Peatükk 9 Vokaalid ja formantanalüüs
Häälik ehk foneem on keele väikseim tähendust eristav üksus. Häälikud jagunevad kõige laiemalt vokaalideks ja konsonantideks. Kõne moodustub vokaalide ja konsonantide vaheldumisest. Enamikus keeltes moodustavad vokaalid silbi tuuma ja konsonandid täidavad silbi algused ja lõpud.
Vokaalid on enamasti helilised (häälekurrud võnguvad) ja nende hääldamisel puudub suuõõne keskosas ahtus või sulg, nii et hääl pääseb vabalt välja. Konsonantide puhul moodustatakse kuskil kõnetraktis ahtus või sulg, mis takistab õhu vaba väljapääsu. Selle pärast on vokaalid sonoorsemad kui konsonandid.
Siiski on ka konsonante, mille puhul sulgu ei ole (poolvokaalid). Siis tuleb mängu teine tunnus ehk silbilisus: vokaalid moodustavad silbituuma ja konsonandid saavad olla kas silbi alguses või lõpus. Nii on poolvokaalid konsonandid selle pärast, et nad käituvad fonoloogiliselt kui konsonandid. Samas on ka keeli, kus ka konsonant võib olla silbituumaks.
Vokaale (ja häälikuid üldiselt) saab kirjeldada kahes dimensioonis: kvaliteet ehk moodustuskohast ja -viisist tingitud varieerumine ja kvantiteet ehk kestuslik varieerumine.
9.1 Eesti vokaalid transkriptsioonis
Häälikute kirjapanemiseks kasutatakse foneetilist transkriptsiooni. Kõige levinum foneetiline transkriptsioon on IPA (International Phonetic Alphabet). IPA kõrval kasutatakse foneetiliste andmestike märgendamiseks sageli SAMPA transkriptsiooni, mis on IPA lihtsustatud variant (sellest põhjalikumalt ptk 14.3). Eesti murrete ja sugulaskeelte kirjeldamisel on ka kasutatud Soome-Ugri transkriptsiooni (Ariste 1978), mida aga foneetika uurimustes tänapäeval väga sageli ei kasutata.
Eesti keeles on üheksa vokaalfoneemi, vt tabel 9.1.
| Ortograafia | IPA | SAMPA | Kirjeldus |
|---|---|---|---|
| a | ɑ | A | ümardamata madal tagavokaal |
| o | o | o | ümardatud keskkõrge tagavokaal |
| õ | ɤ | 7 | ümardamata keskkõrge tagavokaal |
| u | u | u | ümardatud kõrge tagavokaal |
| ä | æ | { | ümardamata madal eesvokaal |
| e | e | e | ümardamata keskkõrge eesvokaal |
| ö | ø | 2 | ümardatud keskkõrge eesvokaal |
| i | i | i | ümardamata kõrge eesvokaal |
| ü | y | y | ümardatud kõrge eesvokaal |
Eesti keeles on ka 36 diftongi, mida aga peetakse ülidselt häälikujärjenditeks mitte vokaalfoneemideks, mistõttu siin peatükis neid pikemalt ei käsitleta, aga vt ka ptk 11.1 ja 14.2.6.
9.2 Vokaali kvaliteet
Vokaale jagatakse nende moodustuskoha järgi kolmes kategoorias:
- Esiteks suu avatuse ja keeleselja tõusu järgi kõrgeteks (inglise keeles close) ja madalateks (open) – suu on kas vähem või rohkem avatud ning keel asub suus kõrgel või madalal. Õieti enamasti on siin neli tasandit: kõrge, keskkõrge, keskmadal ja madal.
- Teiseks jagatakse vokaalid ees- ja tagavokaalideks (front ja back). Eesvokaalide puhul on keeletipp hammastele lähemal, tagavokaalide puhul hammastest kaugemal. Ka siin on vaheaste keskvokaalide näol.
- Kolmandaks jagatakse labiaalseteks ehk ümardatud (rounded) ja illabiaalseteks ehk ümardamata (unrounded) vokaalideks selle järgi, kas hääldamisel on huuled ümardatud või mitte.
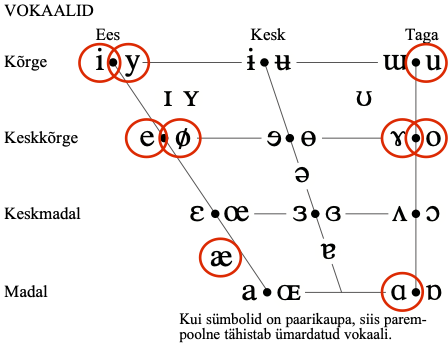
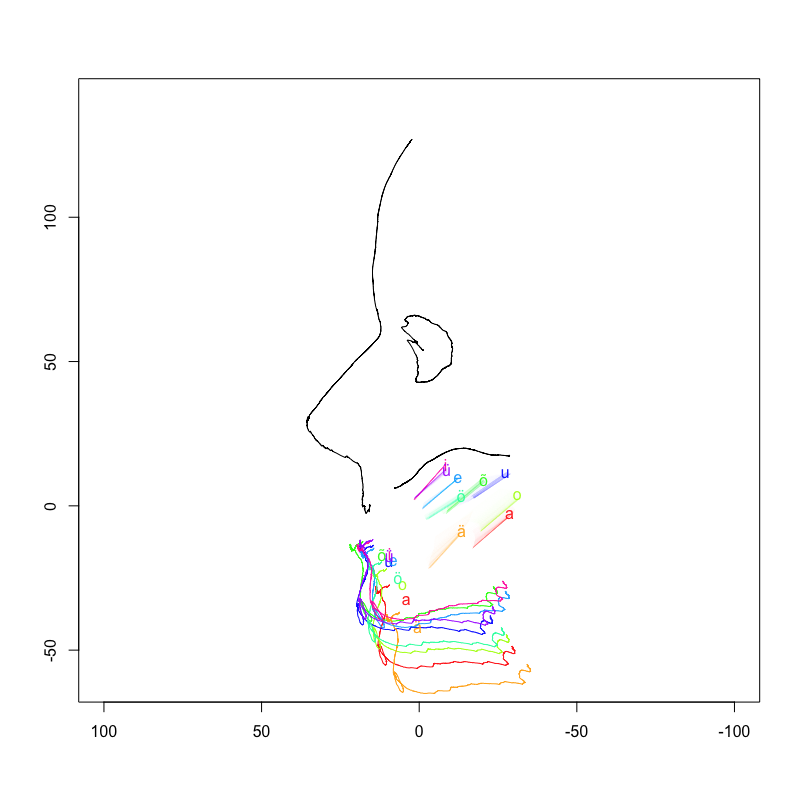
Joonis 9.1: IPA vokaalidiagramm (vasakul) ja artikulograafiga salvestatud eesti vokaalide moodustuskohad (paremal).
