Peatükk 17 Kõnesüntees ja resüntees Praatis
Tekst-kõne sünteesiga on tänapäeval ilmselt kokku puutunud igaüks: see on integreeritud uudisportaalidesse võimalusega uudise tekst ette lugeda, auto navigatsiooniseadmes annab kõnesüntees liiklemiseks hääljuhiseid, AI-põhised häälassistendid (nt ChatGPT, Apple Siri, Google Gemini, Amazon Alexa jpt) räägivad kõnesünteesi abil.
Kõnelevaid masinaid on üritatud luua juba arvutieelsel ajal ja varasemad katsetused on olnud üritada kõneloome protsessi järele aimata. Kõne arusaadavuse ja loomulikkuse poolest pole kuigi edukaks osutunud meetodid, mis algusest lõpuni üritavad järgi teha seda, kuidas inimene kõnet toodab. Tänapäeval kasutatakse neid meetodeid aga kõne uurimisel, kuna nende meetodite puhul on võimalik sünteesi parameetreid väga täpselt kontrollida. Kõnetrakti füüsilisel mudelil põhineb näiteks Takayuki Arai loodud Kõriorel,68 mida võib näha Eesti Rahva Muuseumis (vt ka Arai 2019).
Tekst-kõne sünteesis on edukamaks osutunud meetodid, mis kasutavad salvestatud kõne korpust, mitte ei genereeri kõnesignaali akustiliste või artikulatoorsete parameetrite järgi. Üks esimesi edukaid levinud laiatarbe kõnesünteesi meetodeid on difoonsüntees, mida kasutati peamiselt 1990. aastate lõpus ja 2000. aastate alguses. Eesti keele tekst-kõne difoonsüntesaator valmis 1999. aastal.
Difoonsünteesi puhul on loomuliku kõne salvestusest välja lõigatud häälikupaarid, mille kombinatsioonidest pannakse kokku uut kõnet. Häälikupaare kasutatakse sellepärast, et siirded ühelt häälikult teisele oleksid loomulikumad – kõnes liiguvad hääldusorganid ühe hääliku moodustuskohalt teise hääliku moodustuskohale sujuvalt ja iga eelnev häälik mõjutab järgmist. Niimoodi sünteesitaks näiteks sõna tere viiest andmebaasis olemas olevast jupist: (paus + /t/ esimene pool)(/t/ teine pool + /e/ esimene pool)(/e/ teine pool + /r/-i esimene pool)(/r/-i teine pool + /e/ esimene pool)(/e/ teine pool + paus) (vt Mihkla & Meister 2002).
Alates 2000. aastate algusest hakati arendama korpuspõhist sünteesi, mille põhimõte sarnaselt difoonsünteesile oli panna kõne kokku loomulikust kõnest salvestatud lõikudest. Ainult et korpuspõhise sünteesi korpus sisaldab rohkem ja suuremaid kõnelõike ning sagedasemaid sõnu. Korpusepõhine kõnesüntesaator paneb uue teksti kokku võimalikult suurtest andmebaasis olevatest juppidest. Mida suuremaid olemasolevaid juppe on võimalik kasutada, seda loomulikum tulemus on.
Tänapäeval on enim levinud tehisnärvivõrkudel põhinev süntees. See kasutab võimalikult suurt kõnekorpust, mille põhjal õpib loomulikus kõnes esinevaid mustreid. Selle meetodiga on tulemus ka prosoodia ja intonatsiooni osas palju loomulikum kui varasemate meetoditega.
Loe eesti keele kõnesünteesi kohta ja proovi erinevaid süntesaatoreid.
- Eesti Keele Instituudi kõnesüntees: https://koneveeb.ee/
- Tartu Ülikooli keeletenoloogia uurimisrühma kõnesüntees: https://neurokone.ee/
17.1 Tekst-kõne süntees Praatis
Vali menüüst New > Text-to-speech synthesis > Create SpeechSynthesizer. Vali keel, milles tahad sünteesida (valikus on palju keeli, nende hulgas ka eesti) ja sünteeshääl.69
Objektiloendisse tekib objekt SpeechSynthesizer, mille dünaamilises menüüs on kaks käsku: Play text... ja To Sound..., millest mõlemal on üks teksikast, kuhu saab kirjutada teksti ja käskudest esimene loeb selle ette, teine tekitab Sound-objekti (seda saab omakorda salvestada helifailina).
17.2 Resüntees Praatis
Resünteesiks nimetatakse loomulikul viisil hääldatud kõne mingite parameetrite (kestuse, formantide, põhitooni vm) muutmist. Resünteesi kasutatakse peamiselt kõnetaju uurimiseks.
Objektiaknas Sound-objekti dünaamilises menüüs Manipulate on käsk To manipulation.... Avaneb dialoogiaken, kus küsitakse põhitoonianalüüsiks vajalikke parameetreid (põhitoonianalüüsi sammu ja põhitooni ulatuse väärtuseid, nagu ka põhitoonianalüüsi To pitch... käskude puhul). Tekib uus Manipulation-objekt. Manipulation-objektil saab manipuleerida põhitooni ja kestust ning pärast sünteesida tagasi Sound-objektiks.
Käsk View & Edit avab ManipulationEditor’i. Nüüd on ekraan jagatud kolmeks (vt joonis 17.1):
- algse Sound-objekti helilaine,
- manipuleeritav põhitoonikontuur ja
- manipuleeritav kestus.
