: Text(0.5, 1.0, 'Average traffic flow (number cars passing) on Tuesdays during March 2021')
In [83]: plt.tight_layout()
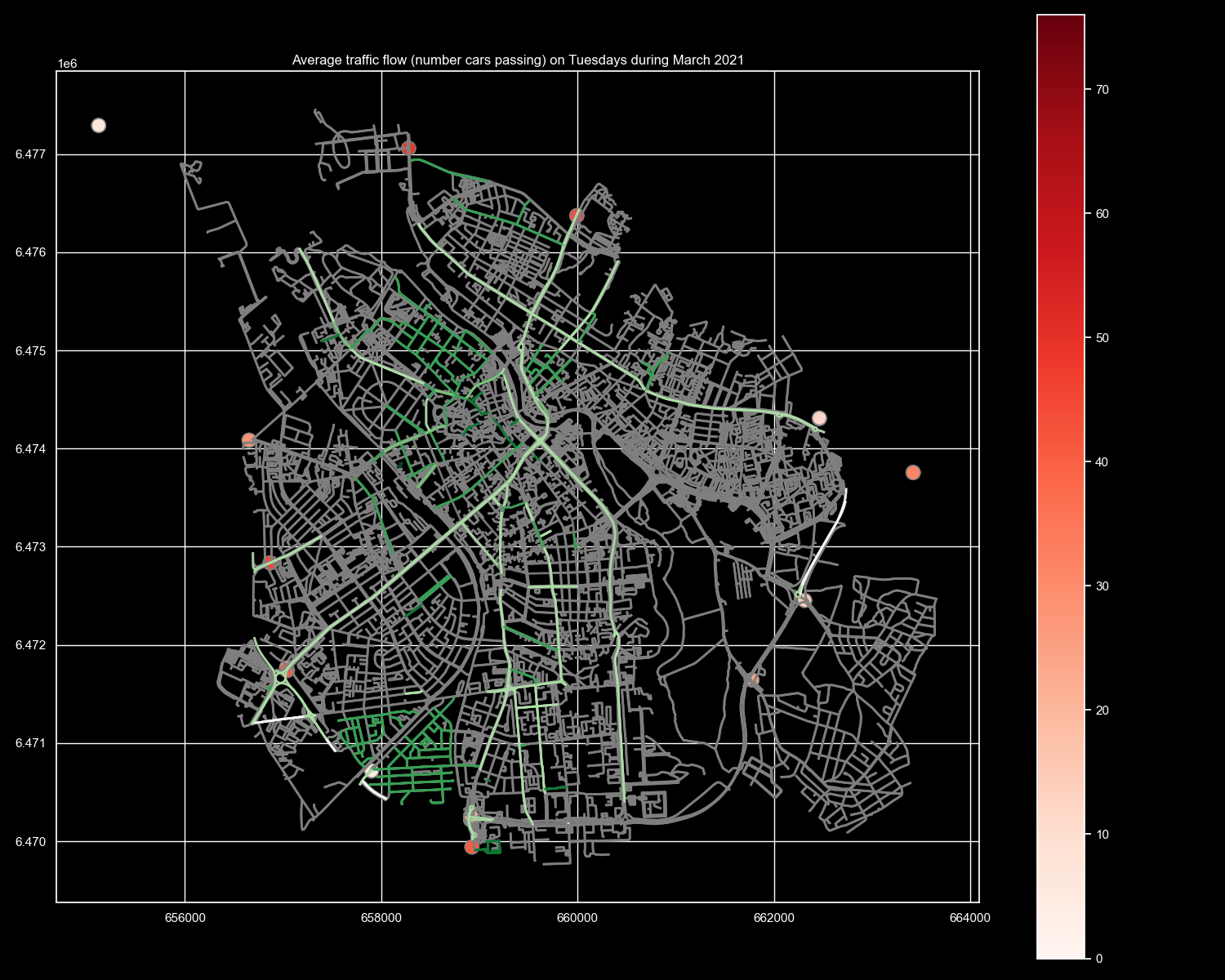
Hint
This code block shows an example of how to access the data. Use with care, don’t overload the server with unbounded queries, such as too larger time spans for example. There are different query patterns possible as well, such as via envelope/bbox.
import requests import datetime query_url = "https://gis.tartulv.ee/arcgis/rest/services/Hosted/LiiklusLoendLaneBigDM/FeatureServer/0/query" starttime = datetime.datetime(2021, 10, 4, 0, 0, 0) endtime = datetime.datetime(2021, 10, 10, 23, 59, 59) ts1 = int(starttime.timestamp()) * 1000 ts2 = int(endtime.timestamp()) * 1000 # available fields = "name":"LKL_Roomu","count":13,"globalid1":"{B253DBFB-8596-F347-7873-D9C433520079}","latitude":58.378952,"lane":1,"objectid":297054,"globalid":6.5485272E8,"longitude":26.777779,"time":1616432400041 params = {'f': 'geojson','returnGeometry': 'true', 'resultRecordCount': 40, 'where': "name='LKL_Roomu'", "time":"{t1}, {t2}", "outFields": "objectid,name,lane,count,time"} req = requests.get(query_url, params=params) import geopandas as gpd gdata = req.json() gdf = gpd.GeoDataFrame.from_features(gdata['features']) gdf.crs = "EPSG:4326"