Peatükk 21 Foneetiliste andmete kogumine ja töötlemine R-is
Siin peatükis teeme lühikese ülevaate sellest, kuidas Praatiga kogutud andmeid edasi töödelda R-is või hoopis R-is ilma Praatita läbi ajada. Ülevaade on põgus ja ei kata terviklikku töövoogu, aga ehk leidub kasulikke näpunäiteid edasisteks otsinguteks. Kuna käesolev raamat on koostatud ja küljendatud RStudios bookdown paketiga (Xie 2016), siis peagu kõike siin jutuks tulevat on tegelikult varasemates peatükkides rakendatud: Praati skriptide jooksutamiseks R-i koodis on kasutatud paketti speakr (Coretta 2024). Joonised, mis ei ole tehtud Praatis, on tehtud kasutades pakette praatpicture (Puggaard-Rode 2024) või phonTools (Barreda 2023), rPraat (Bořil & Skarnitzl 2016) ja ggplot2 (Wickham et al. 2024).
21.1 Joonised R-is praatpicture paketiga
Praati stiilis helilaine, spektrogrammi, formantide ja põhitooniga jooniseid saab mugavasti R-is teha paketiga praatpicture (Puggaard-Rode 2024). See on mugav alternatiiv Praatile, kus selleks, et joonise tekste kohendada (nt telgede pealkirjad eestikeelseks) tuleb palju erinevaid samme teha (või skript kirjutada).
Joonisel 21.1 on kujutatud fail w320.wav käsu praatpicture() vaikeväärtustega. Kui helifailiga samas kaustas on sama nimega TextGrid fail, siis seda pole vaja eraldi nimetada.
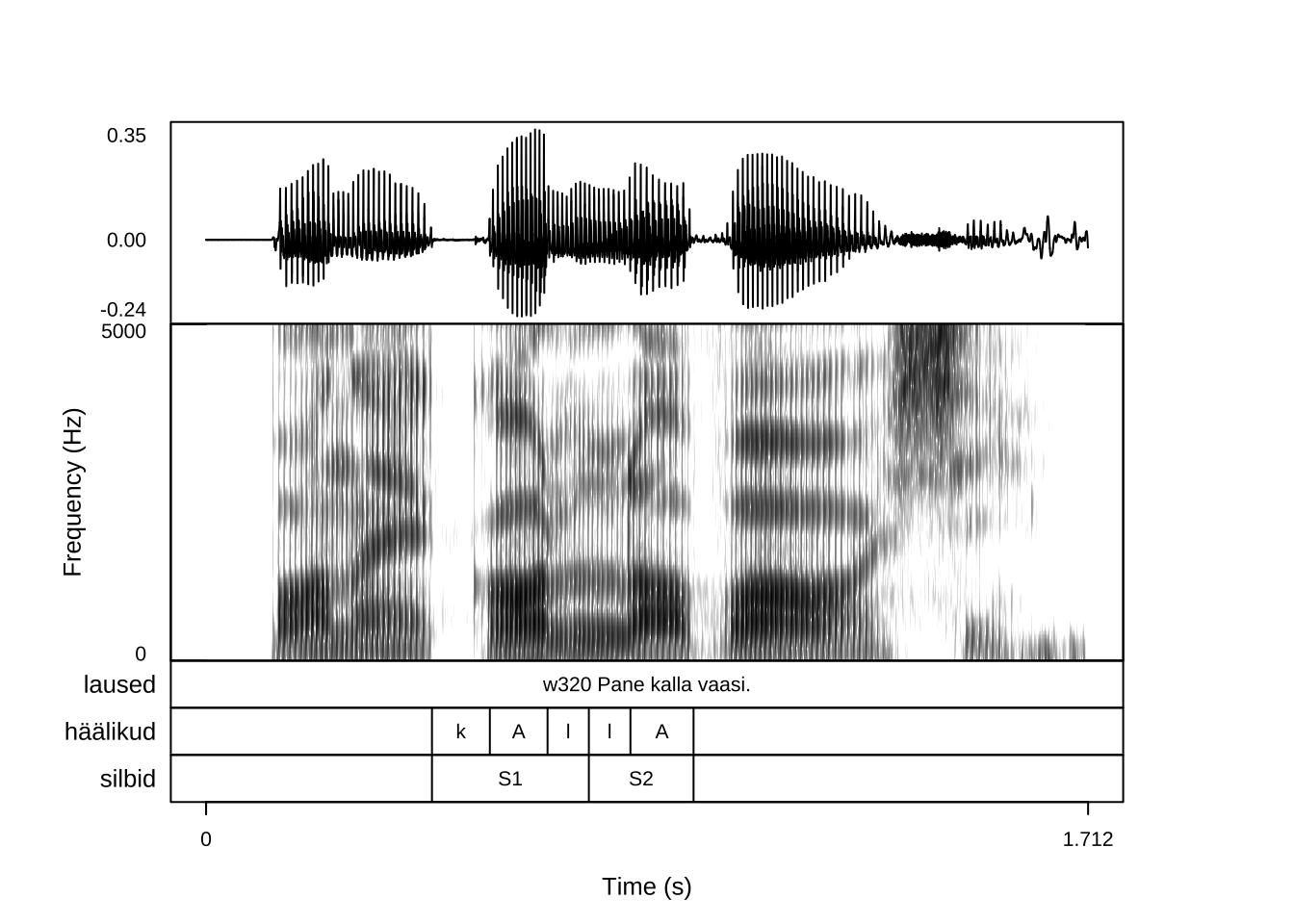
Joonis 21.1: Näide praatpicture joonisest käsu vaikeväärtustega.
Kui tahta sisse suumida osale failis olevast salvestisest, saab ajaakent täpsustada argumentidega start ja end, nagu on joonisel 21.2. Argumendiga frames määrame, et tahame joonisel kijutada helilainet, põhitoonikontuuri, spektrogrammi ja TextGridi ning argumendiga proportion määrame vastavalt nende vertikaalse proportsiooni (protsentides). Argumendiga tg_tiers saame määrata, milliseid TextGridi kihte joonistatakse (juhul kui failis on neid rohkem ja kõiki ei soovi joonisele) ning argument tg_focusTier määrab selle kiri, mille piire märgitakse vertikaalsete punktiirjoontega üle kogu joonise.