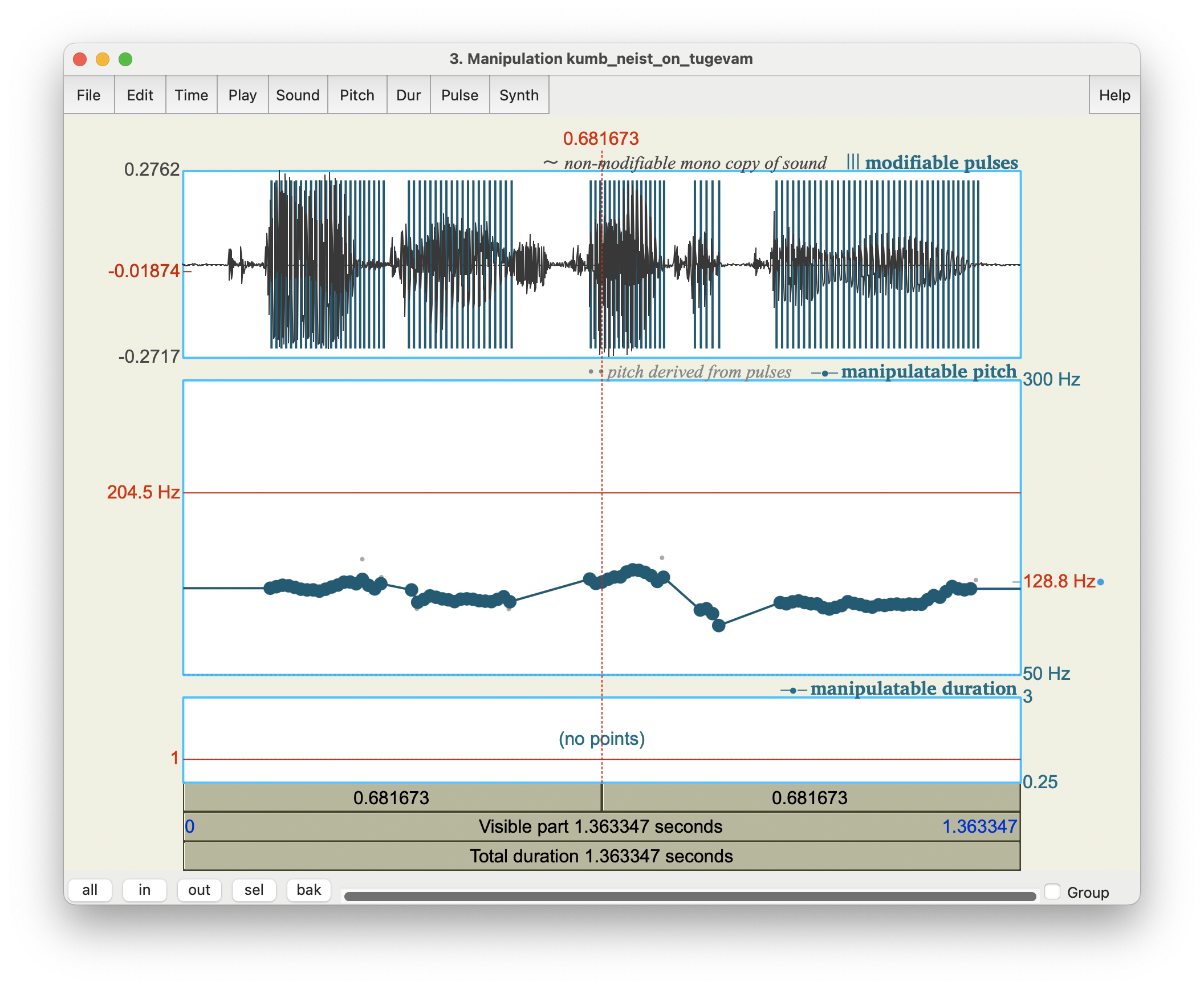
Joonis 17.1. ManipulationEditor’i ekraanipilt.
17.2.1 Põhitooni manipuleerimine
Põhitoonikõveral on punktid, mida saab hiirega edasi-tagasi ja üles-alla liigutada (tulevad ilmselt paremini nähtavale, kui natuke sisse suumida). Punktide algsed asukohad on taustal näha hallide punktikestena. Igale pulsile (ehk täisvõnkeperioodile) vastab üks punkt. Niimoodi neid ükshaaval liigutada on kaunis tülikas, kui just ei tahagi muuta põhitooni ühe täisvõnke piires. Kui üldisemat toonikontuuri manipuleerida, siis tasub punktide hulka vähendada.
Käsk Pitch > Stylize pitch... kaotab ära kõik punktid, mille vahel on väiksem erinevus kui kaks pooltooni70 (vaikimisi seadete puhul). Nii on põhitoonikontuur endine, aga punkte on oluliselt vähem. Nüüd on võimalik alles jäänud punkte nihutada ja vormida nii uus kontuur, tõstes ja langetades põhitooniliikumist sõnade või silpide kaupa. Näiteks joonisel 17.2 on lausungi kumb neist on tugevam alguses ja lõpus põhitooni langetatud ja tõstetud sõnal neist.
