Introduction to Geopandas¶
Downloading data¶
For this lesson we are using data that you can download from here.
Once you have downloaded the Data.zip file into your geopython directory (ideally undr L2), you can unzip the file using e.g. 7Zip (on Windows).
DAMSELFISH_distributions.dbf DAMSELFISH_distributions.prj DAMSELFISH_distributions.sbn DAMSELFISH_distributions.sbx DAMSELFISH_distributions.shp DAMSELFISH_distributions.shp.xml DAMSELFISH_distributions.shx
The Data folder includes a Shapefile called DAMSELFISH_distribution.shp (and files related to it).
Reading a Shapefile¶
Spatial data can be read easily with geopandas using gpd.from_file() -function:
# Import necessary module
In [1]: import geopandas as gpd
# Set filepath relative to your ``geopython`` working directory, from where your Jupyter Notebook or spyder also should be started
In [2]: fp = r"L2\Data\DAMSELFISH_distributions.shp"
# or full path
# fp = r"C:\Users\Alex\geopython\L2\Data\DAMSELFISH_distributions.shp"
# Read file using gpd.read_file()
In [3]: data = gpd.read_file(fp)
Let’s see what datatype is our ‘data’ variable
In [4]: type(data)
Out[4]: geopandas.geodataframe.GeoDataFrame
So from the above we can see that our data -variable is a
GeoDataFrame. GeoDataFrame extends the functionalities of
pandas.DataFrame in a way that it is possible to use and handle
spatial data within pandas (hence the name geopandas). GeoDataFrame have
some special features and functions that are useful in GIS.
Let’s take a look at our data and print the first 5 rows using the head() -function prints the first 5 rows by default
In [5]: data.head()
Out[5]:
ID_NO ... geometry
0 183963.0 ... POLYGON ((-115.6437454219999 29.71392059300007...
1 183963.0 ... POLYGON ((-105.589950704 21.89339825500002, -1...
2 183963.0 ... POLYGON ((-111.159618439 19.01535626700007, -1...
3 183793.0 ... POLYGON ((-80.86500229899997 -0.77894492099994...
4 183793.0 ... POLYGON ((-67.33922225599997 -55.6761029239999...
[5 rows x 24 columns]
Let’s also take a look how our data looks like on a map. If you just
want to explore your data on a map, you can use .plot() -function
in geopandas that creates a simple map out of the data (uses
matplotlib as a backend):
In [6]: data.plot();

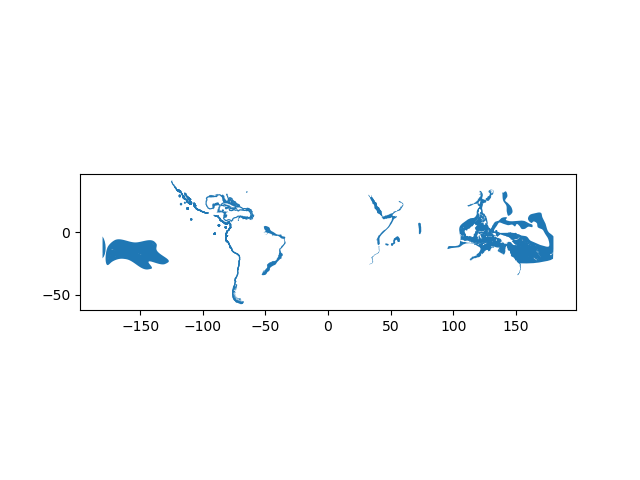
Writing a Shapefile¶
Writing a new Shapefile is also something that is needed frequently.
Let’s select 50 first rows of the input data and write those into a
new Shapefile by first selecting the data using index slicing and
then write the selection into a Shapefile with the gpd.to_file() -function:
# Create a output path for the data
out_file_path = r"Data\DAMSELFISH_distributions_SELECTION.shp"
# Select first 50 rows, this a the numpy/pandas syntax to ``slice`` parts out a dataframe or array, from position 0 until (excluding) 50
selection = data[0:50]
# Write those rows into a new Shapefile (the default output file format is Shapefile)
selection.to_file(out_file_path)
Task: Open the Shapefile now in QGIS (or ArcGIS) on your computer, and see how the data looks like.
Geometries in Geopandas¶
Geopandas takes advantage of Shapely’s geometric objects. Geometries are typically stored in a column called geometry (or geom). This is a default column name for storing geometric information in geopandas.
Let’s print the first 5 rows of the column ‘geometry’:
# It is possible to use only specific columns by specifying the column name within square brackets []
In [7]: data['geometry'].head()
Out[7]:
0 POLYGON ((-115.6437454219999 29.71392059300007...
1 POLYGON ((-105.589950704 21.89339825500002, -1...
2 POLYGON ((-111.159618439 19.01535626700007, -1...
3 POLYGON ((-80.86500229899997 -0.77894492099994...
4 POLYGON ((-67.33922225599997 -55.6761029239999...
Name: geometry, dtype: object
Since spatial data is stored as Shapely objects, it is possible to use all of the functionalities of Shapely module that we practiced earlier.