library(praatpicture)
praatpicture(sound = "Failid/valted/w320.wav",
start = 0.438,
end = 0.946,
frames = c("sound", "pitch", "spectrogram", "TextGrid"),
proportion = c(20, 20, 40, 20),
pitch_axisLabel = "Sagedus (Hz)",
spec_axisLabel = "Sagedus (Hz)",
time_axisLabel = "Aeg (s)",
tg_tiers = c("häälikud", "silbid"),
tg_focusTier = "häälikud",
pitch_freqRange = c(50,200),
formant_plotOnSpec = T,
formant_color = c("red","pink"))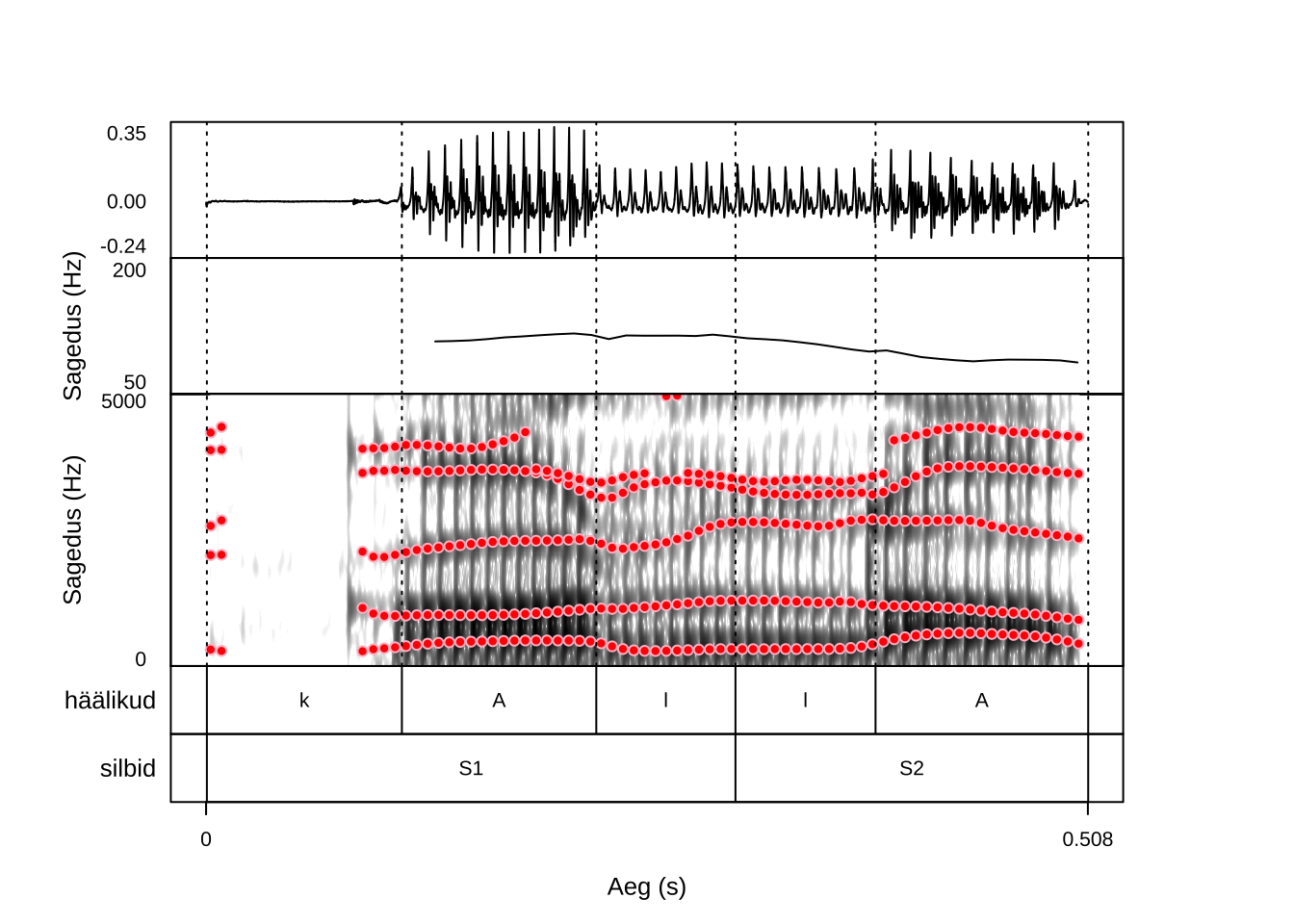
Joonis 21.2: Täiendatud praatpicture joonis helilaine, põhitoonikontuuri, spektrogrammi, formantide ja TextGrid annotatsiooniga.
Paketil praatpicture on ka väga kasutajasõbralik manuaal, mistõttu pikemalt selle kasutamist siin õpikus ei käsitle.
21.2 Praati objektide lugemine R-is paketiga rPraat
Pakett rPraat (Bořil & Skarnitzl 2016) loeb R-is Praati objekte ja pakub mingil määral neile Praati menüüdes saada olevaid käske. Eeskätt on see kasulik TextGrid failide lugemiseks, mis selle paketiga R-i lugedes on list-tüüpi objekt. Iga märgenduskiht on üks listi element, mille sees on vektoritena selle märgenduskihi segmentide algusajad, lõpuajad ja märgendid. Seda on väga lihtne näiteks tabeliks teisendada:
library(rPraat)
tg <- tg.read("Failid/valted/w320.TextGrid")
foneemid <- data.frame(tg$häälikud[c("t1","t2","label")])
foneemid## t1 t2 label
## 1 0.0000000 0.4384610
## 2 0.4384610 0.5508040 k
## 3 0.5508040 0.6627962 A
## 4 0.6627962 0.7429755 l
## 5 0.7429755 0.8236667 l
## 6 0.8236667 0.9461806 A
## 7 0.9461806 1.7116243Lisaks leiab paketist käsud Praati stiilis märgenduspunktide aja ja märgendite pärimiseks ja muutmiseks. rPraat paketiga saab ka teisi Praati objekte lugeda (nt Pitch, Formant), aga objektid peavad olema Praatis loodud ja salvestatud. Rohkem näiteid kasutuse kohta leiab paketi dokumentatsioonist.
21.3 Akustilised analüüsid paketiga phonTools
Kui on soovi päris ilma Praatita akustilisi analüüse R-is teha, siis seda saab paketi phonTools (Barreda 2023) abil.
Et põhitooni või formante analüüsida, on vaja lugeda sisse helifail. Seda saab teha phonTools paketi käsuga loadsound() või ka rPraat käsuga snd.read(). Mõlemal juhul loetakse helifail list tüüpi objektiks, mis sisaldab vektorit heli valjuse väärtustega sämplite kaupa.
Joonisel 21.3 on kujutatud 10 000 esimest sämplit faili w320.wav algusest. Faili sämplimissagedus on kirjas objekti elemendis fs: see on 48000, mis tähendab, et joonisel oleva lõigu kestus on 0.2083333 sekundit.
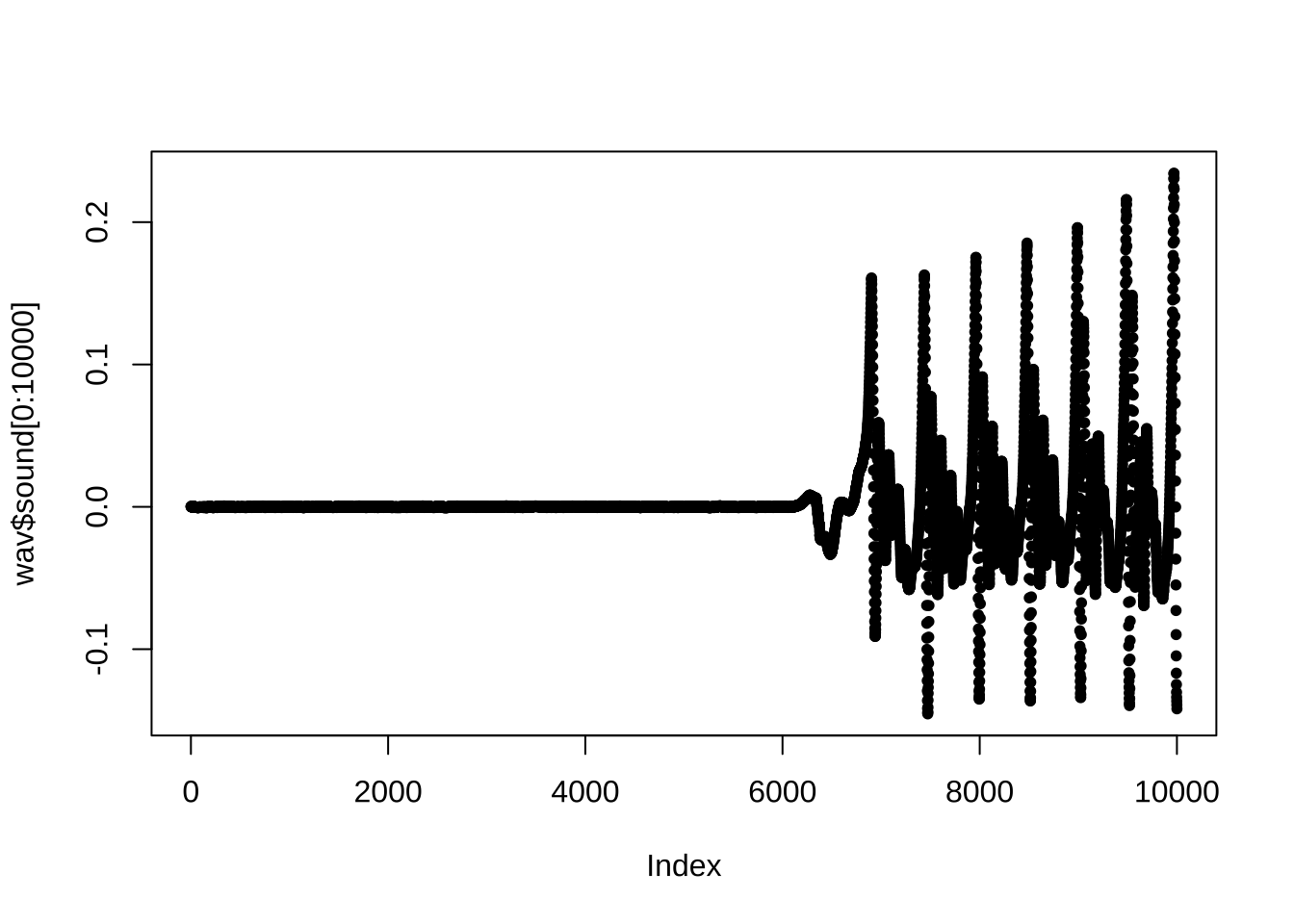
Joonis 21.3: 10 000 sämplit faili w320.wav algusest.