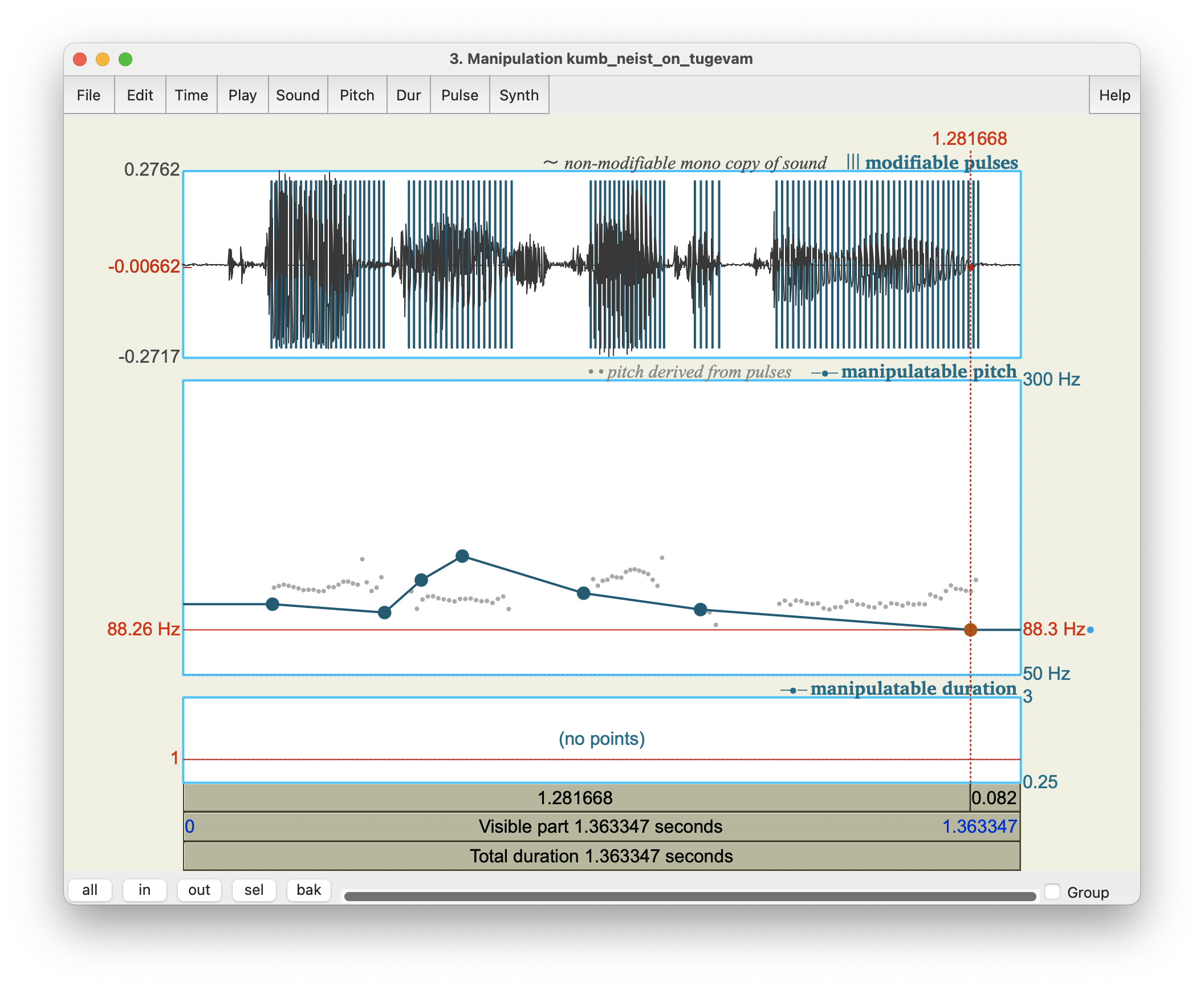
Joonis 17.2. Stiliseeritud ja manipuleeritud põhitoonikontuur.
Menüü Pitch > Remove pitch point(s) kustutab valitud punktid. Kui kustutada kõik punktid, kaob manipuleeritud põhitoon ära – sosinaks see ei muutu, kuuled lihtsalt algset tooni. Kui jätta alles üks punkt, on kogu heli põhitoon monotoonselt ühel kõrgusel.
Käsk Add pitch point lisab punkte.
Käsk Shift pitch frequencies... muudab kõigi punktide väärtust mingi ühiku võrra. Käsk Multiply pitch frequencies... korrutab kõigi punktide väärtuse mingi arvuga. Kui tahad põhitooni tõsta oktavi võrra, pane faktoriks 2, kui tahad tõsta 2 oktavit, pane faktoriks 3. Kui tahad langetada oktavi võrra, pane faktoriks 0,5.
Kui soovid võtta ühelt sõnalt (või fraasilt) põhitoonikontuuri ja anda selle teisele, siis seda saab nii:
- vali Sound-objekt, millelt tahad põhitoonikontuuri võtta, ja vali menüüst
Analyse Periodicity>To Pitch (filtered autocorrelation)...; - tekkinud Pitch-objekti menüüst vali
Convert>Down to PitchTier, millest tekib objekt PitchTier; - vali Sound-objekt, millele tahad teist põhitoonikontuuri külge kleepida. Mõõda selle kestus: menüüst
Query>Query time domain>Get start timejaGet end time;71 - vali objekt PitchTier ja menüüst
Modify>Modify times>Scale times to...pane uueks algusajaks eelmises sammus küsitud algus- ja lõpuaeg ja vajuta OK; - samal Sound-objektil vali menüüst
Manipulate>To Manipulation.... Tekib objekt Manipulation; - nüüd vali korraga objektid Manipulation ja PitchTier ning vajuta nuppu
Replace pitch tier.
