sed, awk ja perl praktiliselt
Selles peatükis teeme sissejuhatuse voopõhisesse tekstimuutmisse, väljade töötlemisse ja perl-i one-lineritesse.
Loogika
sed, awk ja perl on kasulikud siis, kui lihtsast filtreerimisest enam ei piisa, aga eraldi programmi kirjutamine oleks liiga palju. Need on seotud tekstivoo peatükkidega, sest töötavad peamiselt ridade, väljade ja mustrite peal.
Hea tööjaotus on sageli selline:
sedlihtsateks asendusteksawkväljade ja veergude töötlemiseksperlsiis, kui vaja on tugevamat regulaaravaldiste loogikat või natuke rikkamat ühe rea programmi
Kiirspikker
sed 's/vana/uus/'asendab esimese vaste realsed 's/vana/uus/g'asendab kõik vasted realawk '{print $1}'trükib esimese väljaawk -F: '{print $1}'kasutab koolonit eraldajanaperl -pe 's/vana/uus/g'käib read läbi ja prindib tulemuse väljaperl -ne 'print if /muster/'käib read läbi, aga prindib ainult siis, kui tingimus sobibperl -e '...'käivitab antud Perl-koodi otse käsurealt
Käivita need käsud
echo 'kass koer kass' | sed 's/kass/rebane/'
echo 'kass koer kass' | sed 's/kass/rebane/g'
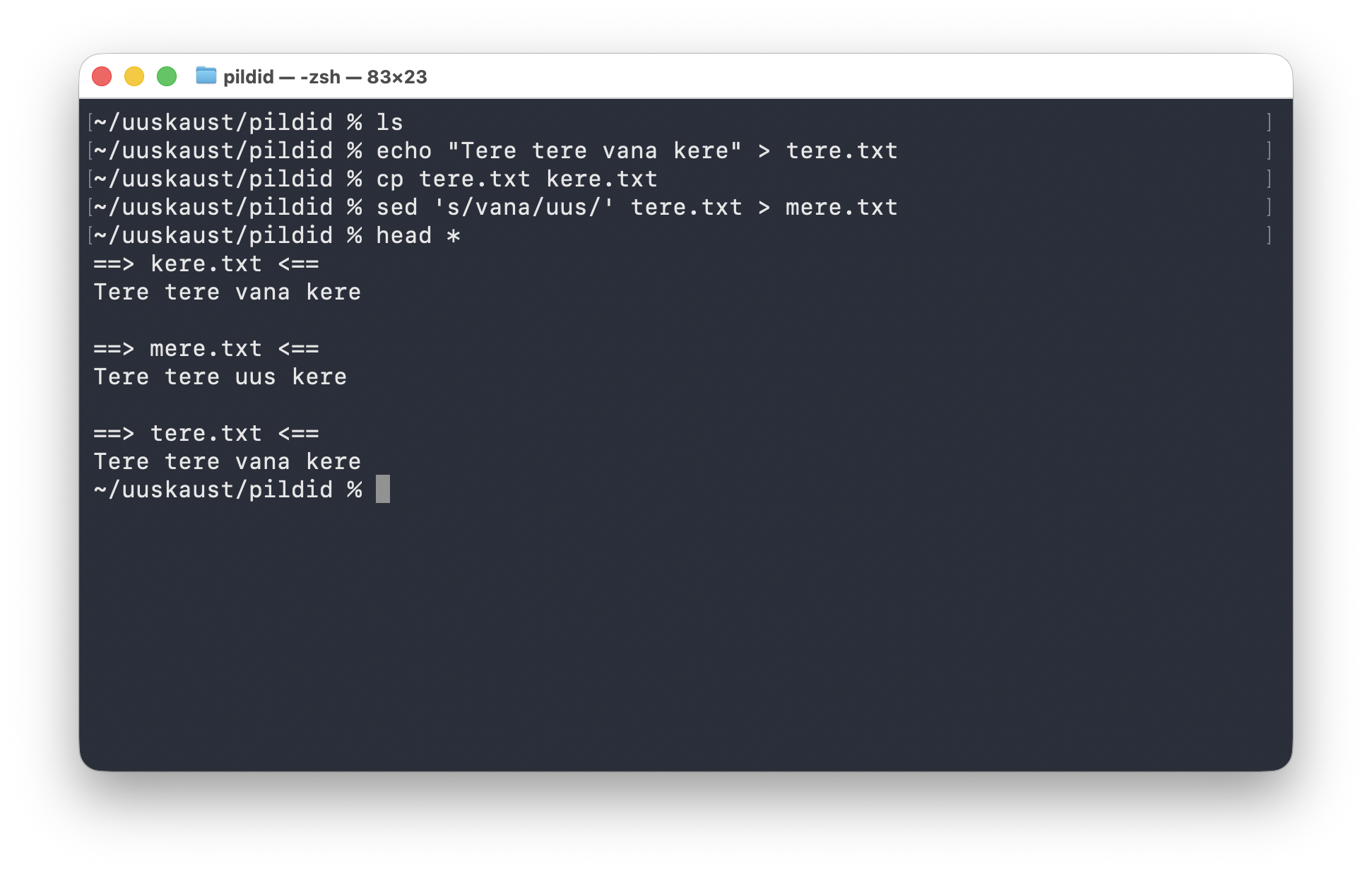
tere.txt kopeeritakse failiks kere.txt, seejärel tehakse käsuga sed 's/vana/uus/' uus fail mere.txt, ja head * abil võrreldakse kõigi kolme faili algust.Selle pildi loogika on järgmine:
echo "Tere tere vana kere" > tere.txtloob algse failicp tere.txt kere.txtteeb samast sisust koopiased 's/vana/uus/' tere.txt > mere.txtloeb failitere.txt, asendab esimese vaste ja kirjutab tulemuse uude failihead *näitab kolme faili algust kõrvuti
Oluline tähelepanek on see, et sed ei muuda siin algset faili kohapeal. Tulemuse saab uude faili suunata märgiga >.