Põhitoonianalüüsiks on käsk pitchtrack(), mis vaikimisi ka joonistab põhitoonikontuuri (joonis 21.4). Käsuga tekitatud põhitooniandmete objekt on tabel, kus on kolm tulpa: aeg (millisekundites), põhitooni sagedus (hertsides) ning vastava ajaakna põhitooni väärtuseks loetud autokorrelatsiooni väärtus.35
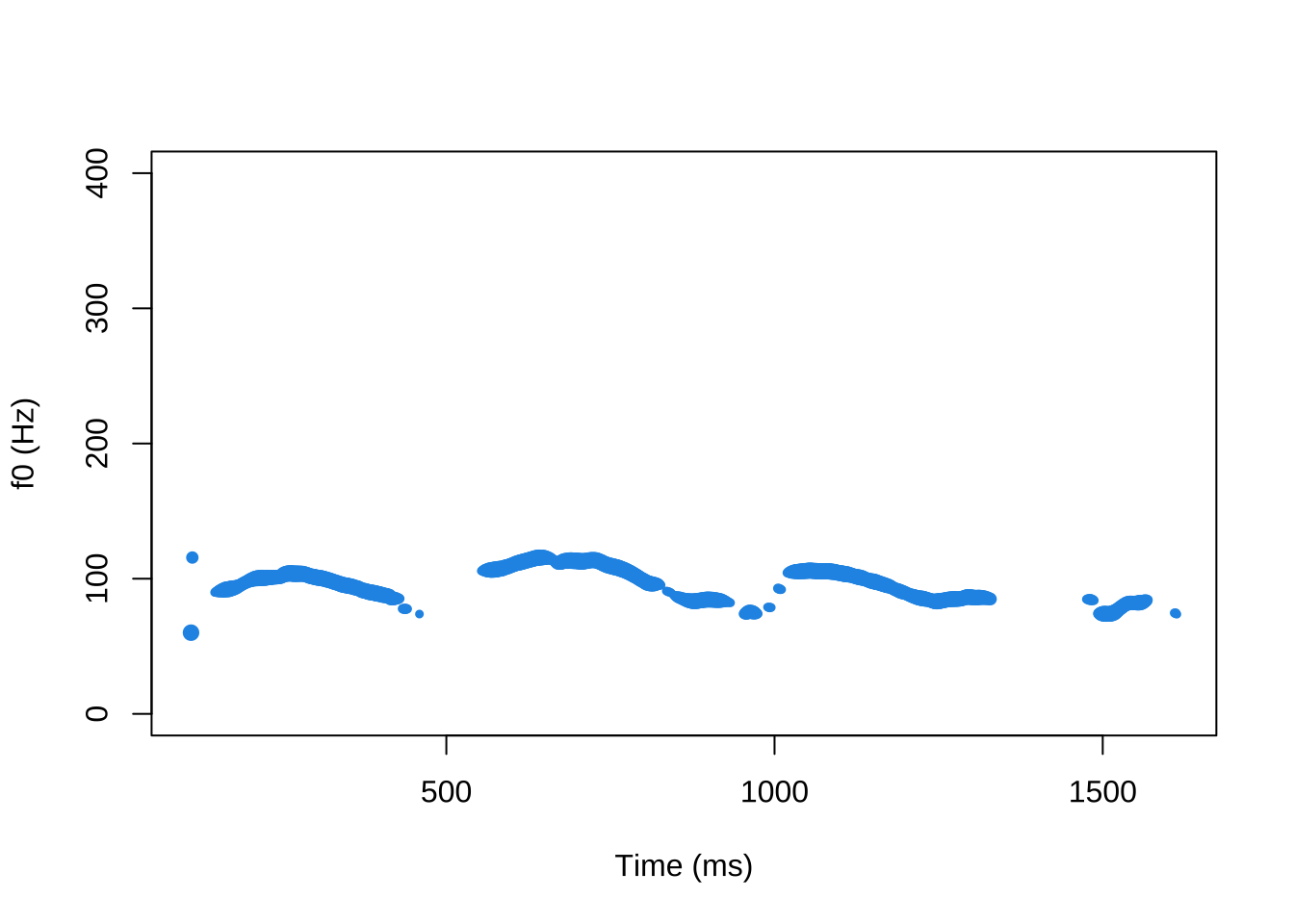
Joonis 21.4: Põhitoonikontuur phonTools paketiga.
## time f0 acf
## 1 111 60.08 0.9972
## 2 113 115.66 0.7472
## 3 147 89.89 0.5264
## 4 149 90.23 0.5967
## 5 151 90.40 0.6620
## 6 153 90.74 0.7185Kui tahame mõõtmisvigade vältimiseks põhitoonianalüüsi piire täpsustada nii nagu peatükis 12.2.4, siis saame seda kahe sammuga: esimese sammuga seame argumendi f0range suure vahemikuga, siis leiame kvartiilide väärtused ning teeme uue põhitoonianalüüsi kitsamate väärtustega. Argumendiga show ütleme, et ei taha joonist.
f0_lai <- pitchtrack(sound = wav, f0range = c(50, 800), show = F)
kvart <- quantile(f0_lai$f0, probs = c(0.25,0.75))
f0_kitsas <- pitchtrack(wav,
f0range = c(kvart[1]*0.75, kvart[2]*2),
show = F)Kui nüüd edasi tahame leida näiteks leida sõna kalla esimese silbi keskmist kestust (mis on tähistatud kui S1 joonisel 21.1), siis häälikute ja silpide piiride ajad on olemas ptk 21.2 loetud TextGrid objektis ja need tuleb põhitooniobjektiga kokku panna. Peab ainult arvestama sellega, et tg objektis on ajad sekundites, pitchtrack objektis millisekundites.
s1algus = tg$silbid$t1[tg$silbid$label == "S1"]
s1lopp = tg$silbid$t2[tg$silbid$label == "S1"]
f0_kitsas %>%
filter(time >= s1algus*1000 & time <= s1lopp*1000) %>%
summarise(f0keskmine = mean(f0),
f0tipp = max(f0)) %>%
mutate(kestus = (s1lopp-s1algus)*1000)## f0keskmine f0tipp kestus
## 1 110.7156 115.66 304.5144Formantide leidmiseks on käsk formanttrack(). Selle sisendiks on jällegi heliobjekt (argumendina sound piisab vektorist, kus on sämplite kaupa heli valjuse väärtused ja fs argumendiga peaks täpsustama sämplimissageduse). Kui me ei lisa argumenti show=F, joonistab see käsk spektrogrammi ja selle peale erinevate värvidega formantväärtused, nagu näha jooniselt 21.5.