PitchTier’i saab ka luua uue objektina ning määrata ise põhitoonipunktid:
- vali menüüst
New>Tiers>Create PitchTier.... Pane kestuseks manipuleeritava Sound-objekti kestus; - vali menüüst
Modify>Add point.... Lisa nii kõik olulised põhitoonipunktid; - vali korraga objektid Manipulation ja PitchTier ning vajuta nuppu
Replace pitch tier.
17.2.2 Kestuse manipuleerimine
Kestuse kihil ei ole alguses ühtegi punkti. Kui tahad kogu faili ulatuses ühtlaselt kiirust muuta, lisa üks punkt: menüü Dur käsk Add duration point. Punkti üles-alla liigutades muutub helilõigu kestus. Kui liigutad punkti üles (väärtus 1 on algne kestus), muutub kõne aeglasemaks, kui liigutad alla, siis kiiremaks.
Kui tahad heli ühe osa kestust muuta, lisa neli kestuspunkti: kaks tükki kõrvuti lõigu algusesse, kaks tükki lõigu lõppu. Välimiste punktide väärtus sea 1 peale, sisemiste väärtus suuremaks, kui tahad lõiku aeglustada, või väiksemaks, kui tahad lõiku kiirendada. Joonisel 17.3 on muudetud sõna on kestus 1,5 korda pikemaks: kui algne kestus oli umbes 131 ms, siis nüüd on 130 * 1,5 = 195 ms.
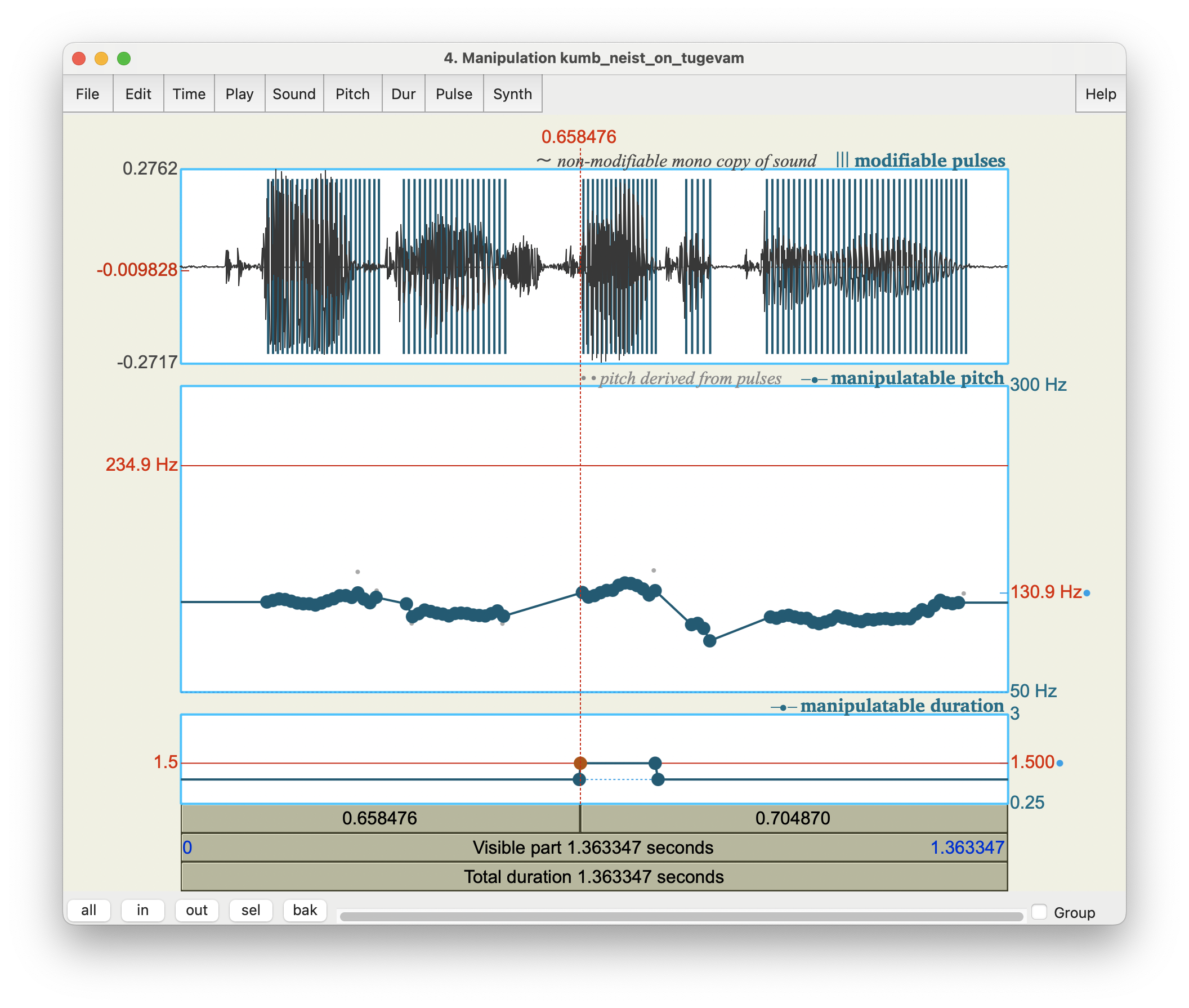
Joonis 17.3. Ühe sõna kestuse pikendamine.