Let’s print the areas of the first 5 polygons:
# Make a selection that contains only the first five rows
In [8]: selection = data[0:5]
We can iterate over the selected rows using a specific .iterrows() -function in (geo)pandas and print the area for each polygon:
In [9]: for index, row in selection.iterrows():
...: poly_area = row['geometry'].area
...: print("Polygon area at index {0} is: {1:.3f}".format(index, poly_area))
...:
Polygon area at index 0 is: 19.396
Polygon area at index 1 is: 6.146
Polygon area at index 2 is: 2.697
Polygon area at index 3 is: 87.461
Polygon area at index 4 is: 0.001
Hence, as you might guess from here, all the functionalities of Pandas are available directly in Geopandas without the need to call pandas separately because Geopandas is an extension for Pandas.
Let’s next create a new column into our GeoDataFrame where we calculate and store the areas individual polygons. Calculating the areas of polygons is really easy in geopandas by using GeoDataFrame.area attribute:
In [10]: data['area'] = data.area
Let’s see the first 2 rows of our ‘area’ column.
In [11]: data['area'].head(2)
Out[11]:
0 19.396254
1 6.145902
Name: area, dtype: float64
So we can see that the area of our first polygon seems to be 19.39 and 6.14 for the second polygon. They correspond to the ones we saw in previous step when iterating rows, hence, everything seems to work as it should. Let’s check what is the min and the max of those areas using familiar functions from our previous Pandas lessions.
# Maximum area
In [12]: max_area = data['area'].max()
# Mean area
In [13]: mean_area = data['area'].mean()
In [14]: print("Max area: {:.2f}\nMean area: {:.2f}".format(round(max_area, 2), round(mean_area, 2)))
Max area: 1493.20
Mean area: 19.96
So the largest Polygon in our dataset seems to be 1494 square decimal degrees (~ 165 000 km2) and the average size is ~20 square decimal degrees (~2200 km2).
Creating geometries into a GeoDataFrame¶
Since geopandas takes advantage of Shapely geometric objects it is possible to create a Shapefile from a scratch by passing Shapely’s geometric objects into the GeoDataFrame. This is useful as it makes it easy to convert e.g. a text file that contains coordinates into a Shapefile.
Let’s create an empty GeoDataFrame.
# Import necessary modules first
import pandas as pd
import geopandas as gpd
from shapely.geometry import Point, Polygon
import fiona
# Create an empty geopandas GeoDataFrame
newdata = gpd.GeoDataFrame()
# Let's see what's inside
In [15]: newdata
Out[15]:
Empty GeoDataFrame
Columns: []
Index: []
The GeoDataFrame is empty since we haven’t placed any data inside.
Let’s create a new column called geometry that will contain our Shapely objects:
# Create a new column called 'geometry' to the GeoDataFrame
In [16]: newdata['geometry'] = None
# Let's see what's inside
In [17]: newdata
Out[17]:
Empty GeoDataFrame
Columns: [geometry]
Index: []
Now we have a geometry column in our GeoDataFrame but we don’t have any data yet.
Let’s create a Shapely Polygon repsenting the Helsinki Senate square that we can insert to our GeoDataFrame:
# Coordinates of the Helsinki Senate square in Decimal Degrees
In [18]: coordinates = [(24.950899, 60.169158), (24.953492, 60.169158), (24.953510, 60.170104), (24.950958, 60.169990)]
# Create a Shapely polygon from the coordinate-tuple list
In [19]: poly = Polygon(coordinates)
# Let's see what we have
In [20]: poly
Out[20]: <shapely.geometry.polygon.Polygon at 0x1500f65c6a0>
So now we have appropriate Polygon -object.
Let’s insert the polygon into our ‘geometry’ column in our GeoDataFrame:
# Insert the polygon into 'geometry' -column at index 0
In [21]: newdata.loc[0, 'geometry'] = poly
# Let's see what we have now
In [22]: newdata
Out[22]:
geometry
0 POLYGON ((24.950899 60.169158, 24.953492 60.16...
Now we have a GeoDataFrame with Polygon that we can export to a Shapefile.
Let’s add another column to our GeoDataFrame called Location with the text Helsinki Senate Square.
# Add a new column and insert data
In [23]: newdata.loc[0, 'Location'] = 'Helsinki Senate Square'
# Let's check the data
In [24]: newdata
Out[24]:
geometry Location
0 POLYGON ((24.950899 60.169158, 24.953492 60.16... Helsinki Senate Square
Now we have additional information that is useful to be able to recognize what the feature represents.
Before exporting the data it is useful to determine the coordinate reference system (projection) for the GeoDataFrame.