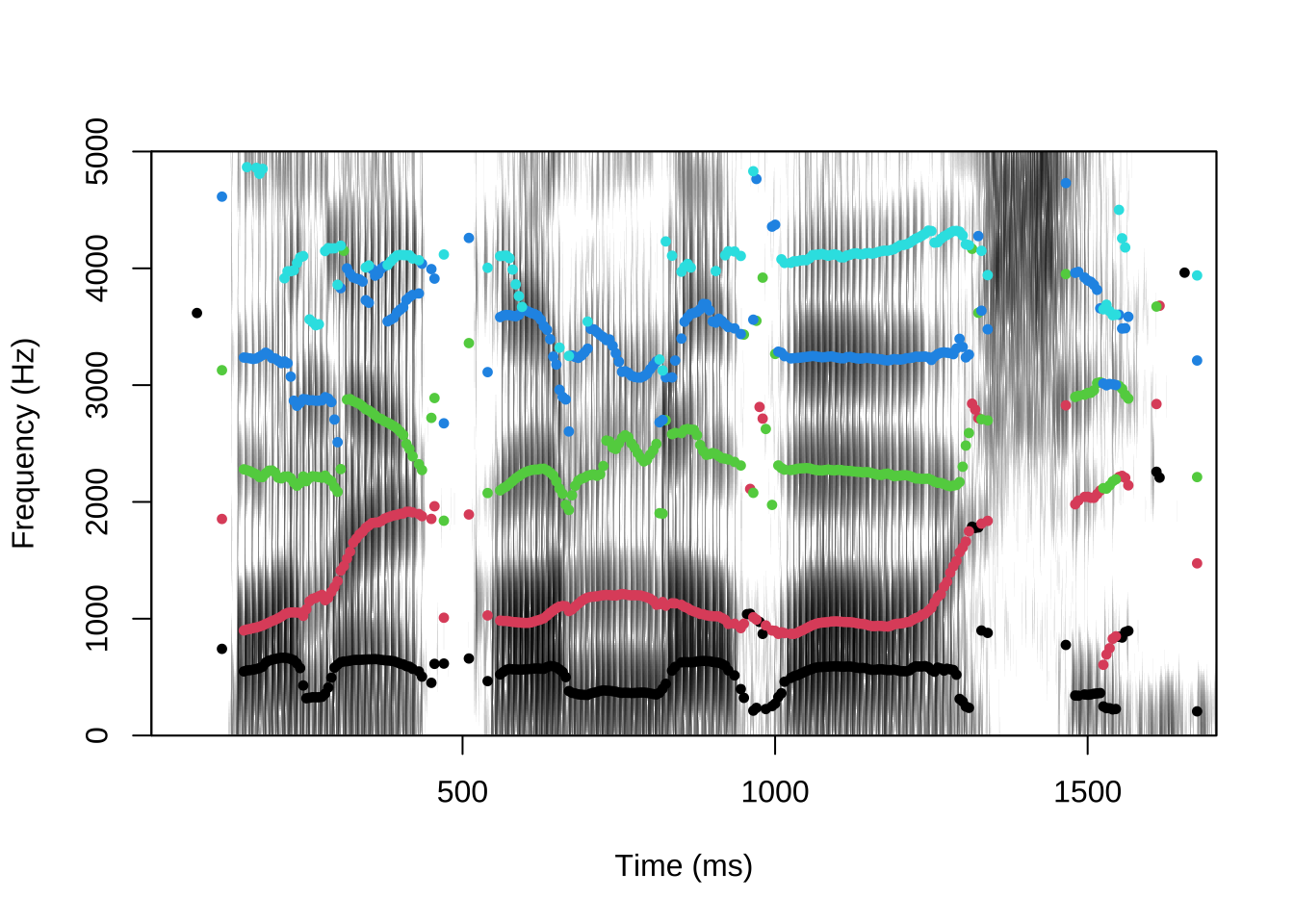
Joonis 21.5: Spektrogrammi ja formantide joonis phonTools paketiga.
Tulemuseks on tabel analüüsiakna ajapunktide (millisekundites) ning formantide väärtustega (hertsides). Kui tahame formantanalüüsi seadeid täpsustada sarnaselt sellele nagu Praatis peatükis 8.2.3 ja 9.3.3, siis argument formants täpsustab, mitut formanti otsitakse (vaikimisi 5) cutoff määrab formantanalüüsi lae (vaikimisi 5000) ning minformant määrab minimaalse väärtuse, mida võib formantväärtuseks pidada (vaikimisi 200; et mitte põhitooni F1-ks pidada).
Kui tahame näiteks sõna kalla vokaalide esimese ja teise formandi väärtuseid mõõta keskmise väärtusena vokaali keskosast, siis seda saame jällegi TextGridil olevat märgendust appi võttes. Jällegi peab meeles pidama, et objektis tg on ajaväärtused sekundites ja formandid tabelis on need millisekundites.
data.frame(tg$häälikud[c("t1","t2","label")]) %>%
filter(label == "A") %>%
group_by(t1, t2) %>%
mutate(t1 = t1*1000, t2 = t2*1000, # millisekunditeks
kestus = t2-t1,
f1 = mean(formandid$f1[formandid$time > t1+0.25*kestus &
formandid$time < t2-0.25*kestus]),
f2 = mean(formandid$f2[formandid$time > t1+0.25*kestus &
formandid$time < t2-0.25*kestus])) %>%
ungroup()## # A tibble: 2 × 6
## t1 t2 label kestus f1 f2
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl>
## 1 551. 663. A 112. 569. 976.
## 2 824. 946. A 123. 630. 1045.Kui on tarvis hertsides mõõdetud väärtuseid teisendada mõnele muule skaalale, saab kasutada paketti hqmisc (Quene 2022). Põhitooni kõrgust on tavalisem teisendada pooltooniskaalale (käsk f2st()) ning formantide väärtuseid bargi skaalale (käsk f2bark()).
Nagu peatükis 12.2.1 kirjeldatud, on pooltooniskaala intervallskaala ja teisendades võetakse nullpunktiks mingi kokkuleppeline väärtus, näiteks 50 Hz või 440 Hz, aga seda alusväärtust võib kasutada ka normaliseerimiseks. Kui tahame normaliseerida kõnelejatevahelist varieerumist, võib võtta aluseks kõneleja keskmise väärtuse või kui tahame normaliseerida lausungi intonatsiooni mõju, võime nullpunktiks võtta vaadeldava kõneüksuse alguspunkti (või keskmise väärtuse). Siin näites teisename põhitooni väärtused lausungi keskmise36 suhtes.