Kui tahad kestuse punktide seadmist alustada otsast peale, kasuta käsku Dur > New duration.
17.2.3 Resünteesitud heli salvestamine
Manipulation-objekt ei ole tavaline helifail, nii et kui see salvestada käsuga Save to text file... või Save to binary file..., saab seda Praatis uuesti avada, aga teised programmid seda ei loe.
Et saada Manipulation-objektist jälle helifail, tuleb see sünteesida ehk tagasi helifailiks muundada. Manipuleeritud heli sünteesimiseks on mitu varianti, millest kõige parema (loomulikuma) tulemuse annab meetod overlap-add. Kui oled töö Manipulation-objektiga lõpetanud, sünteesi selle põhjal helifail, kasutades objektiakna käsku Get resynthesis (overlap-add) (või toimetamisaknas menüüst File > Publish resynthesis). Nüüd tekib objektiaknasse uus Sound-objekt.72 Uue Sound-objekti võid salvestada wav-failina (menüüst Save käsuga Save to WAV file...).
17.3 Allikas-filter süntees Praatis
Allikas-filter ehk formantsüntees ehk Klatti süntees on kõnetrakti akustiline mudel, mille idee on matkida loomuliku kõne moodustamist. See meetod ei ole tänapäeval kasutusel tekst-kõne süntesaatori rakendustes, aga seda kasutatakse kõne uurimiseks, tihti stiimulite sünteesimiseks tajutestide tarvis. Sünteesil on kaks komponenti: allikas ja filter.
Allikas on nagu kõri, st genereeritakse justkui häälekurdudest tulev puhas heli, nii nagu see on enne, kui kõnetrakt mingeid komponente sellest võimendab või summutab. See allikasignaal lastakse läbi filtri, mis on justkui nagu kõnetrakt, mis mingeid etteantud sagedusvahemikke võimendab või summutab.
Praatis on allikas-filtri sünteesi jaoks kaks võimalust: üks võimalus on genereerida allikas ja filter eraldi,73 teine võimalus on kasutada nn Klatti süntesaatorit.74 Mõlemal viisil on võimalik kas sünteesida kõik algusest lõpuni või resünteesida loomulikku kõnet. Siin näites kasutame esimest viisi, et sünteesida vokaale, mida kasutame stiimulitena tajukatses peatükis 18.1. Järgnevalt on esitatud käsud halli taustaga tekstikastides Praati skripti vormis (vt Praati skriptikeele kohta ptk 19) ja eelnevas tekstis on osutatud sellele, kust menüüst käsu leiab.75
Kõigepeal genereerime allika ehk häälekurdudest tuleva signaali. Sõna kestus võiks olla umbes 300 ms ehk 0,3 sekundit. Otsi menüüst New > Tiers > Create PitchTier....
Nüüd tuleks märkida mingid punktid põhitooni sagedusega. Kui tahame, et stiimul oleks monotoonse põhitooniga, siis piisab sellest, kui lisada ainult üks põhitoonipunkt ükskõik kas algusesse (aeg 0 s), lõppu (0,3 s) või kuhugi vahepeale. Aga et anda natuke loomulikum kõla häälele, genereerime siia väikese põhitooniliikumise.
Hääliku alguses võiks põhitoon olla 150 Hz, esimeses silbis kergelt langeda 140 Hz-le ning siis sõna lõpuks langeda 100 Hz peale. Kui avada PitchTier’i toimetamisaken, siis leiab menüüst PitchTier käsu Add point at... ja objektiaknas leiab menüüst Modifiy käsu Add point.... Lisame siis kolm põhitoonipunkti:
Võid seda nüüd kuulata, selleks on dünaamilises menüüs kaks käsku: Play pulses mängib pininana, Hum mängib üminana.
Lähme edasi ja genereerime põhitooni kõverast objekti, mis matkib kõripulsse. Objektiaknas PitchTier-objekti dünaamilisest menüüst Synthesize leiad käsu:
Nüüd ongi meil allikas peagu valmis, teeme veel PointProcess-objektist Sound-objekti. Dünaamilisest menüüst Synthesize leiad käsu:
Järgmiseks teeme filtri. Filter peab olema sama pikk kui allikas ehk samuti 300 ms. Kõigepealt teeme ta vaikimisi väärtustega, st formantväärtused, mis võiksid sobida švaavokaalile, kui keel on suus jõudeasendis: F1 = 550 Hz ja iga järgmine formant 1100 Hz võrra kõrgem. Menüüst New > Tiers
Nüüd anname F1 ja F2 soovitud vokaali väärtused. Teeme esimeseks /i/, seega F1 võiks olla näiteks 200 Hz ja F2 2700 Hz.