Seda, kuidas kõneorganid mingi hääliku hääldamisel paiknevad, saab uurida erinevate artikulatoorse foneetika uurimismeetoditega, näiteks ultraheli, elektromagnetartikulograafi või tomograafiga. Näiteks joonisel 9.1 parmpoolsel paneelil on kujutatud keeleselja tõusuaste eesti vokaalide hääldamisel (vaata ka videot veidi allpool).
Aga kõneorganite asukoha kohta saab järeldusi teha ka akustilise signaali põhjal. Kuna kõneorganeid liigutades muudetakse kõnetrakti kuju, siis kõnetrakti erinev kuju summutab ja võimendab häälekurdudest tulevat signaali kindlates sagedusvahemikes. Neid kõnetrakti resonantssagedusi nimetatakse formantideks. Seda kajastab spektrimähisjoon: kõnehääle spektri mähisjoone tipud langevad kokku formantidega ja iseloomustavad häälikute moodustuskohta. Vokaalide puhul mõõdetakse tavaliselt esimese kolme formanti:
- esimese formandi (F1) väärtus on seda suurem, mida avatum on suu;
- teise formandi (F2) väärtus on seda suurem, kui keel on suus eespool;
- kolmanda formandi (F3) väärtus sõltub huulte ümardatusest.
Tihti piirdutakse ka ainult esimese kahe formandiga (F1 ja F2) ja kirjeldatakse vokaale kahe tunnuse (kõrge-madal ning ees-taga) põhjal. Joonis 9.2 pärineb Eek & Meister (1994) artiklist ja põhineb ühe keelejuhi hääldusest. Kuna hääldus on varieeruv nii kõnelejate vahel kui ka ühe kõneleja piires, esitatakse selliseid mõõtmisi keskmistatult üle korduvate hääldusjuhtude.

Joonis 9.2: Eesti keele vokaalid. Joonis: Eek ja Meister (1994).
Järgnev video on tehtud artikulograafi salvestuse põhjal ja näitlikustab seda, kuidas akustilisest signaalist mõõdetud formandid ja moodustuskoht omavahel seotud on. Artikulograafi salvestusel pandi katseisikule keelele kaks sensorit ja videol on keele liikumine markeeritud nennde kahe punkti vahele tõmmatud sirge joonega. alalõuast on tehtud staatiline kontuur ning selle liikumine on modelleeritud alumisele igemele paigutatud sensori liikumise põhjal. Katseisik hääldas eraldi kõiki eesti keele 9 vokaali. Lisaks keele ja lõua liikumisele salvestati ka helisignaal. Vasakul on näha helisignaalist leitud formantide muutumine, paremal artikulaatorite liikumine.
9.3 Formantanalüüs Praatis
- Lae oma arvutisse helifail isoleeritud_vokaalid.wav
- ja selle transkriptsioonifail isoleeritud_vokaalid.TextGrid
- Ava mõlemad failid Praatis (Praati objektiaknas
Open>Read from file...).
TextGrid on objektitüüp, mis sisaldab helifailiga lingitud transkriptiooni. Vali mõlemad objektid (Sound ja TextGrid): klõpsa vasaku hiireklahviga ühe peal ja vea teise peale klahvi all hoides või klõpsa ühe peal, vajuta alla CTRL-klahv ja klõpsa teise peal). Vajuta nuppu View & Edit.
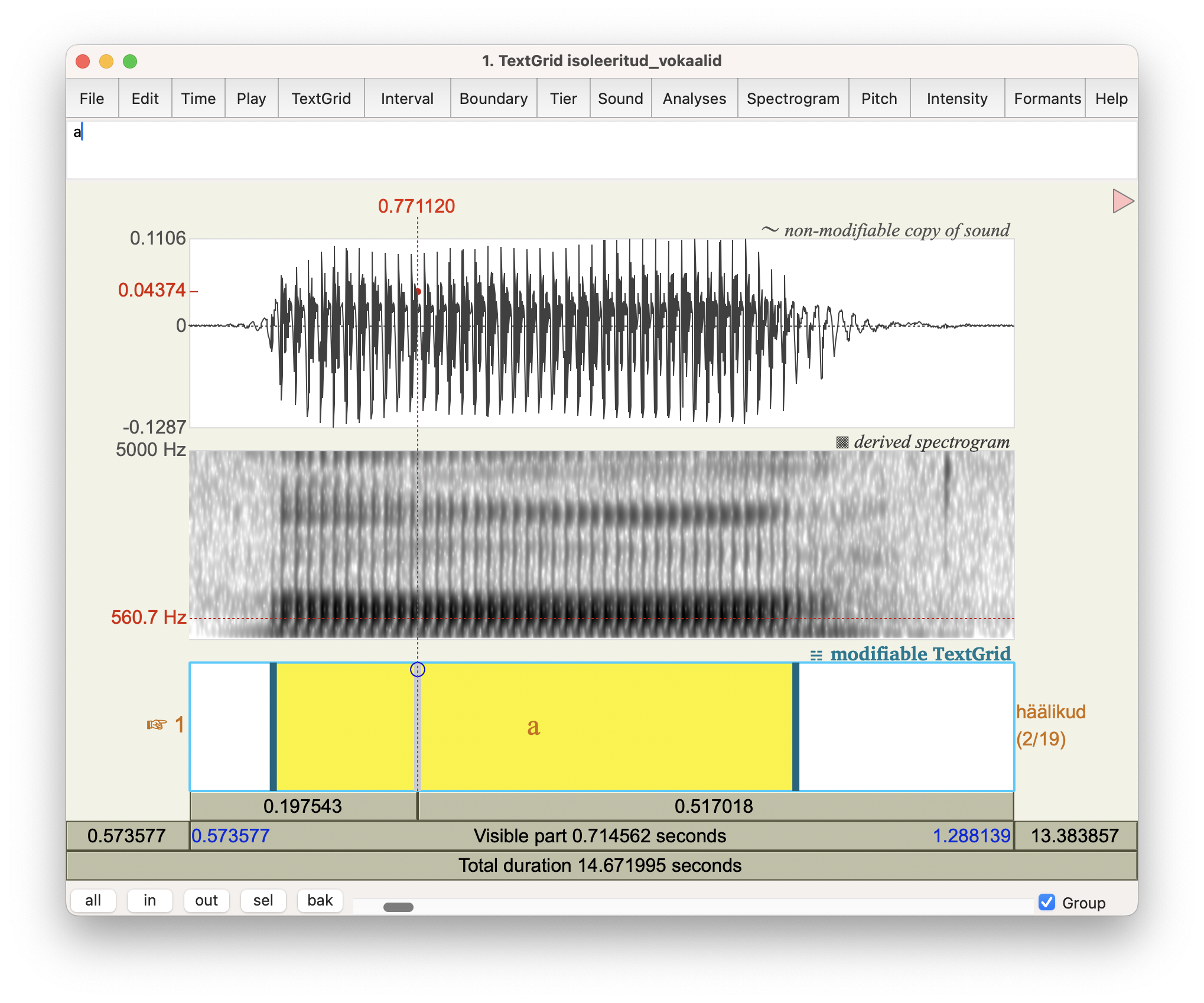
Joonis 9.3: TextGridEditori ekraanivaade.