library(hqmisc)
f0_kitsas %>%
mutate(f0_pt = f2st(f0, median(f0))) %>%
ggplot()+
geom_point(aes(x = time, y = f0_pt))+
geom_hline(yintercept = 0, linetype="dashed")+
labs(y = "Põhitoon (pooltoonid)", x = "Aeg (ms)")+
theme_bw()+
NULL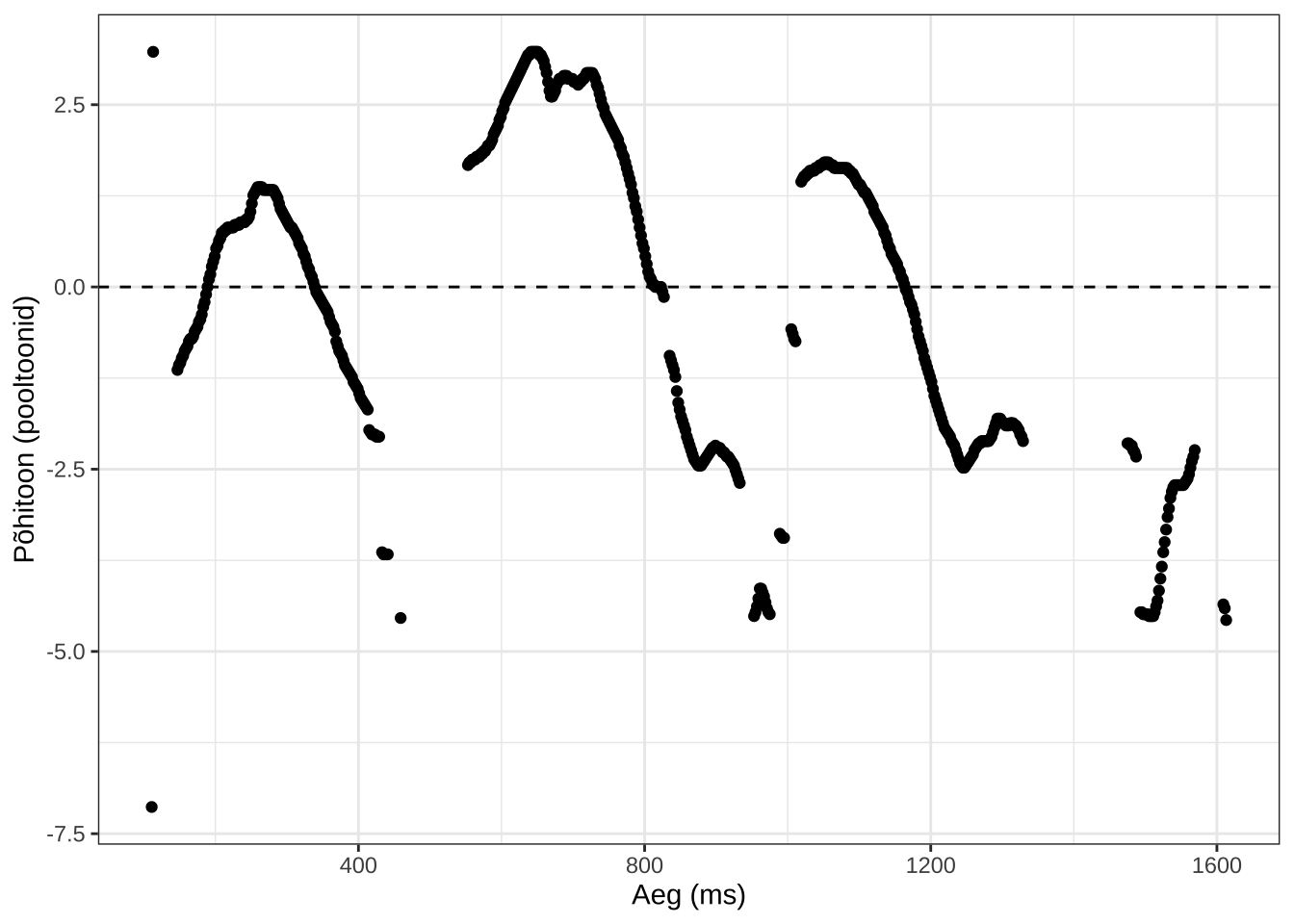
Joonis 21.6: Põhitoonikontuur teisendatud pooltooniskaalale lausungi keskmise suhtes.
Bargi skaala on suhteskaala ja selle teisendusalus ei ole kokkuleppeline ja seega teisendusel on vaid üks sisendväärtus. Kuna teisendus muudab skaala lineaarsemaks, siis keskmise väärtuse arvutamisel on tulemus veidi erinev sõltuvalt sellest, kas keskmine võtta enne või pärast teisendust. Siin näites kõigepealt teisendame ja siis keskmistame ning kasutame hqmisc paketist ka käsku is.inrange() et leida formandipunktid, mis jäävad vokaali märgendi vahemikku.
data.frame(tg$häälikud[c("t1","t2","label")]) %>%
filter(label == "A") %>%
group_by(t1, t2) %>%
mutate(t1 = t1*1000, t2 = t2*1000, # teisendame millisekunditeks
kestus = t2-t1,
F1Hz = mean(formandid$f1[is.inrange(formandid$time, c(t1+0.25*kestus, t2-0.25*kestus))]),
F1bark = mean(f2bark(formandid$f1[is.inrange(formandid$time, c(t1+0.25*kestus, t2-0.25*kestus))])),
F2Hz = mean(formandid$f2[is.inrange(formandid$time, c(t1+0.25*kestus, t2-0.25*kestus))]),
F2bark = mean(f2bark(formandid$f2[is.inrange(formandid$time, c(t1+0.25*kestus, t2-0.25*kestus))])))%>%
ungroup()## # A tibble: 2 × 8
## t1 t2 label kestus F1Hz F1bark F2Hz F2bark
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 551. 663. A 112. 569. 5.50 976. 8.38
## 2 824. 946. A 123. 630. 5.99 1045. 8.7921.4 Praati skriptide jooksutamine R-is paketiga speakr
Kui soovime siiski mingeid funktsioone oma töövoos kasutada Praatiga, mida eelpool kirjeldatud paketid ei asenda, on võimalik Praati skripte jooksutada R-i käsureal. Pisut ebamugav on siin see, et Praati skript peab olema eraldi failina salvestatud, aga seda on ka võimalik näiteks cat() või writeLines() käsuga R-i skripti sees teha.
Järgnevalt teeme läbi näite, kus teeme R-i kaudu põhitoonianalüüsi Praatis ja loeme analüüsi tulemuse otse R-i ilma vahepeal salvestamata.
Kõigepealt kirjutame valmis Praati skripti. Käsk cat()37 lihtsalt salvestab selle tekstfailina. Selle asemel võiks ka selle skripti Praati skriptieditoris valmis kirjutada ja salvestada.
cat("clearinfo
appendInfoLine: \"aeg\", tab$, \"f0\"
heli = Read from file: \"../valted/w320.wav\"
To Pitch (filtered autocorrelation): 0, 50, 800,
... 15, \"no\", 0.03, 0.09, 0.5, 0.055, 0.35, 0.14
nframe = Get number of frames
for n to nframe
aeg = Get time from frame number: n
f0 = Get value in frame: n, \"Hertz\"
appendInfoLine: aeg, tab$, f0
endfor",
file = "Failid/skriptid/pohitoonianalyys.praat")Nüüd jooksutame seda skripti käsuga praat_run(). Kui skript Praatis kirjutab midagi infoaknasse, siis argumendiga capture = T püüab R selle kinni. Esmalt on see üks tekstistring, aga käsk read_delim() tükeldab tabulatsioonidega eristatud väärtused tulpadeks. Ka peab meeles pidama, et Praat tähistab teadmata väärtused “–undefined–” ja R-is oleks vaja neist saada “NA”-d.
library(speakr)
praat_run("Failid/skriptid/pohitoonianalyys.praat",
capture = T) %>%
read_delim(na = "--undefined--") -> f0_praat
head(f0_praat)## # A tibble: 6 × 2
## aeg f0
## <dbl> <dbl>
## 1 0.0308 NA
## 2 0.0458 NA
## 3 0.0608 NA
## 4 0.0758 NA
## 5 0.0908 NA
## 6 0.106 NAJoonisel 21.7 on kõrvutatud Praati vaikimisi väärtustega filtreeritud autokorrelatsiooni meetodil saadud põhitoonikontuur (punaste täppidega) ja phonTools paketi põhitoonianalüüs (mustade täppidena), siis on näha, et kui kontuurid üldjoontes kattuvad, on Praati kontuuris vähem üksikuid ekstreemseid punkte, mis tõenäoselt on mõõtmisvead.