Kõigepealt eemaldame kogu sõnast F1 ja F2 punktid. Kui FormantGrid’i toimetamisaknas seda teha, tuleks valida esimene formant Formant > Select first ja seejärel Point > Remove point(s) ning seejärel sama teise formandiga. Objektiakna menüüst Modify:
Nüüd anname vokaalile soovitud väärtused F1 = 200 Hz ja F2 2700 Hz:
Nii ongi filter valmis! Nüüd paneme allika ja filtri kokku: vali mõlemad objektid: Sound allikas + FormantGrid filter > Filter. Tulemuseks on Sound-objekt (kuula), mille saad salvestada helifailina käsuga Save as WAV file....
Nüüd saame sünteesida teise vokaali, selleks tõstame F1 väärtust 100 Hz ja langetame F2 väärtust samuti 100 Hz. Valime uuesti objekti FormantGrid, eemaldame eelmiste väärtustega F1 ja F2 punktid ning lisame uute väärtustega punktid:
Remove formant points between: 1, 0, 0.3
Remove formant points between: 2, 0, 0.3
Add formant point: 1, 0.15, 300
Add formant point: 2, 0.15, 2600
plusObject: "Sound allikas"
FilterKorda seda protseduuri veel viis korda, kuni F1 väärtus on 800 Hz ja F2 väärtus on 2000 Hz. Nüüd võiks olla seitsmest stiimulist koosnev vokaaliseeria, mis võiks katta eesvokaale /i/, /e/ ja /æ/. Salvesta Sound-objektid WAV-failidena, et kasutada neid stiimulitena tajukatses (vt ptk 18.1).
17.4 Artikulatoorne süntees Praatis
Artikulatoorse sünteesi idee on lihtsustatult kirjeldades selles, et inimese hääldusaparaati võib käsitleda torustikuna, mille kuju lihased muudavad. Seda torustikku ja lihaspingeid on võimalik modelleerida. Artikulatoorse sünteesi eesmärk tänapäeval ei ole teha võimalikult loomulikku tekst-kõne-süntesaatorit. Ülesande lahendamisele (võimalikult loomulik kõne) suunatud rakenduste puhul ei ole artikulatoorne süntees kuigi efektiivseks osutunud. Artikulatoorse sünteesi eesmärk on paremini aru saada, kuidas inimese hääldusaparaat töötab, ja hääldusprotsesse modelleerida. Praati artikulatoorse sünteesi mudel põhineb Paul Boersma doktoritööl (Boersma 1998).
Täpsemalt on kõnetrakti mudel selline: osa torusid on otsast lahti (huuled, ninasõõrmed), osa kinni (kopsud) ja osa ühendab ühtesid teistega (neel-suu-nina). Torustiku kuju on ajas muutuv. Teatud tingimustel tekitab kopsudest tulev õhk kõris heli (kas paneb häälekurrud vibreerima või hõõrdub neid läbides).
Praatis jaguneb artikulatoorne süntees kahte etappi:
- lihaste tegevuse põhjal kujundatakse kõnetrakti kuju,
- kõnetrakti kuju põhjal sünteesitakse heli.
Artikulatsioonimudeli põhilised osad on need:
- kõrieelne süsteem. Sajad miljonid alveoolid suubuvad kopsutorudesse, mis omakorda suubuvad hingetorru,
- kõri,
- neeluõõs ja suuõõs,
- ninaõõs.
Neelu- ja suuõõnt kujutatakse Praatis 27 torusektsioonina, mille kuju saab muuta, andes neid sektsioone kontrollivatele lihastele pingeid.
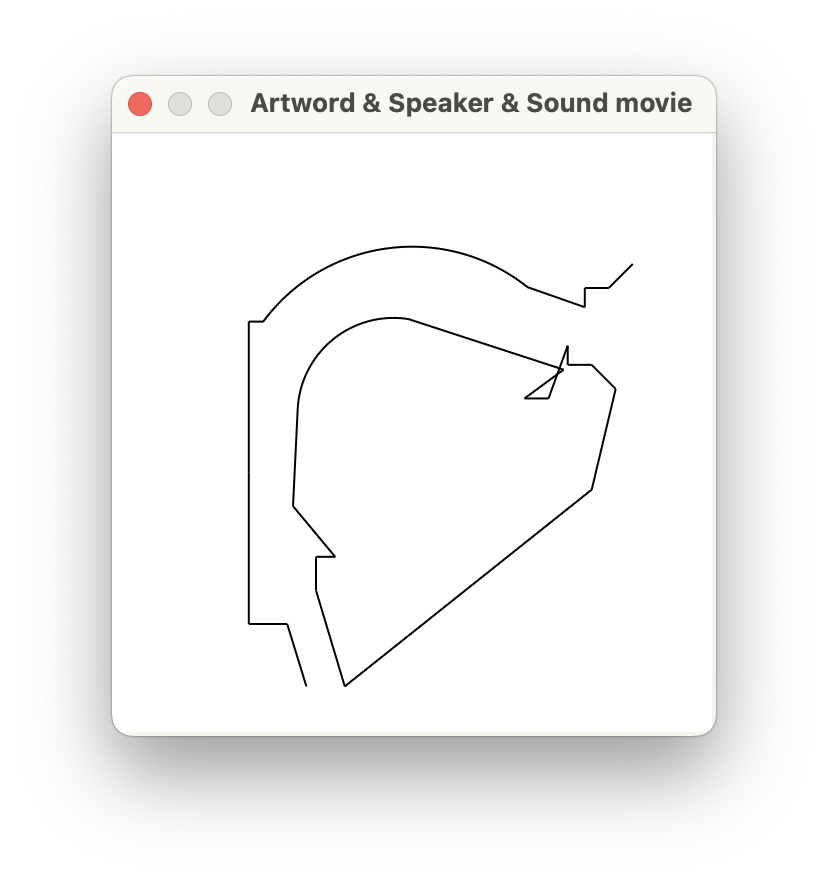
Joonis 17.4. Artikulatoorse sünteesi animatsioon.