Toimetamisaken on jagatud kolmeks, kõige alumine osa sisaldab häälikupiire ja transkriptsiooni. TextGrid objektidest tuleb põhjalikumalt juttu edaspidi, praegu vaatame isoleeritult hääldatud vokaalide formantstruktuuri.
Vaata igaks juhuks üle ka spektrogrammi seaded, et kindlasti vaataksid lairiba spektrogrammi, mitte kitsaribalist. Selleks ava menüüst Spectrogram > Spectrogram settings ja sea analüüsiakna pikkuseks (Window length) 0.005 sekundit.
Formandi väärtuse leidmiseks liiguta spektrogrammil kursor kohakuti ajateljel vokaali keskkohaga, sagedusteljel (alt lugema hakates) esimese horisontaalselt jooksva kõige tumedama kohaga. Nii saad esimese formandi (F1). Teine formant (F2) on teine tumedam jutt jne. Näiteks joonisel 9.3 on kursor kohakuti esimese formandi väärtusega. Kuna aga F1 ja F2 on madalal tagavokaalil üksteisele lähedal, siis siin ei ole visuaalselt spektrogrammi põhjal neid väga lihtne eristada.
Võid ka teha vokaalist spektri (menüü Spectrogram > View spectral slice) ja kontrollida spektrogrammi ja spektri kokkulangevust (vt joonist 8.4 peatükis ??).
Joonisel 9.4 on märgitud faili isoleeritud_vokaalid.wav vokaalide spektrogrammil esimese, teise ja kolmanda formandi asukohad.
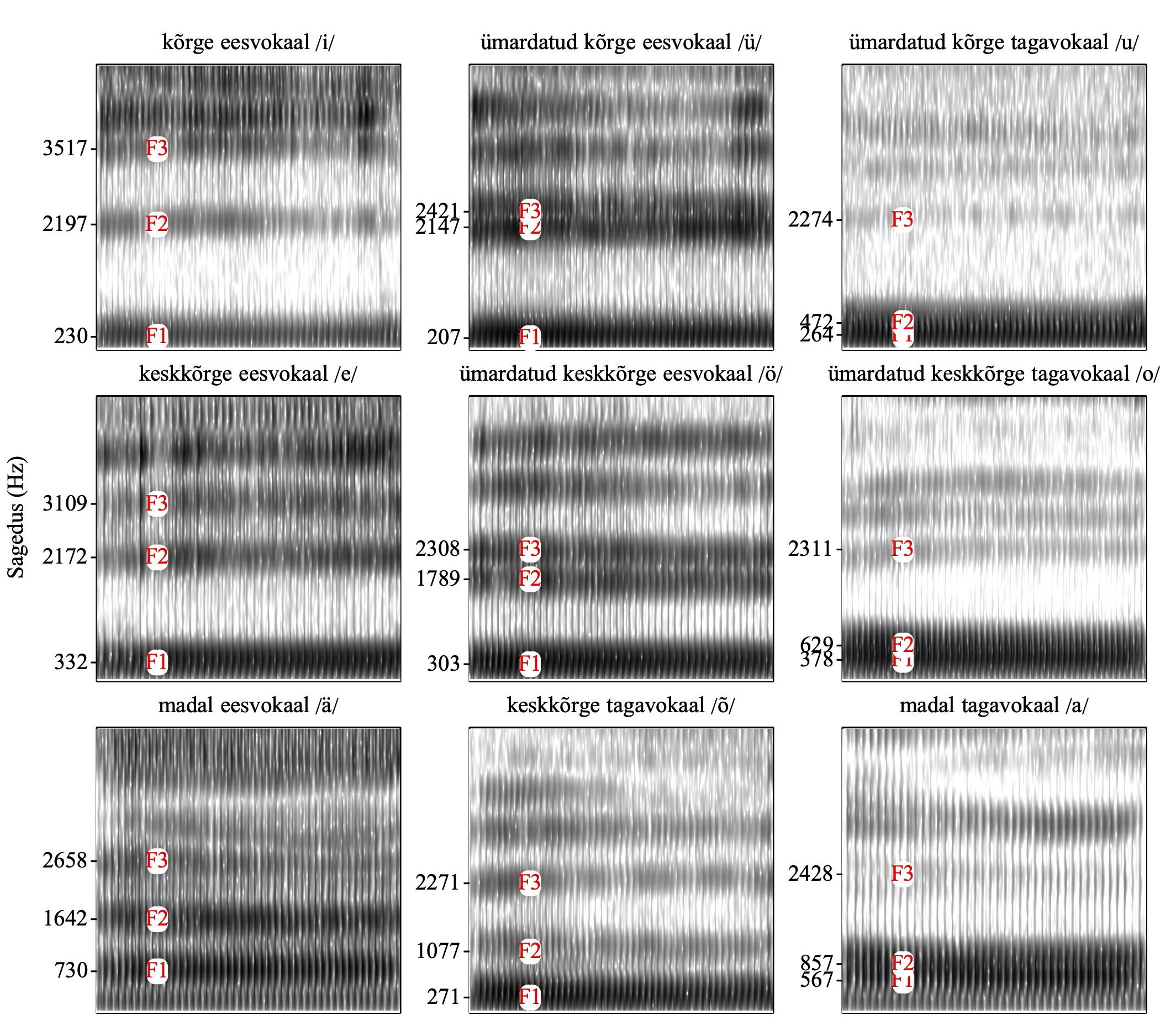
Joonis 9.4: Isoleeritult hääldatud eesti vokaalide spektrogrammid.
Nii nagu inimkõne üldse, on vokaalide formantväärtused väga varieeruvad. Varieerumise peamisteks põhjusteks on inimeste kõnetrakti erinevused, häälikuline kontekst ja kõnelemise situatsioon.
Iga inimese kõnetrakti kuju ja proportsioonid on pisut erinevad, mistõttu tema hääl, kõnemaneer on isikupärased, selle järgi me tunneme inimesi ära. Kontekst mõjutab iga hääliku hääldamist: mis häälikud eelnevad, mis järgnevad (kuna kõneorganid liiguvad sujuvalt ühe hääliku moodustuskohalt teisele, siis on igas eelmises kuulda järgmist ja järgmises eelmist), kas sõna ja silp on rõhuline või rõhuta (rõhulisi hääldame suurema energiaga).