ggplot()+
geom_point(data = f0, aes(y = f0, x = time/1000))+
geom_point(data = f0_praat,
aes(y = f0, x = aeg), col = "red")+
theme_bw()+
NULL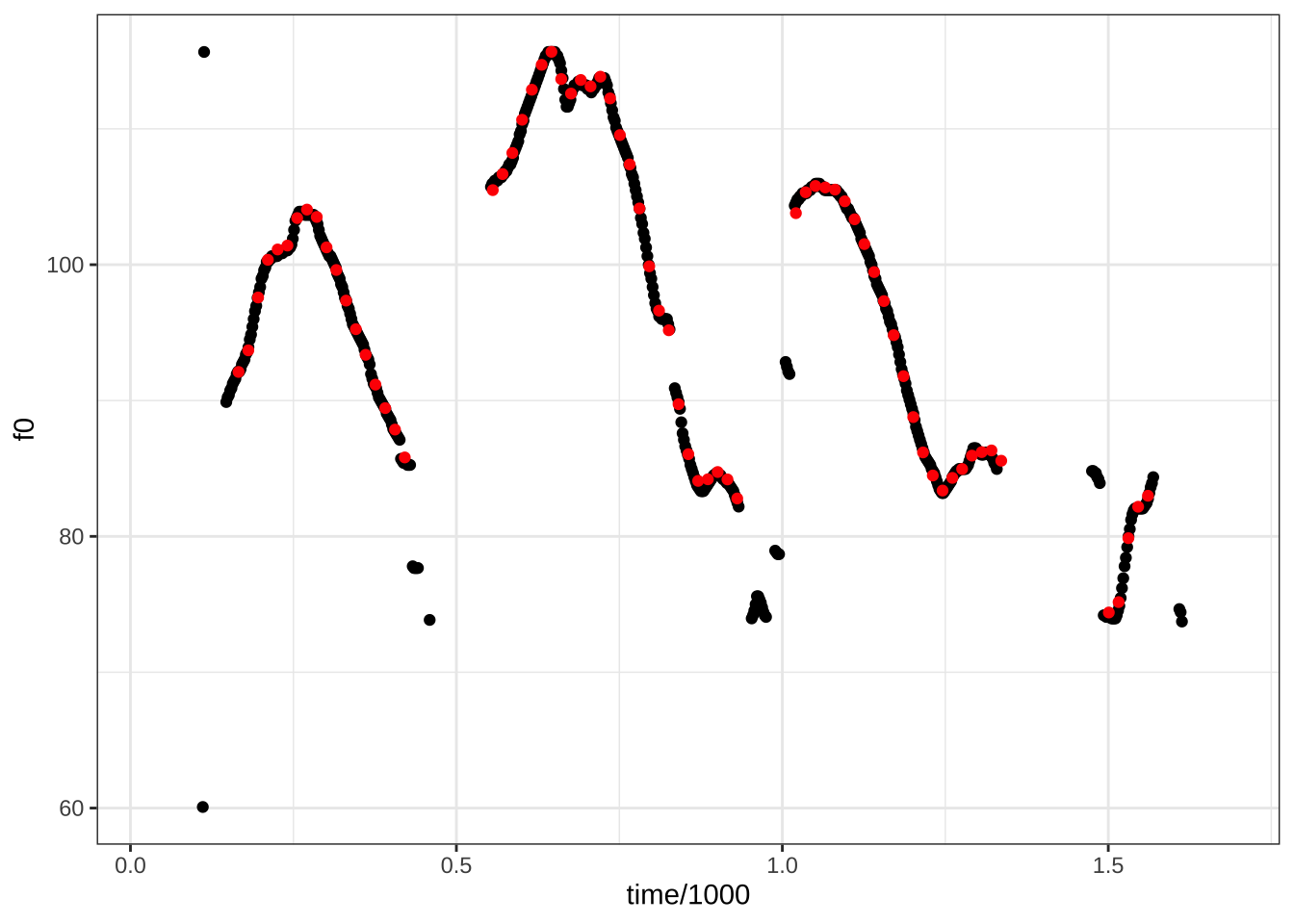
Joonis 21.7: Praati põhitooniananlüüs (punasega) ja phonTools paketi põhitoonianalüüs (mustaga).
21.5 Vokaalidiagrammid R-is ggplot2 paketiga
Nagu peatükis 16 nenditud, on Praati pildiaknas üldiselt head võimalused joonistada Praati analüüse: helilainet, spektrogrammi, põhitooni, formante jms. Kuigi joonistele on võimalik kanda ka punkte, jooni ja muid kujundeid, siis keskmiste väärtuste põhjal punkt-, tulp- või karpdiagrammide joonistamiseks ei ole Praati joonistusfuntsioonid kõige mugavamad ja oluliselt lihtsam on seda teha näiteks R-is.
Tulp- ja karpdiagrammid ei ole kuigi foneetikaspetsiifilised ja neid siin eraldi ei tutvustata, kuid teeme läbi mõned näited vokaalidiagrammidega formantruumis, kus y-teljel kujutatakse esimese ja x-teljel teise formandi väärtusi.
Tavaliselt pööratakse telgede ulatused ümber: skaala kasvab ülevalt alla ja paremalt vasakule, sest siis on see sama pidi nagu kõnetrakti sagitaalne läbilõige (kui suu avaneb vasakule), nii nagu seda kujutatakse nt IPA tabelis.
Aktiveerime paketi tidyverse, mis sisaldab pakette ggplot2 ja dplyr.
Kui peatükis 9 kasutatud näidetes oli üks kõneleja hääldanud igat vokaali ühe korra, siis tavaliselt selleks, et kvantitatiivseid üldistusi vokaalikvaliteedi kohta teha, tuleks salvestada mitmelt kõnelejalt mitu hääldusjuhtumit. Selleks kasutame siin artiklis Lippus et al. (2013) analüüsitud andmeid, mis on avaldatud DataDOI repositooriumis. Loeme andmed otse repositooriumis olevast tabulatsioonidega eraldatud tekstifailist.
dat <- read.delim("https://datadoi.ee/bitstream/handle/33/51/Lippus_etal_JPhon2013_dataset.txt?sequence=4&isAllowed=y")
# kodeerime välte faktorina
dat$Quantity = factor(dat$Quantity)
levels(dat$Quantity) = c("Q1", "Q2", "Q3")
# anname vokaalikategooriale kindla järjekorra
dat$V1.phon1 <- factor(dat$V1.phon1,
levels = c("A", "{", "o", "7", "2", "e", "u", "y", "i"))Vokaalikategooria võiks faktoriseerida, siis on alati joonistel sama järjekord ja sellest tulenevalt samadel vokaalided samad värvid ka siis, kui mõnes andmestiku alamjaotuses ei ole kõik vokaalikategooriad esindatud.38 Kui tahad ise sättida, siis anna argumendiga levels õige järjekord. Järjestame näiteks /a/-st /i/-ni, alt > tagant > ette > üles.
geom_text()joonistab iga punkti tähistades tulba V1.phon1 sümboliga.scale_xy_reversekeerab skaalad kahanevaks.facet_grid()jagab joonise paneelideks. Jagame siin kolmeks reaks vastavalt vältekategooriale ja kaheks tulbaks vastavalt kõneleja soole.stat_ellipse()joonistab iga kategooria punktidele ümber ellipsi usaldusvahemiku piiridega.- Andmestikus on CVCV-struktuuriga (lahtiste silpidega) ja CVCCV-struktuuriga (kinnise esisilbiga) sõnad. CVCCV-struktuuri filtreerime välja, et varieerumist vähendada.