Praatis kasutatav artikulatsioonimudel arvestab ka toru osade kuju muutumisest tuleneva pumpamise ja imemise efektiga: kui üks toru osa muutub väiksemaks, siis surub ta õhku eri suundades, kui muutub suuremaks, siis vaakumi tõttu imeb eri suundadest. Seega õhu liikumist ei määra ainult kopsude tegevus. Kui õhk liigub kitsamast torust laiemasse, põhjustab see õhu kaootilist liikumist.
Artikulatoorne süntees on üsna keerukas ja nõuab oluliselt põhjalikumaid teadmisi füsioloogiast kui siin õpikus käsitletud. Sellegipoolest proovime ka artikulatoorse sünteesiga ühe katsetuse läbi teha ja sünteesime sõna tere.
Kõigepealt on vaja kõnelejat. Vali menüüst New > Articulatory synthesis > Create Speaker.... Paneme kõnelejale nimeks näiteks Maret, aga muidu jätame vaikimisi väärtused:
Järgmiseks on vaja luua artikulatsioonimuster ehk artikulaatorite liikumine, et hääldada sõna tere. Selleks on vaja tekitada objekt Artword. Vali menüüst New > Articulatory synthesis > Create Artword.... Sõna kestus võiks olla 500 ms ehk 0,5 sekundit.
Kui objekt Artword on objektiloendis valitud ja vajutad nüüd Edit, avaneb selline aken nagu joonisel 17.5. Aknas vasakul on nimekiri sihtmärkidest, st mis ajahetkel millisele lihastele mis pinge on seatud. Aknas paremal on nimekiri lihastest (või hääldusaparaadi osadest, kõik ei ole nimetatud lihastena) ja kui sealt mõni valida, saab akna keskel määrata aja, millal see lihas mingi väärtuse saab. Pingete väärtused muutuvad vahemikus –1 kuni 1, 0 on jõudeasend.
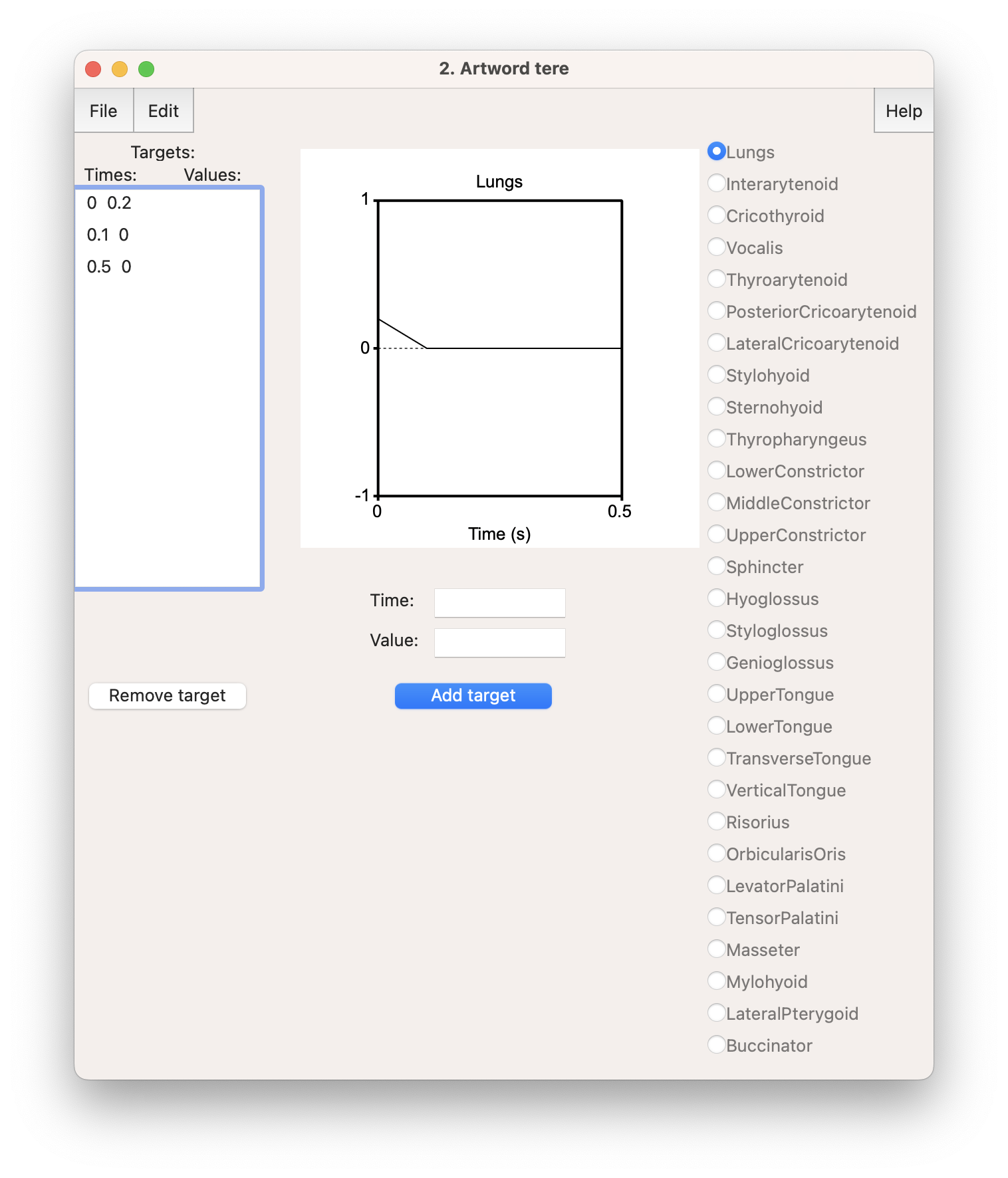
Joonis 17.5. Artikulatoorse sünteesi toimetamisaken.