Kõnesituatsioon mõjutab seda, kui hoolikalt me hääldame - võõra inimesega ametlikus situatsioonis hääldame korralikumalt kui argisituatsioonis tuttavaga rääkides. See kõik mõjutab hääldust nii, et isegi üks inimene ühte häälikut kaks korda täpselt ühte moodi ei ole võimeline hääldama. Seetõttu erinevad vokaalide formantväärtused eri kõnelejatel, eri häälduskordadel, eri sõnades, rõhulistes ja rõhututes silpides jne.
Kuna vokaalikvaliteedi hindamine formantanüüsi teel on kvantitatiivne analüüs ja nimetatud põhjustel on palju varieerumist, tuleks vokaalide kvaliteedi kohta järelduste tegemiseks mõõtmisi korrata: mõõta mitut eri kõnelejat ja igalt kõnelejalt mitut hääldusjuhtu.
9.3.1 Automaatne formantanalüüs
Lisaks sellele, et otsida formante spektrogrammi või spektri pealt, võib lasta formante otsida arvutil (vt ka ptk 8.2.3. See meetod pole aga alati töökindel, nii et spektrogrammi peab ka jälgima ja kahtluse korral kontrollima.
Vali Soundeditoris menüüst Analysis > Show analysis... ja lisa linnuke kasti Show formants. Nüüd peaksid tekkima spektrogrammi peale punased täpikesed. Nende kohtade peal on tõenäoliselt formandid.
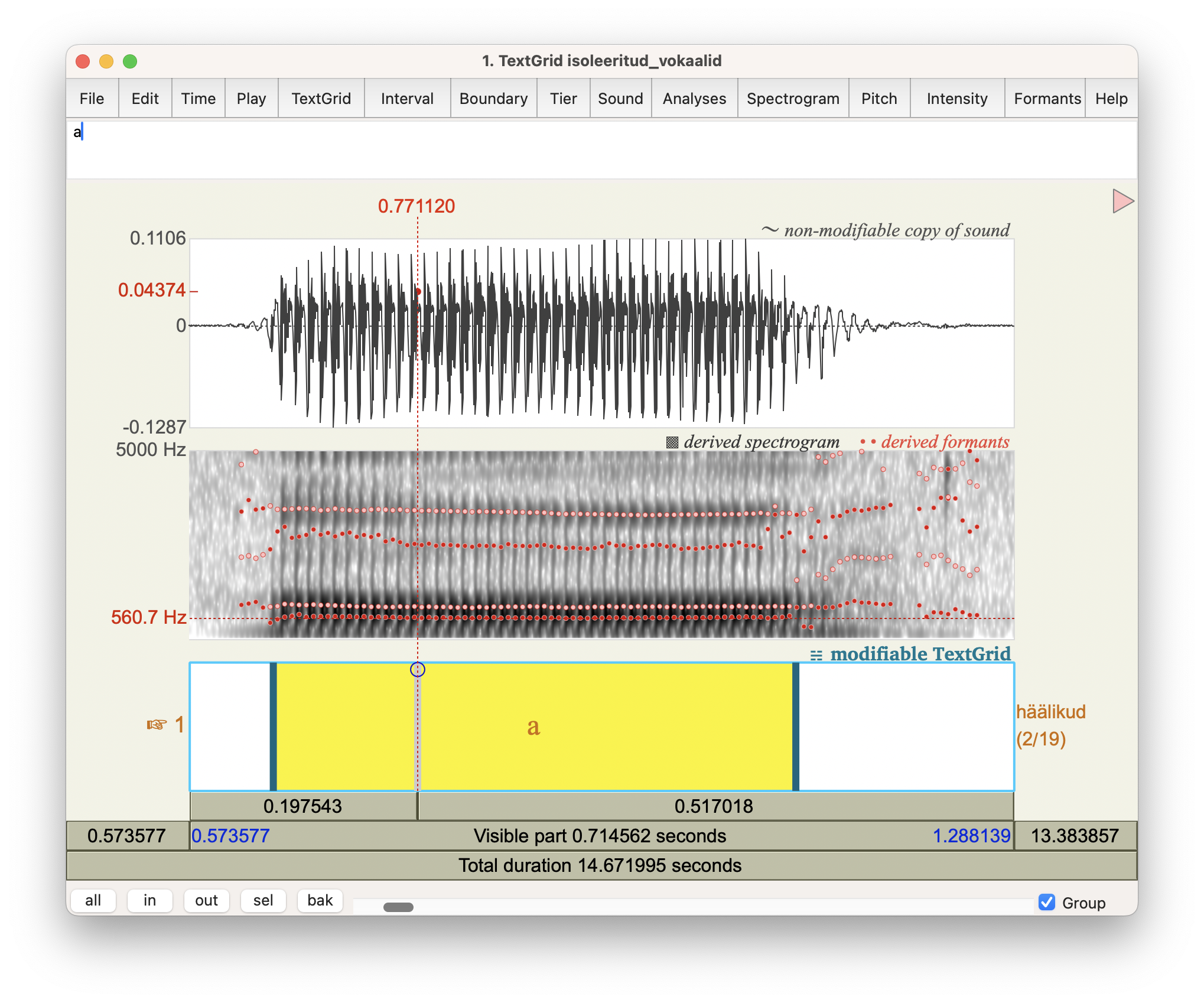
Joonis 9.5: Formantanalüüs Praatis.
Formantanalüüs teeb tihti vigu. Seetõttu tuleb alati tähelepanelik olla:
- kui kuulete nt madalat vokaali (mille F1 peaks olema küllaltki suure väärtusega), aga formantanalüüs pakub F1 väärtuseks sellist, mis sobiks kõrgele vokaalile, on tõenäoline, et F1 on segi aetud põhitooniga;
- keskkõrgetel ja kõrgetel tagavokaalidel (/o/ ja /u/) kipuvad F1 ja F2 olema väga lähestikku ja formantanalüüs võib kahe formandi asemel pakkuda üht. /o/ ja /u/ puhul annab formantanalüüs parema tulemuse, kui seadetest analüüsi lae (Formant ceiling) väärtust alandada paarisaja hertsi võrra (vt joonis 9.7).
Formants > Formant listing annab esimese nelja formandi väärtused ajahetkest, mis on kursoriga märgitud. Kui kursoriga on märgitud pikem lõik, antakse loend formantväärtustest igas leitud punktis.
Menüü Formants käsud Get first formant, Get second formant jne leiavad soovitud formandi väärtuse kursoriga märgitud ajahetkel või valitud lõigu keskmise formantväärtuse. Sama käsku täidavad klaviatuuril klahvid F1, F2, F3 ja F4.