dat %>%
filter(Struct == "cvcv") %>% # ainult lahtiste silpidega sõnad
ggplot(aes(y=V1F1, x = V1F2, shape = V1.phon1, col = V1.phon1))+
geom_text(aes(label = V1.phon1), alpha = 0.6)+
stat_ellipse() +
scale_x_reverse()+
scale_y_reverse()+
labs(x = "F1 (Hz)", y="F2 (Hz)") +
guides(color = "none") +
facet_grid(Quantity ~ Gender)+
theme_bw()+
NULL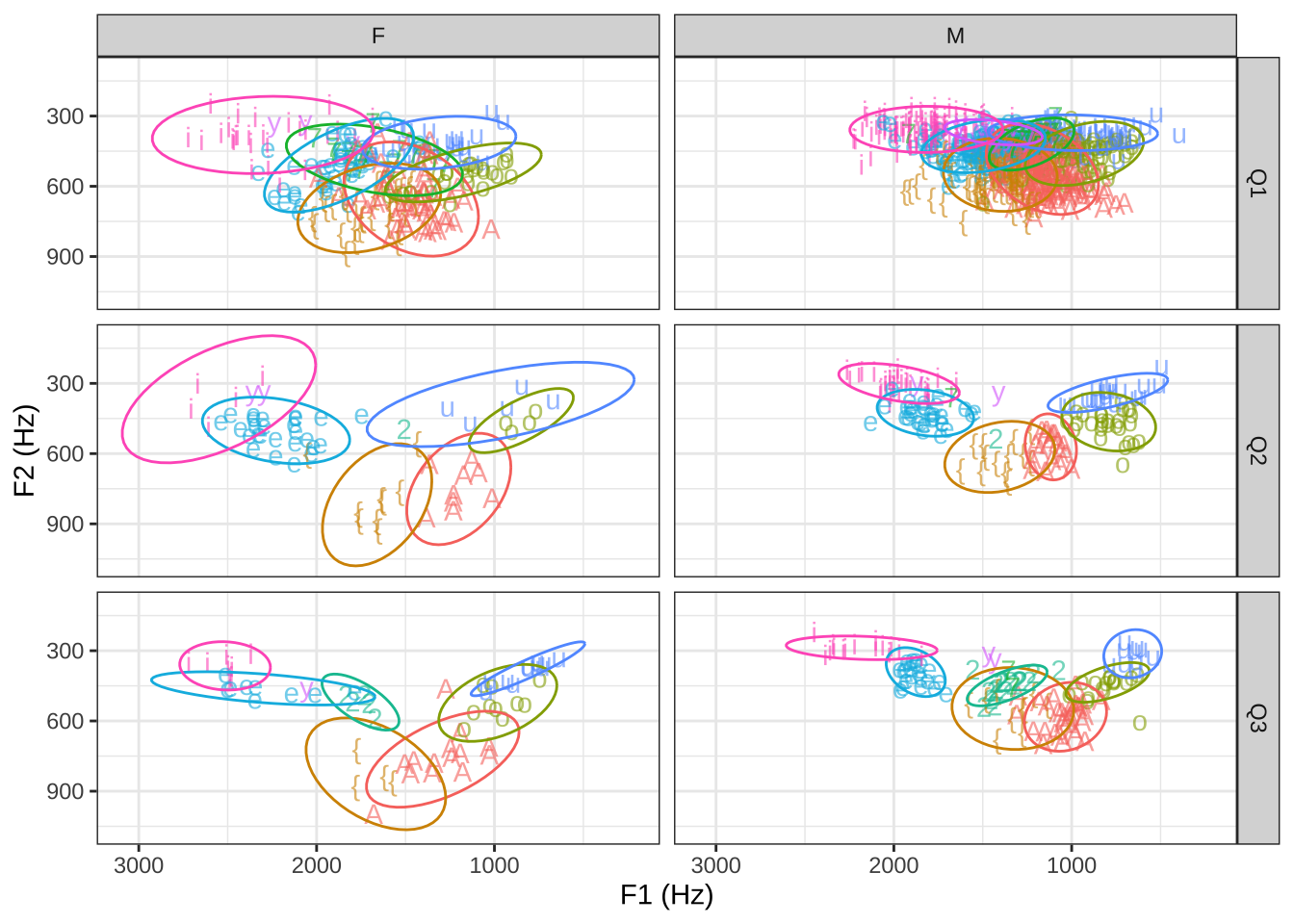
Joonis 21.8: Rõhulise silbi vokaalid F1-F2 ruumis rühmitatud kõneleja soo ja sõna välte kaupa.
21.5.1 Vokaalidiagramm keskmiste väärtustega
Kui joonisel 21.8 on näha kõik üksikud mõõtmispunktid, siis suurema andmestiku puhul võib joonis olla tihedalt täidetud ja infoga ülekoormatud.
Arvutame (dplyr paketiga) formantväärtuste keskmised soo, välte ja vokaalikategooria kaupa. Keskmistatud vokaalide väärtused on kujutatud joonisel 21.9.
dat %>%
filter(Struct == "cvcv") %>%
group_by(Gender, Quantity, V1.phon1) %>%
summarise(V1F1 = mean(V1F1), V1F2 = mean(V1F2)) %>%
ggplot(aes(y=V1F1, x = V1F2, shape = V1.phon1, col = Quantity))+
geom_label(aes(label = V1.phon1))+
scale_x_reverse()+
scale_y_reverse()+
labs(x = "F1 (Hz)", y="F2 (Hz)") +
#guides(color = "none") +
facet_grid(. ~ Gender)+
theme_bw()+
NULL 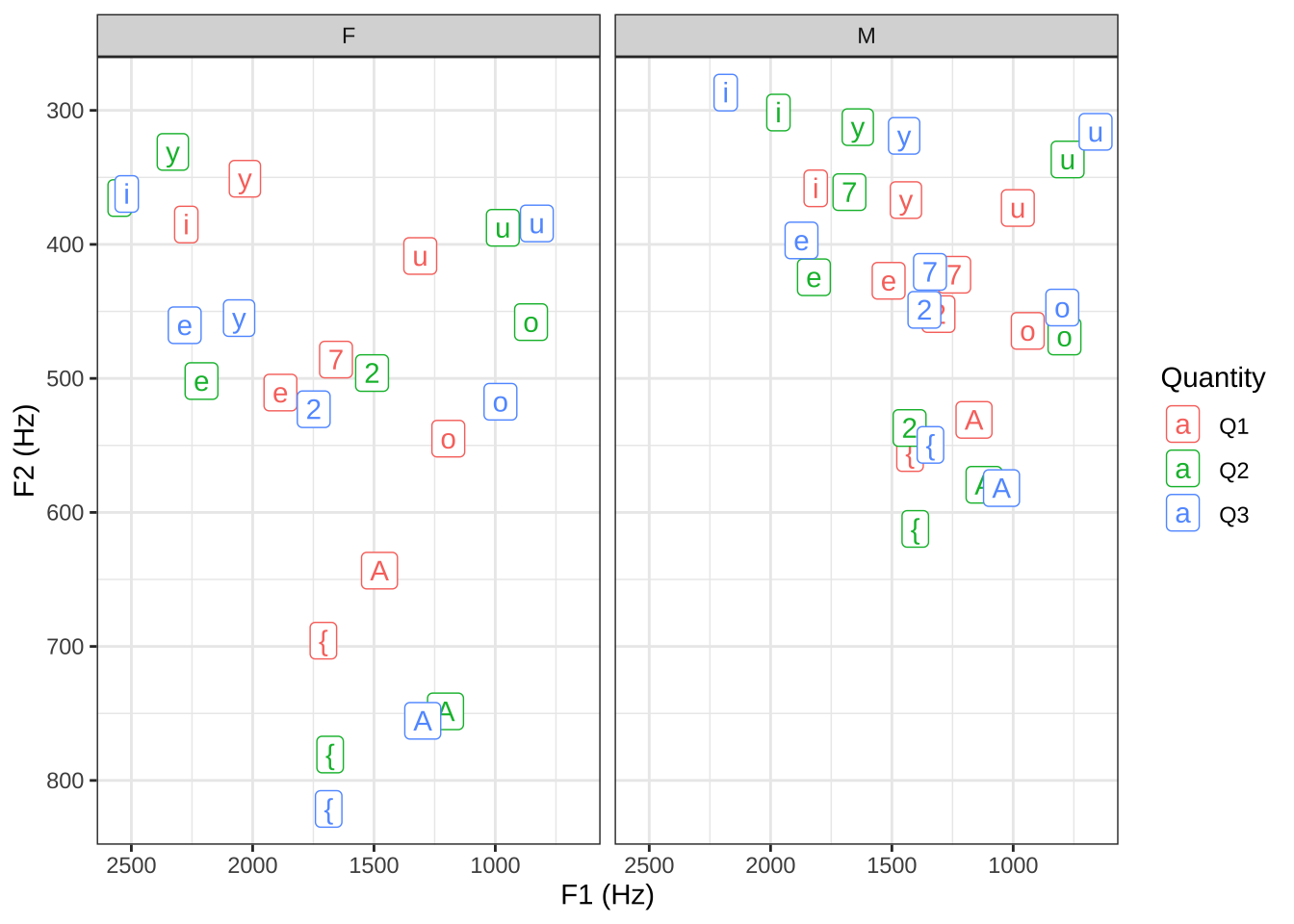
Joonis 21.9: Rõhulise silbi vokaalide keskmised väärtused F1-F2 ruumis rühmitatud kõneleja soo ja sõna välte kaupa.