Üks asendus või kõik asendused
sed-i üks kõige tähtsamaid erinevusi on see, kas tehakse üks asendus või kõik asendused real.
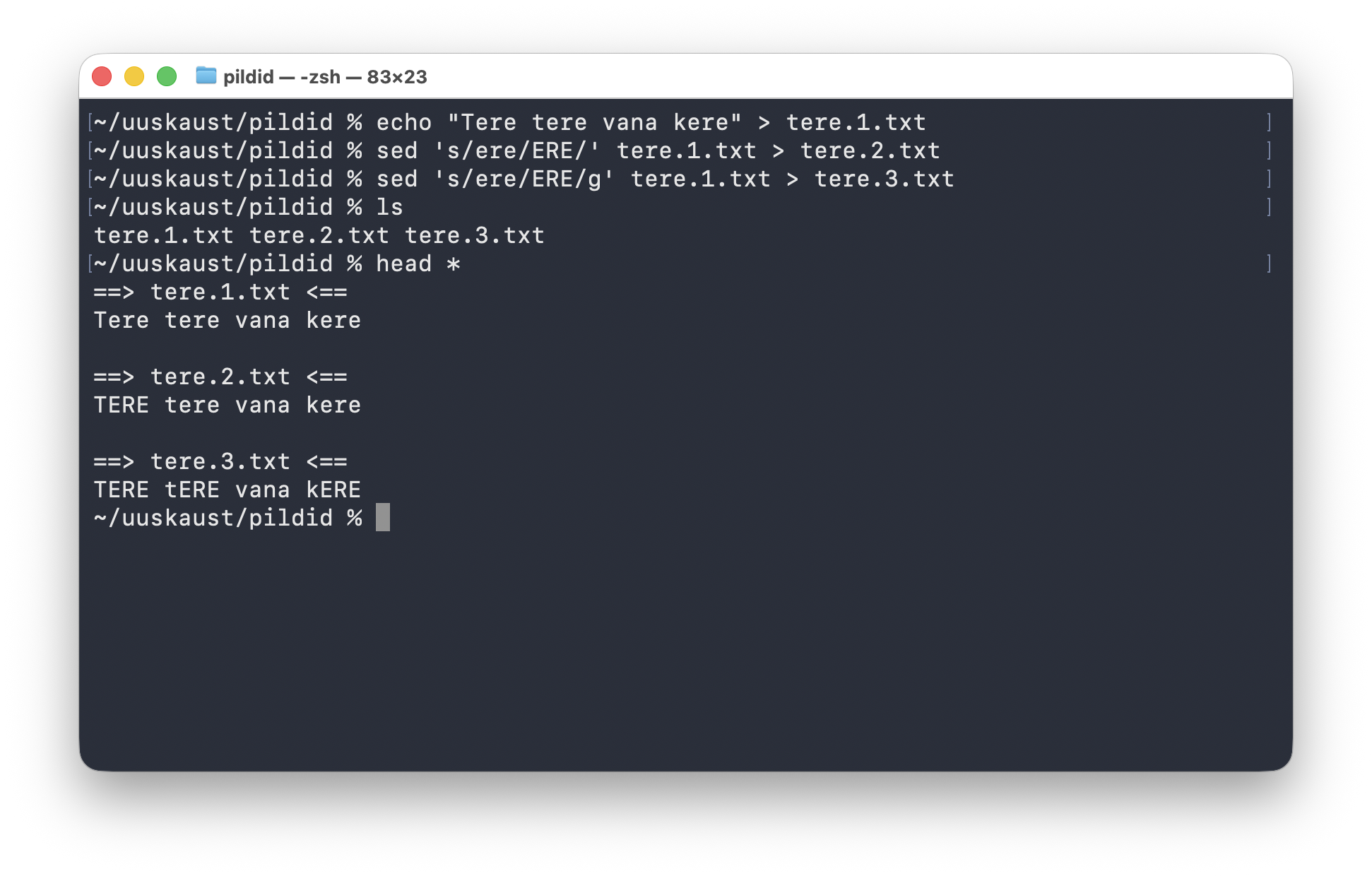
tere.1.txt tehakse kõigepealt käsk sed 's/ere/ERE/', mis muudab ainult esimese vaste, ja seejärel sed 's/ere/ERE/g', mis muudab kõik vasted.Selle pildi sees on näha kaks väga erinevat tulemust:
sed 's/ere/ERE/' tere.1.txt > tere.2.txtmuudab ainult rea esimese vastesed 's/ere/ERE/g' tere.1.txt > tere.3.txtmuudab kõik vasted samal realhead *näitab pärast kõiki kolme faili kõrvuti, nii et vahe on kohe nähtav
Rusikareegel on lihtne:
- ilma
g-ta muudetakse tavaliselt ainult esimene vaste real gtähendabglobal, ehk kõik vasted sellel real
printf 'Mari:20\nJaan:21\n' | awk -F: '{print $1}'
printf 'Mari:20\nJaan:21\n' | awk -F: '{print $1, $2}'
echo 'kass koer kass' | perl -pe 's/kass/rebane/g'
printf 'Mari\nJaan\n' | perl -ne 'print if /Ja/'
printf 'Mari:20\nJaan:21\n' | perl -F: -lane 'print $F[0]'
perl one-linerite loogika
Kui kirjutad:
perl -pe 's/kass/rebane/g'
siis:
-etähendab, et kood tuleb käsurealt-ptähendab, et Perl loeb sisendi rida-realt läbi ja prindib iga rea vaikimisi välja
See teeb perl -pe kuju väga heaks voopõhisteks asendusteks.
Kui kirjutad:
perl -ne 'print if /Ja/'
siis:
-ntähendab, et Perl käib read küll läbi, aga ei prindi neid automaatselt- sina otsustad ise, millal
printteha
See kuju on kasulik siis, kui tahad teha väikest tingimusloogikat.
Fun fact: algarvud regexiga
See järgmine näide ei ole kõige praktilisem viis algarvude leidmiseks, aga ta on väga hea näide sellest, kui veidralt võimsad võivad perl-i one-linerid olla:
seq 2 200 | perl -nlE 'say if ("a" x $_) !~ /^(aa+)\1+$/'
See kuju on siin meelega võimalikult lihtne. Kuna alustame vahemikku 2-st, ei pea me eraldi 0 ja 1 juhtumeid regexis välja filtreerima.
Mõte on selline:
- iga arv teisendatakse ajutiselt ühe tähe korduseks, näiteks
7muutub kujuleaaaaaaa - regex proovib leida, kas see rida koosneb mingist väiksemast plokist, mida saab mitu korda korrata
- kui saab, siis arv ei ole algarv
- kui ei saa, siis prinditakse arv välja
See tähendab sisuliselt: “prindi ainult need arvud, mida ei saa kirjutada kujul m * n, kus mõlemad on suuremad kui 1.”
Praktilises skriptis oleks tavaliselt mõistlikum kasutada tavapärast jaguvuskontrolli, aga ühe rea triki või loengu-näite jaoks on see väga meeldejääv.
Millal mida kasutada
sedsobib lihtsaks voopõhiseks asenduseksawksobib väljade ja ridade töötlemiseksperlsobib keerukamaks mustriloogikaks, mitmeks asenduseks või natuke rikkamaks ühe rea programmiks
Näiteks:
- kui tahad lihtsalt sõna välja vahetada, siis
sedon sageli kõige loetavam - kui tahad võtta teisest veerust väärtuse, siis
awkon sageli kõige loomulikum - kui tahad korraga filtreerida, asendada ja kasutada tugevamaid regex'e, siis
perlvõib olla kõige mugavam
Kui töö kasvab keerukaks, võib mõnikord olla selgem kasutada Pythonit. Aga väikeste ühekordsete ülesannete jaoks on sed, awk ja perl väga tugevad.
Minitest
- Asenda reas üks sõna teisega.
- Võta välja kooloniga eraldatud faili esimene väli.
- Prindi
awkabil ainult teine veerg. - Filtreeri
perl -neabil välja ainult need read, kus on kindel muster. - Tee
perl -peabil globaalne asendus kogu sisendi ulatuses.