Tabelis 9.2 on nende vokaalide F1, F2 ja F3 väärtused hertsides, nii nagu mina neid mõõtsin. Proovi, kas saad sarnased tulemused. Formantanalüüs ei ole väga täpne, kõikumised paari hertsi ulatuses on täiesti normaalsed.
| Vokaal | IPA | F1 | F2 | F3 |
|---|---|---|---|---|
| a | ɑ | 567 | 857 | 2428 |
| o | o | 378 | 629 | 2311 |
| õ | ɤ | 271 | 1077 | 2271 |
| u | u | 264 | 472 | 2274 |
| ä | æ | 730 | 1642 | 2658 |
| e | e | 332 | 2172 | 3109 |
| ö | ø | 303 | 1789 | 2308 |
| i | i | 230 | 2197 | 3517 |
| ü | y | 207 | 2147 | 2421 |
Neid samu formantväärtusi võib kujutada ka joonisel 9.6, kus vasakpoolsel paneelil on horisontaalteljel on F2 väärtused ja vertikaalteljel F1 väärtused. Vokaalide kujutamisel F1-F2 ruumis on kombeks, et skaalad on pööratud, st väärtused muutuvad vasakult paremale ja alt üles suuremast väiksemaks. Parempoolsel paneelil on F3 (ja F2) väärtused. Kolmandat formanti seostatakse huulte ümardatusega: ümardatud huultega häädatud vokaalidel on F3 väärtus madalam, kui F3 seosed artikulatsiooniga ei ole nii selged kui F1 vokaali kõrguse ja F2 eespoolsusega.
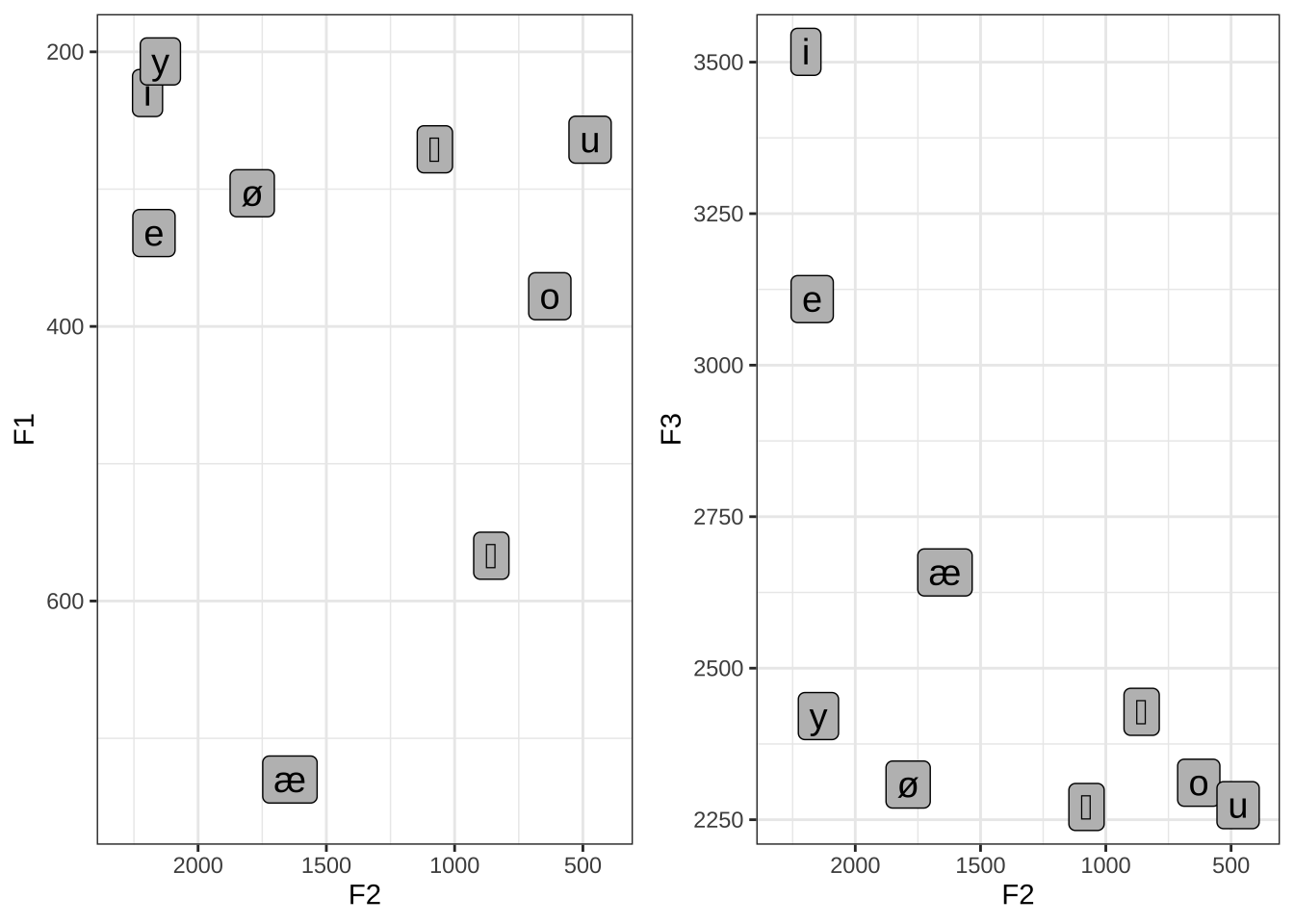
Joonis 9.6: Eesti vokaalid F1-F2 formantruumis (vasakul) ja F2-F3 (paremal).
9.3.2 Mis ajahetkest formante mõõta?
Traditsiooniliselt soovitatakse formante mõõta nende stabiilse osa pealt ja see stabiilne osa võiks olla saavutatud umbes 1/3–1/2 vokaali kestusest. Seega kui mõõdad formante käsitis, st paned kursori silma järgi spektrogrammil formantidega kohakuti või küsid väärtuseid Get first formant ja Get second formant käskudega, siis võiks kursoriga sihtida umbes vokaali esimese poole lõppu.
Kui toetuda automaatsele formantanalüüsile, siis natuke kindlama tulemuse saab siis, kui mõõta formante mitte ühest punktist vaid natuke pikemast lõigust, sest nii väheneb võimalus, et just selles punktis formantanalüüs hälbib tegelikust väärtusest. Kui mõõta formante vokaali keskosast, siis võiks valida umbes 20-30 ms pikkuse lõigu ja mõõta formandi väärtusena lõigu keskmist.