GeoDataFrame has a property called .crs that (more about projection on next tutorial) shows the coordinate system of the data which is empty (None) in our case since we are creating the data from the scratch:
In [25]: print(newdata.crs)
None
Let’s add a crs for our GeoDataFrame. A Python module called
fiona has a nice function called from_epsg() for passing
coordinate system for the GeoDataFrame. Next we will use that and
determine the projection to WGS84 (epsg code: 4326):
# Import specific function 'from_epsg' from fiona module
In [26]: from fiona.crs import from_epsg
# Set the GeoDataFrame's coordinate system to WGS84
In [27]: newdata.crs = from_epsg(4326)
# Let's see how the crs definition looks like
In [28]: newdata.crs
Out[28]: {'init': 'epsg:4326', 'no_defs': True}
Finally, we can export the data using GeoDataFrames .to_file() -function.
The function works similarly as numpy or pandas, but here we only need to provide the output path for the Shapefile:
# Determine the output path for the Shapefile
out_file = r"Data\Senaatintori.shp"
# Write the data into that Shapefile
newdata.to_file(out_file)
Now we have successfully created a Shapefile from the scratch using only Python programming. Similar approach can be used to for example to read coordinates from a text file (e.g. points) and create Shapefiles from those automatically.
Task: check the output Shapefile in QGIS and make sure that the attribute table seems correct.
Practical example: Save multiple Shapefiles¶
One really useful function that can be used in Pandas/Geopandas is .groupby().
With the Group by function we can group data based on values on selected column(s).
Let’s group individual fish species in DAMSELFISH_distribution.shp and export to individual Shapefiles.
Note
If your data -variable doesn’t contain the Damselfish data anymore, read the Shapefile again into memory using gpd.read_file() -function*
# Group the data by column 'BINOMIAL'
In [29]: grouped = data.groupby('BINOMIAL')
# Let's see what we got
In [30]: grouped
Out[30]: <pandas.core.groupby.groupby.DataFrameGroupBy object at 0x00000150118B6198>
The groupby -function gives us an object called DataFrameGroupBy which is similar to list of keys and values (in a dictionary) that we can iterate over.
# Iterate over the group object
In [31]: for key, values in grouped:
....: individual_fish = values
....: print(key)
....:
Abudefduf concolor
Abudefduf declivifrons
Abudefduf troschelii
Amphiprion sandaracinos
Azurina eupalama
Azurina hirundo
Chromis alpha
Chromis alta
Chromis atrilobata
Chromis crusma
Chromis cyanea
Chromis flavicauda
Chromis intercrusma
Chromis limbaughi
Chromis pembae
Chromis punctipinnis
Chrysiptera flavipinnis
Hypsypops rubicundus
Microspathodon bairdii
Microspathodon dorsalis
Nexilosus latifrons
Stegastes acapulcoensis
Stegastes arcifrons
Stegastes baldwini
Stegastes beebei
Stegastes flavilatus
Stegastes leucorus
Stegastes rectifraenum
Stegastes redemptus
Teixeirichthys jordani
# Let's see what is the LAST item that we iterated
In [32]: individual_fish
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������Out[32]:
ID_NO ... area
27 154915.0 ... 38.671198
28 154915.0 ... 37.445735
29 154915.0 ... 16.939460
30 154915.0 ... 10.126967
31 154915.0 ... 7.760303
32 154915.0 ... 3.434236
33 154915.0 ... 2.408620
[7 rows x 25 columns]
From here we can see that an individual_fish variable now contains all the rows that belongs to a fish called Teixeirichthys jordani. Notice that the index numbers refer to the row numbers in the
original data -GeoDataFrame.
Let’s check again the datatype of the grouped object and what does the key variable contain
In [33]: type(individual_fish)
Out[33]: geopandas.geodataframe.GeoDataFrame
In [34]: print(key)
���������������������������������������������Teixeirichthys jordani
As can be seen from the example above, each set of data are now grouped into separate GeoDataFrames that we can export into Shapefiles using the variable key
for creating the output filepath names. Here we use a specific string formatting method to produce the output filename using the .format() (read more here (we use the new style with Python 3)).
Let’s now export those species into individual Shapefiles.
# Determine outputpath
out_folder = "Data"
# Create a new folder called 'Results' (if does not exist) to that folder using os.makedirs() function
result_folder = os.path.join(out_folder, 'Results')
if not os.path.exists(result_folder):
os.makedirs(result_folder)
# Iterate over the
for key, values in grouped:
# Format the filename (replace spaces with underscores)
updated_key = key.replace(" ", "_")
out_name = updated_key + ".shp"
# Print some information for the user
print( "Processing: {}".format(out_name) )
# Create an output path, we join two folder names together without using slash or back-slash -> avoiding operating system differences
outpath = os.path.join(result_folder, out_name)
# Export the data
values.to_file(outpath)
Now we have saved those individual fishes into separate Shapefiles and named the file according to the species name. These kind of grouping operations can be really handy when dealing with Shapefiles. Doing similar process manually would be really laborious and error-prone.