Kõigepealt paneme kopsudest õhu liikuma. Seda saab nii, et valid aknas paremalt Lungs ja keskel Time ja Value lahtrites määrad mingile ajahetkele väärtuse ning vajutad nuppu Add target. Alternatiiv on objektiaknas käsuga Set target..., nagu allpool kõik järgnevad käsud. Anname kopsudele kaks väärtust: ajal 0 väärtus 0.2 ja ajal 0.1 väärtus 0:
Liigutame pilkkõhresid, et panna häälekurrud võnkuma:
Liigutame pehmet suulage, et sulgeda käik ninaõõnde:
Styloglossus on lihas, mis hoiab, et keel kurku/suust välja ei vajuks:
Tekitame sulu: LowerTongue liigutab keeletippu, mälurlihas (Masseter) lõualuud:
Set target: 0, -1, "LowerTongue"
Set target: 0.04, -1, "LowerTongue"
Set target: 0, 0.7, "Masseter"
Set target: 0.1, -0.05, "Masseter"Nüüd vallandame sulu:
Set target: 0.1, -0.2, "LowerTongue"
Set target: 0.25, -0.2, "LowerTongue"
Set target: 0.5, -0.1, "Masseter"Tekitame /r/-i jaoks keeletipu vibreerimise:
Set target: 0.26, -1, "LowerTongue"
Set target: 0.28, 0, "LowerTongue"
Set target: 0.3, -1, "LowerTongue"
Set target: 0.32, -0.1, "LowerTongue"Nüüd ongi valmis ja tuleb sõna ja kõneleja omavahel kokku viia. Vali objektiaknas Speaker Maret ja Artword tere ja käsuga To Sound... saad sünteesida heli:
selectObject: "Speaker Maret"
plusObject: "Artword tere"
To Sound: 22050, 25, 0, 0, 0, 0, 0, 0, 0, 0, 0Tulemus kõlab nii. Vokaalid on võrdlemisi redutseeritud, kuid sõna on äratuntav. Vokaalide parema kvaliteedi saavutamiseks tuleks keele kuju täpsemini vormida.
Peale selle saad vaadata kõnetrakti liikumise animatsiooni: vali kõik kolm objekti: Speaker Maret + Artword tere + Sound tere_Maret > Movie (vt kuvatõmmist joonisel 17.4).
Kirjandus
Tegu on eSpeak süntesaatoriga, mis on küllalti vana difoon/formantsüntesaatori mudel, vt https://github.com/espeak-ng/espeak-ng/.↩︎
Ingl semitone – see on muusikaline mõiste pooltoon, mis vastab 21/12-kordsele (ehk umbes 6%) sagedusmuutusele.↩︎
See on oluline, kui Sound on lõigatud pikemast failist nii, et algusaeg ei ole null, aga kui Sound algab nullist, piisab ka käsust
Get total duration.↩︎Tõenäoliselt on uus fail sama nimega, mis on Manipulation-objektil ja algsel Sound-objektil, millest see tuletatud on, nii et ole ettevaatlik selle salvestamisel, et oma algset faili üle ei kirjuta. Kindlam on see enne ümber nimetada käsuga
Rename.↩︎Vt Praati manuaalist märksõna Source-filter synthesis http://www.fon.hum.uva.nl/praat/manual/Source-filter_synthesis.html.↩︎
Vt manuaalist http://www.fon.hum.uva.nl/praat/manual/KlattGrid.html.↩︎
Kui menüüs on käsu lõpus kolm punkti, siis see tähendab, et selle käsu peale avaneb dialoogiaken, kus küsitakse täiendavaid väärtuseid. Käsureal on kolme punkti asemel koolon ning kooloni järel komadega eraldatud argumendid selles järjekorras, nagu nad graafilise kasutajaliidese dialoogiaknas vastavates lahtrites peaks olema. Skriptis peavad sõnalised väärtused olema jutumärkides, dialoogiakna vastavasse lahtrisse tuleks kirjutada aga ilma jutumärkideta. Siin esitatud protseduur on ka tervikliku skriptina repositooriumis https://github.com/partellippus/akustilised-meetodid-foneetikas/tree/main/syntees.↩︎