Kindlasti on soovitatav teha mõõtmised skripti abil, sest skriptis saab täpselt määrata analüüsi parameetrid nii, et iga mõõtmise puhul oleks mõõtmispunkt täpselt sama koha peal ja ajaaken täpselt sama kestusega.
Kui analüüsida koartikulatsiooni või diftonge, siis oleks mõistlik formante mõõta mitmest punktist vokaali jooksul. Üks võimalus oleks salvestada kõik formantanalüüsi punktid (nt valida kursoriga kogu vokaal ning Formant listing). Sellega on ainult probleem, et kuna vokaalid on erineva kestusega ja formantanalüüsi punktid on kindla ajasammuga, siis eri mõõtmisjuhtudel saame erineva hulga punkte ning kui me tahame need väärtused kanda laia tabelisse (st ühe vokaali kohta on tabelis üks rida ja mõõtmispunkti kohta on üks tulp), siis sellist tabelit on keeruline analüüsida (nt R ja Praat ise ja paljud teised programmid eeldavad, et tabelis on igal real sama palju tulpasid). Seetõttu mõõdetakse sageli formante iga vokaali kohta proportsionaalselt jaotatud punktidest. Mitmest punktist, sõltub sellest, kui pikad on segmendid ja kui täpselt neid on vaja kirjeldada. Näiteks kui mõõta 20 punktist ja vokaalide pikkus varieerub vahemikus 50-300 ms, siis kõige lühemate vokaalidel on samm 2.5 ms ja kõige pikematel 15 millisekundit.
9.3.3 Formantanalüüsi lagi
Nagu juba mainitud, võib formantanalüüs teha vigu, aga parema tulemuse saab siis, kui formantanalüüsi lage seadistada sõltuvalt kõneleja häälekõrgusest ja vokaali moodustuskohast. Kõige üldisem soovitus on kõrgema hääle puhul kõrgemat lage (meestel 5000 Hz, naistel 5500 Hz). Aga veel parema tulemuse saab siis, kui optimeerida lage iga kõneleja igale foneemiklassile.
Näiteks isoleeritud_vokaalid.wav vokaale analüüsides on 5000 Hz muidu sobiv (parempoolne joonis 9.7), aga /u/ kipub minema valesse kohta (F1 ja F2 analüüsitakse üheks formandiks ja F2-ks peetakse ekslikult F3-e). Joonisel 9.7 paremal on analüüsilagi 4600 Hz ja siin on /u/ õiges kohas, aga /i/ puhul on palju vigu. Seega parema tulemuse saab siis, kui /u/ ja /o/ formantanalüüs teha ühtede seadetega ja ülejäänud vokaalid teistega.
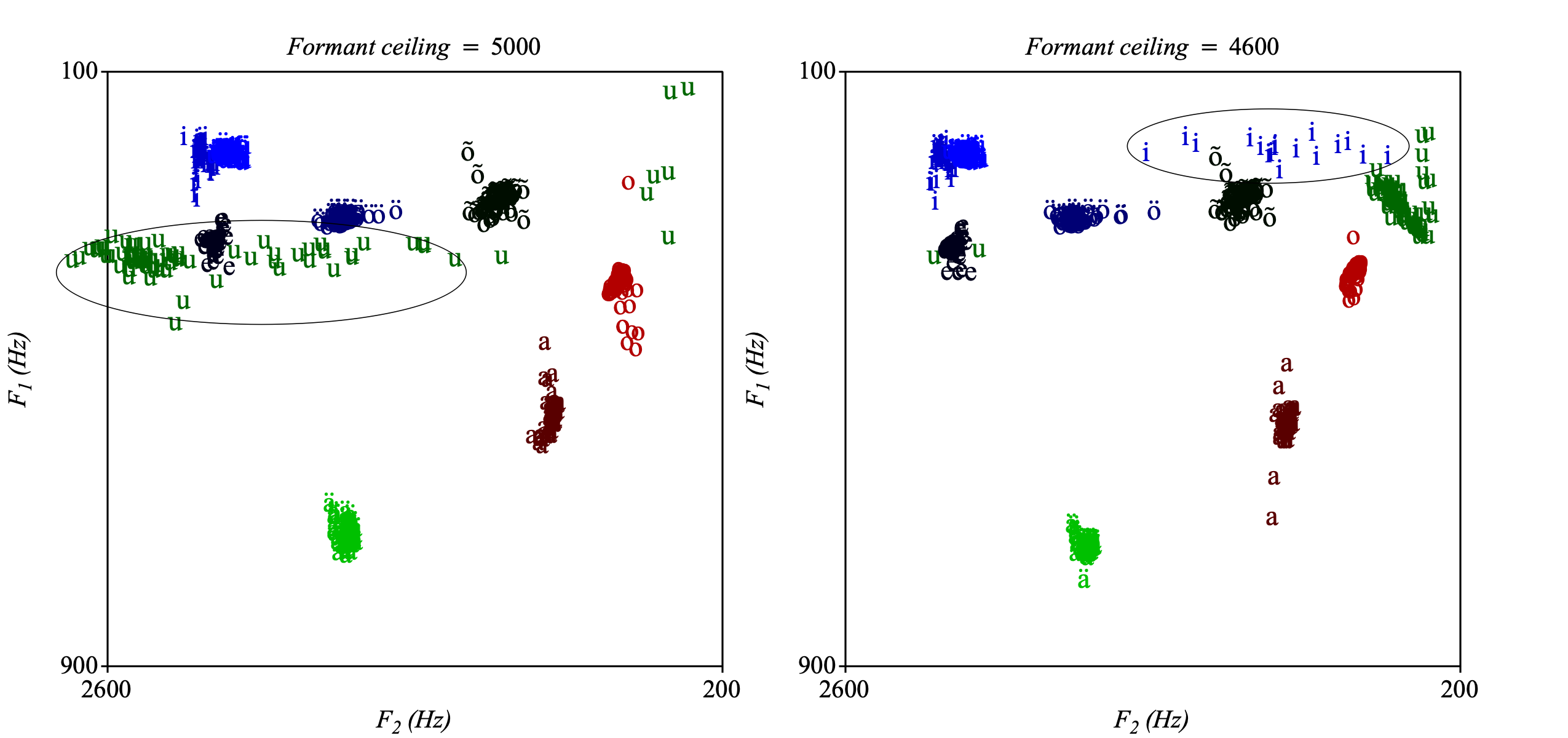
Joonis 9.7: Vokaalidiagramm erinevate analüüsiseadetega. Vasakul lagi 5000 Hz, paremal 4600 Hz.