21.5.2 Kõnelejatevaheline normaliseerimine
Et näidata ühel joonisel võrdlevalt erinevate kõnelejate vokaale, võime formantväärtuseid normaliseerida, nagu seda on pikemalt kirjeldatud peatükis 9.4.
Esmalt sisestame funktsioon z-skoorimiseks – selle leiaks valmis kujul ka mõnest R-i paketist, aga see on oma olemuselt äärmiselt lihtne, sellest arusaamiseks on hea seda siin vaadata.
Teisendame formantväärtused z-skoorideks. Seda teeme tsükliga keelejuhtide kaupa.
for(i in unique(dat$SP)){
dat$V1F1norm[dat$SP==i] <- zskoor(dat$V1F1[dat$SP==i])
dat$V1F2norm[dat$SP==i] <- zskoor(dat$V1F2[dat$SP==i])
}Nüüd kanname joonisele iga kõneleja vokaalide keskmised normaliseeritud formantväärtused. Joonisel 21.10 tähistab iga punkt ühe kõneleja selle vokaalikategooria keskmist.
dat %>%
filter(Struct == "cvcv") %>%
group_by(SP, V1.phon1) %>%
summarise(V1F1 = mean(V1F1norm), V1F2 = mean(V1F2norm)) %>%
ggplot(aes(y=V1F1, x = V1F2, shape = V1.phon1, col = V1.phon1))+
geom_text(aes(label = V1.phon1))+
scale_x_reverse()+
scale_y_reverse()+
labs(x = "F1 (z-skoor)", y="F2 (z-skoor)") +
guides(color = "none") +
theme_bw()+
NULL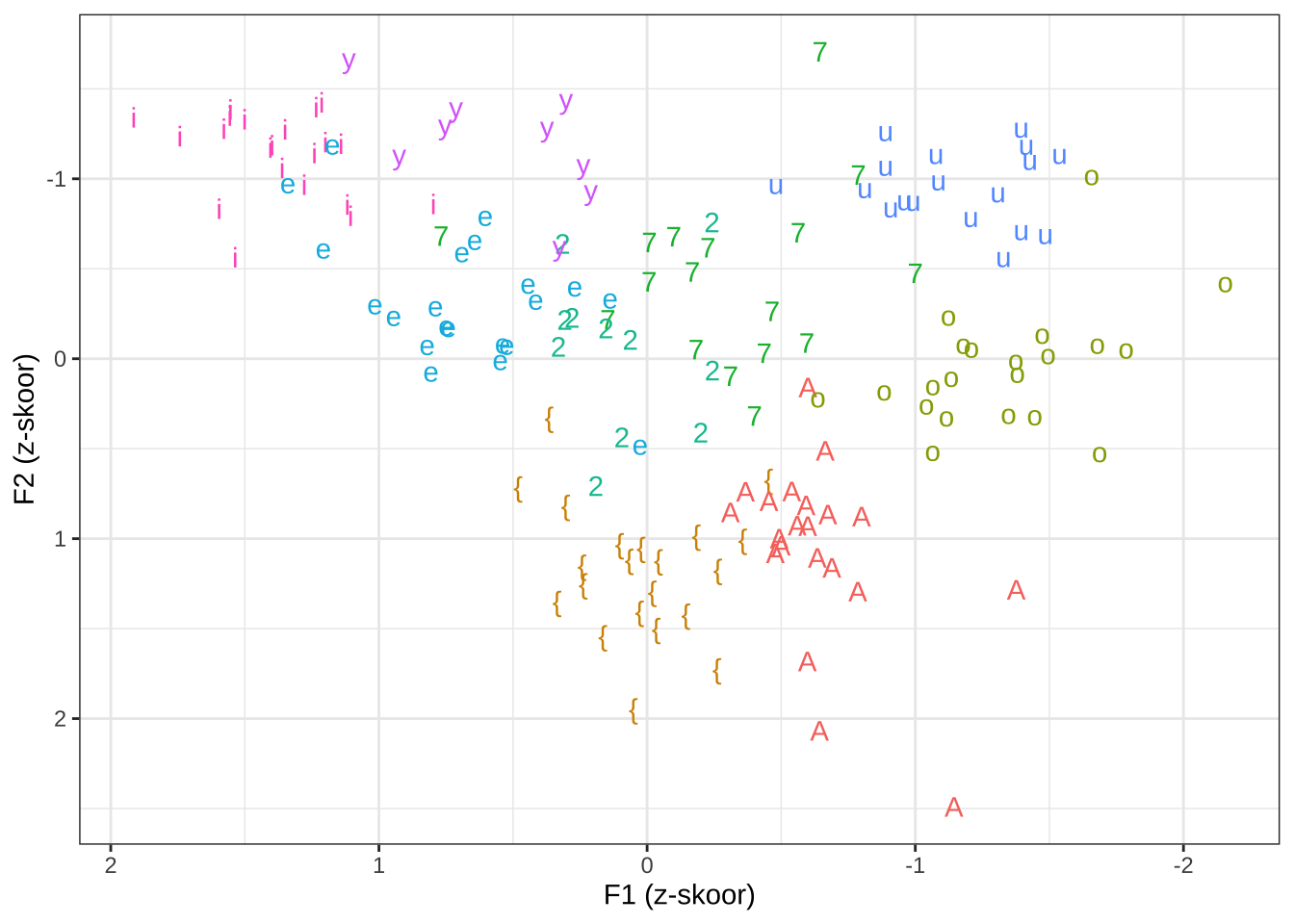
Joonis 21.10: Normaliseeritud rõhulise silbi vokaalid F1-F2 ruumis.
Kirjandus
Seda saab vajadusel kasutada põhitooni kõrguse kindluse hindamiseks ning heliliseks lugeda ainult need punktid, mille autokorrelatsiooni väärtus on kõrge.↩︎
Täpsemini siin on aritmeetilise keskmise asemel võetud mediaanväärtus, mis on vähem tundlik hälbivate väärtuste suhtes.↩︎
Kuna käsu sees tähistavad jutumärgid tekstistringi algust ja lõppu, tuleb skriptis sisalduvad jutumärgid tähistada ", et R loeks neid lihtsalt tähemärkidena.↩︎
Tabelis on vokaalid SAMPA transkriptsioonis. Joonise peal oleks kindlasti ilusam, kui teisendada need IPA transkriptsiooni ning selleks võib kasutada
phonTools::xsampatoIPAkäsku, kuid osa IPA sümbolite kuvamine võib olla probleemiks, kui tahad joonise või Rmarkdowni dokumendi salvestada pdf-formaadis. Seetõttu on siin märgendid jäetud SAMPA transkriptsiooni.↩︎