Aga veel parem on valida igale vokaaliklassile optimaalne lagi. Automaatselt saab seda teha näiteks vokaali formandipunktide dispersiooni järgi, nagu on teinud Escudero et al. (2009) (ja nende eeskujul nt Lippus & Asu (2019) ja Leppik, Lippus & Asu (2023)):
- Iga vokaali formantanalüüs (käsuga
Analyse spectrum>To Formant (burg)...) tehakse erinevate formantlagedega meestel vahemikus 4000-6000 Hz ja naistel 4500-6500 Hz sammuga 10 Hz (kokku 201 analüüsi, et läbida 2000 Hz vahemik 10 Hz sammudega). - iga analüüsiga mõõdetakse F1 ja F2 väärtused 20 punktist 40% vokaali keskosast.
- kummagi formandi väärtused logaritmitakse, leitakse dispersioon ja dispersioonid liidetakse.
- optimaalseks laeks loetakse seda, mille puhul on dispersioon kõige madalam.
See meetod aga pigem eeldab skripti kasutamist, sest graafilise kasutajaliidese kaudu käsitsi seda teha on väga tülikas. Ka skriptiga on iga vokaali puhul analüüsi kordamine 201 korda küllaltki ressursimahukas protseduur.
Optimaalse formantlae leidmise funktsioonid on alates 2023. aastast ka Praati implementeeritud (Weenink 2023). Selleks on käsk Analyse Spectrum > To FormantPath (burg)... (mida põgusalt vaatasime ka peatükis 8.2.3). Tavalise formantanalüüsiga võrreldes on seadetes kaks täiendavat lahtrit:
- Ceiling step size – koefitsient, mille võrra lage muudetakse, nt vaikimisi väärtustega keskmine lagi on 5500 Hz ja samm on 0.05 ehk 5500*0.05 = 275 Hz.
- Number of steps up/down – mitu sammu üles ja alla liigutakse. Nt kui väärtus on neli, tehakse kokku 9 analüüsi: keskmise formantlaega (mis vaikimisi on 5500 Hz), neli sammu sellest alla (5225, 4950, 4675 ja 4400) ja neli sammu üles (5775, 6050, 6325 ja 6600 Hz).
Kui nüüd valida objektiaknas korraga Sound ja FormantPath (ja TextGrid) objektid ja View & Edit, siis avaneb editor, kus paremal on erinevate lagedega formantanalüüsid ja kui mõne peal klõpsata, siis kuvatakse seda analüüsi spektrogrammi peale. Nii on võimalik välja valida see analüüs, mis kõige paremini sobib mingi kindla vokaali jaoks.
FormantPath objekti Query menüüst leiab ka käsu Get optimal ceiling, mis automaatselt pakub optimaalset formantlae väärtust.
Tabelis 9.3 leiab ühe meeskõneleja (failist isoleeritud_vokaalid.wav) ja ühe naiskõneleja (0063.wav, millest pärineb ka joonisel 9.1 artikulograafi andmetel põhinev joonis) eesti keele 9 vokaali isoleeritud häälduses, iga vokaali esitatud ühe korra. Formantanalüüsi keskmiseks laeks valiti meeskõnelejal 4500 Hz ning naiskõnelejal 5000 Hz ning analüüsi sammu kordajaks oli mõlemal 0.005 (ehk mees- ja naiskõnelejal vastavalt 22.5 ja 25 Hz) ning analüüsi samme 25 keskmisest mõlemas suunas ehk kokku 51 analüüsi, meeskõnalejal vahemikus 3927.5-4062.5 Hz ja naiskõnelejal 4375-5625 Hz. Tulemused on kõrvutatud joonisel 9.8.
| sugu | vokaal | lagi | F1 | F2 | F3 |
|---|---|---|---|---|---|
| mees | a | 4731 | 564 | 867 | 2346 |
| mees | e | 3971 | 340 | 2085 | 2381 |
| mees | i | 4826 | 216 | 2223 | 3548 |
| mees | o | 4031 | 358 | 606 | 2284 |
| mees | u | 4637 | 271 | 476 | 2365 |
| mees | ä | 4324 | 743 | 1621 | 2507 |
| mees | õ | 3971 | 297 | 1140 | 2324 |
| mees | ö | 4778 | 297 | 1661 | 2153 |
| mees | ü | 4113 | 221 | 2090 | 2460 |
| naine | a | 4950 | 693 | 1003 | 2818 |
| naine | e | 4852 | 447 | 1944 | 2638 |
| naine | i | 4412 | 397 | 2239 | 3248 |
| naine | o | 4616 | 452 | 770 | 2921 |
| naine | u | 4616 | 320 | 766 | 2503 |
| naine | ä | 5666 | 808 | 1703 | 2891 |
| naine | õ | 4412 | 450 | 1662 | 2711 |
| naine | ö | 4412 | 443 | 1699 | 2422 |
| naine | ü | 5609 | 316 | 1903 | 2510 |

Joonis 9.8: Eesti vokaalid F1-F2 formantruumis.
9.4 Vokaalikvaliteedi normaliseerimine
Jooniselt 9.8 näeme, et meeskõneleja vokaalid on üldiselt madalamate F1 ja F2 väärtustega. See erinevus tuleneb kõnetrakti pikkuse erinevusest, meestel on kõnetrakt pikem. Muidugi on ka bioloogilise soo piires varieerumist ning osaliselt on erinevused ka käitumuslikud (vt nt Simpson 2002).
Selleks, et bioloogilistele erinevustele vaatamata erinevate kõnelejate vokaale võrrelda, on võimalik formantväärtusi normaliseerida. Kõige tavalisem normaliseerimismeetod on z-skoorimine,20 mis teisendab väärtused standardhälbe skaalale.
\[\begin{equation} z_i = \frac{x_i - \bar{x}}{S} \tag{9.1} \end{equation}\]
Z-skoori (9.1) arvutatakse nii, et väärtusest lahutatakse rühma keskmine ja jagatakse läbi standardhälbega. Seega näiteks ühe kõneleja piires normaliseeritud formantväärtus näitab seda, kui palju hälbib ühe vokaali formantväärtus selle kõneleja keskmisest.
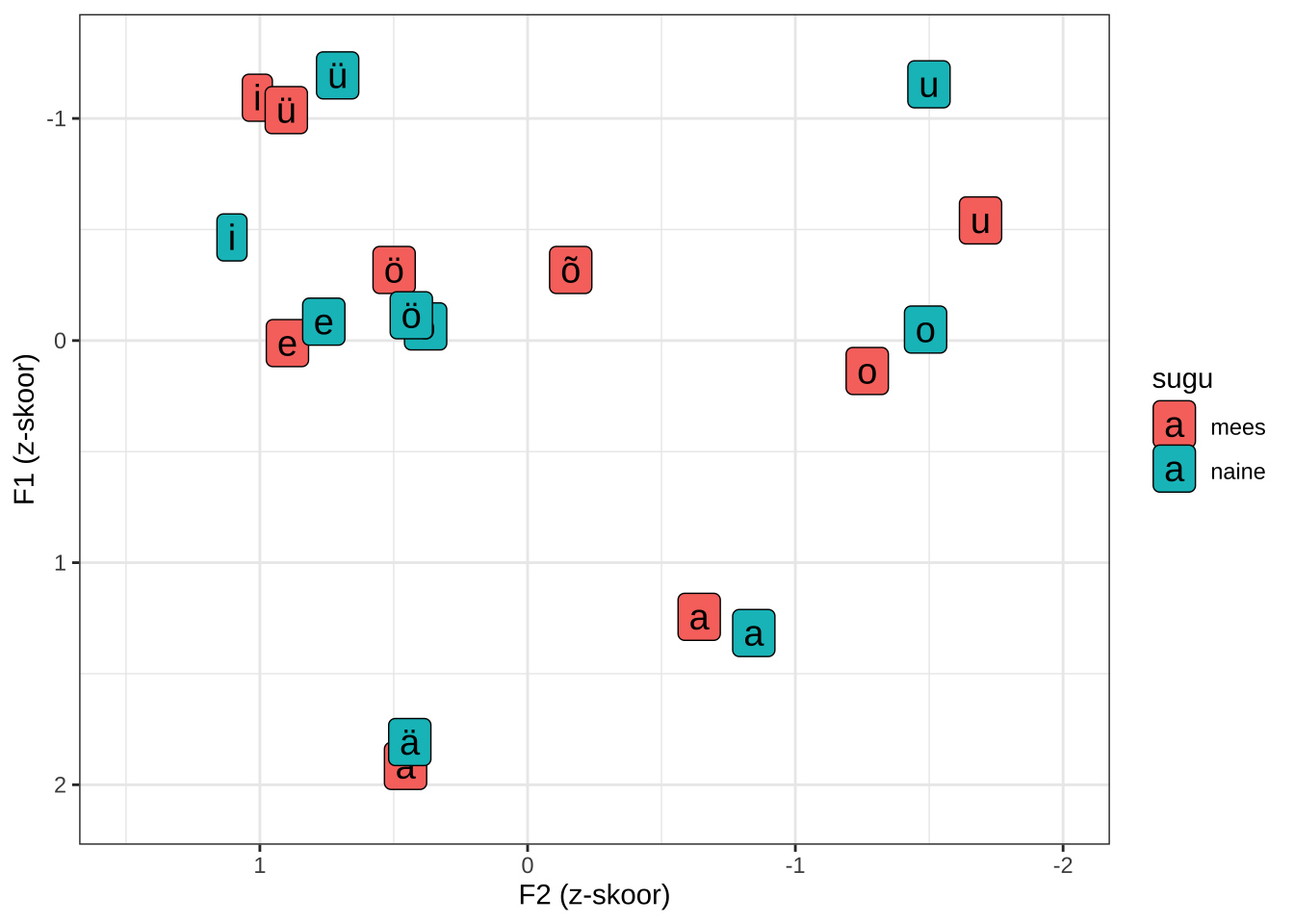
Joonis 9.9: Normaliseeritud vokaalid F1-F2 ruumis.
Jooniselt 9.9 näeme, et mees- ja naiskõneleja vokaalid on nüüd paremini kohakuti, kuigi mitte päris kõik vokaalid. Enam-vähem samas kohas paiknevad /a, ä, o, e, ö, ü/. Meeskõneleja /u/ on naiskõneleja omast madalam, naiskõneleja /i/ on jällegi meeskõneeleja omast madalam.
NB! Siin tabelis 9.3 (ja peatükis üldiselt) esitatud formantandmete hindamisel peab arvestama ka seda, et need on üksikud hääldusjuhud. Formantanalüüsi põhjal vokaalide kvaliteedi kirjeldamine on kvantitatiivne ja et üldistada üle üksikute kõnelejate üksikute hääldusjuhtude, peaks tegema rohkem mõõtmisi erinevate keelejuhtide ja korduvate hääldusjuhtudega ning hindama saadud tulemusi statistiliste meetoditega. Erinevates uurimustes kogutud eesti keele vokaalide formantväärtuste koondtabeli leiab näiteks “Eesti keele häälduse” tervikkäsitlusest (Asu et al. 2016: 31).
9.5 Vokaali kvantiteet
Peale vokaali kvaliteedi (mida hinnatakse formantväärtuste järgi ja sõltub moodustuskohast), on häälikute puhul oluline ka kvantiteet, mida hinnatakse kestuse järgi ja tajutakse pikkusena. Tavaliselt eristatakse lühikesi ja pikki häälikuid, kuid see sõltub keele fonoloogilisest süsteemist. On keeli, kus ei ole pikkuskategooriat ning kestuse varieerumine on seotud ainult rõhu ja kõnetempoga. Tavaliselt, kui keeles on pikkuskategooria, siis on see binaarne (st häälik võib olla kas lühike või pikk) ja puudutab kas ainult vokaale või konsonante. Küllaltki levinud on ka süsteem, kus lühikesele vokaalile järgneb pikk konsonant ja pikale vokaalile lühike konsonant.
Eesti keeles võib olla rõhulises silbis vokaal lühike, pikk või ülipikk, rõhutus silbis poolpikk, lühike ja vaeglühike. Kui konkreetsed väärtused (mida tavaliselt mõõdetakse millisekundites; 1 ms = 0,001 s) sõltuvad kõneleja kõnetempost, siis lühikeste ja pikkade vahe on tavaliselt proportsionaalne. Eesti keele vältest tuleb pikemalt juttu peatükis 13.6.
Vokaali kvantiteet mõjutab kvaliteeti: lühemad vokaalid on tavaliselt hääldatuv väiksema pingega, seetõttu ka lähenevad rohkem vokaaliruumi keskkohale, samas kui pikemad vokaalid lähenevad vokaaliruumi äärtele. See, kas eristatakse rohkem kvantiteedierinevusi või kvaliteedierinevusi, sõltub keele fonoloogilisest süsteemist. Näiteks inglise keeles ei eristata lühikesi ja pikki vokaale, erineva pikkuse ja kvaliteediga vokaale sõnades ship ja sheep peetakse erinevateks vokaalideks. Eesti keeles jällegi peetaks sarnast vastandust sama vokaali erinevaks pikkuseks.
Aga et asi veel keerulisem oleks, siis kõiki häälikuid iseloomustab ka omakestus, st fonoloogiliselt sama pikad häälikud on sõltuvalt häälikust erineva kestusega, mis on tingitud moodustuskoha iseärasustest. Näiteks kõrged vokaalid on enamasti lühemad kui madalad, sest madalate vokaalide hääldamiseks peab suud rohkem avama ja see võtab aega.